![[EECS498/598] lecture 07: Convolutional Networks(CNN)](https://raw.githubusercontent.com/LeoJeshua/PicGo/main/images/20241227205140.png)
[EECS498/598] lecture 07: Convolutional Networks(CNN)
lecture 7: Convolutional Networks(CNN)
slide: https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture07.pdf
- Convolution
- Pooling
- Batch Normalization
Components of a CNN: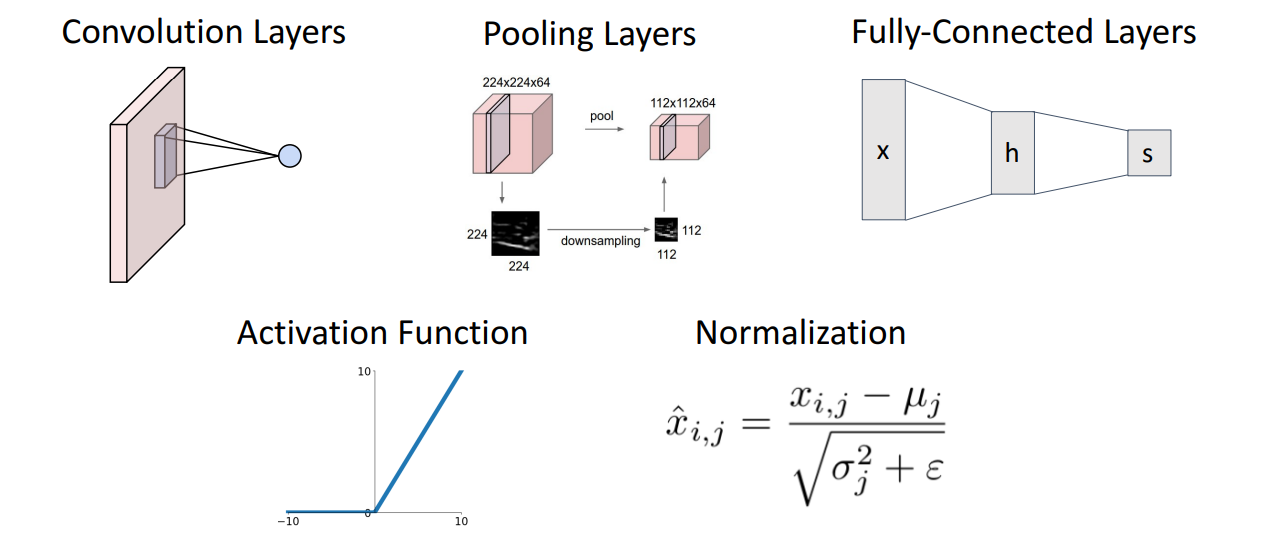
7.1 Fully-Connected Layer
在卷积神经网络(CNN)出现之前,人们将图片flatten成一维向量,然后使用全连接神经网络(FCN)进行图像分类。
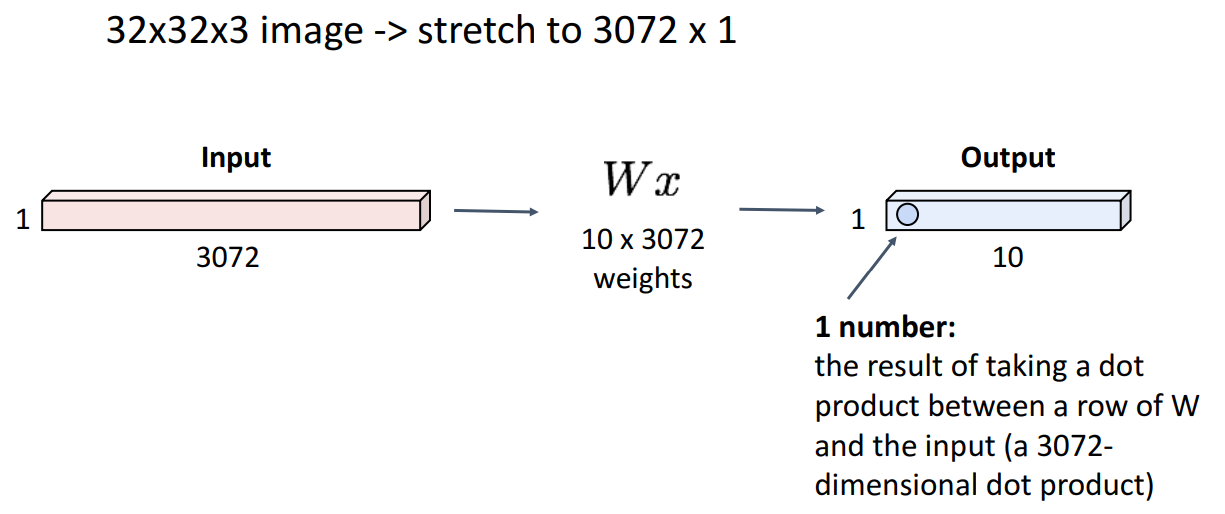
缺点:
- 计算量大,参数量多,容易过拟合
- 无法捕捉到图像的空间特征
7.2 Convolution Layer
借鉴人眼 感受野(Receptive Fields) 的概念,使用卷积核(filter)对input image进行卷积操作,得到特征提取的结果。
卷积层的目的:提取input image的特定特征(如边缘、形状、纹理等)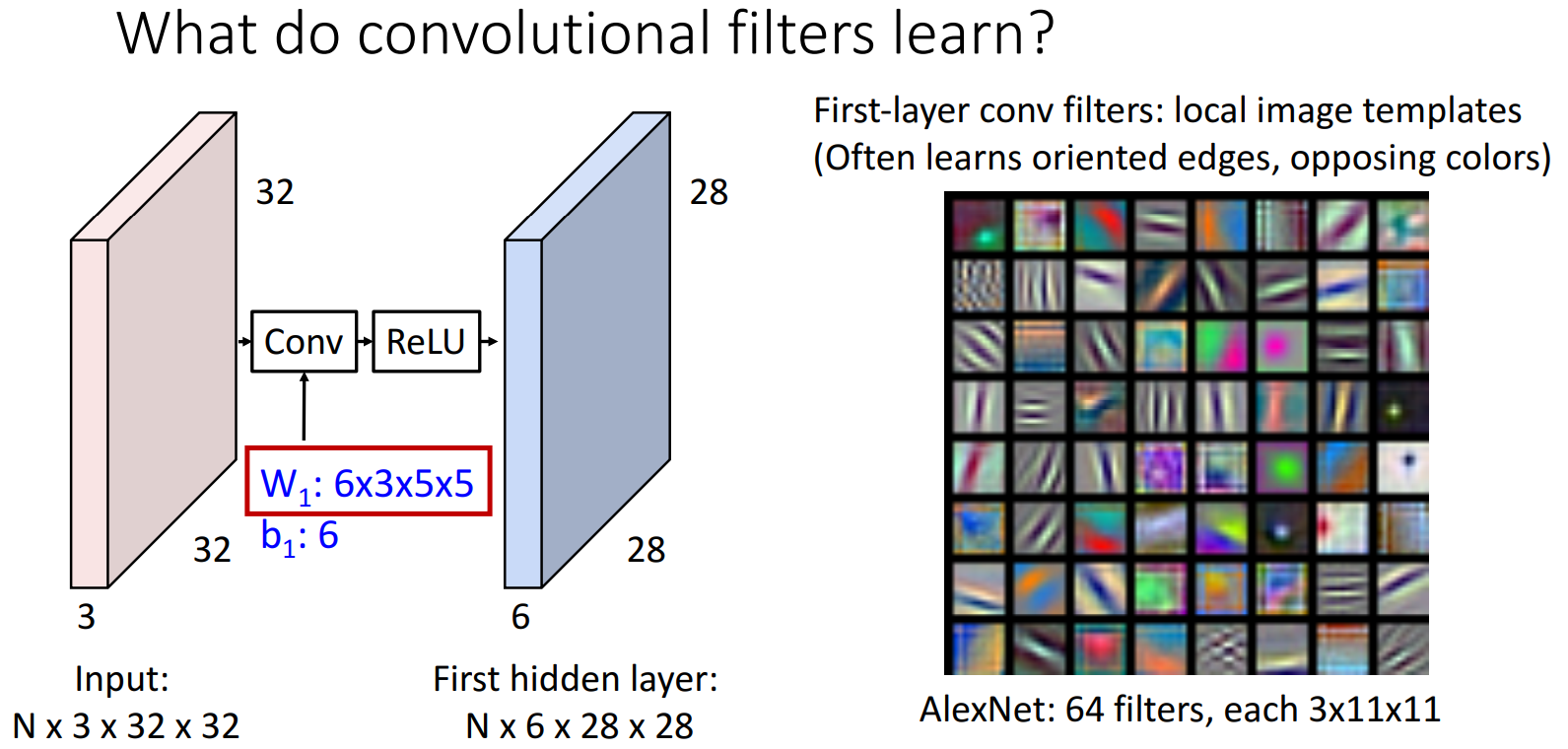
7.2.1 卷积核 (filter)
filter的深度(通道数) = input image的深度(通道数)

7.2.2 卷积操作 (Convolve)
filter * input image上对应chunk + bias = 卷积结果(特征图/激活图上的一个点)。
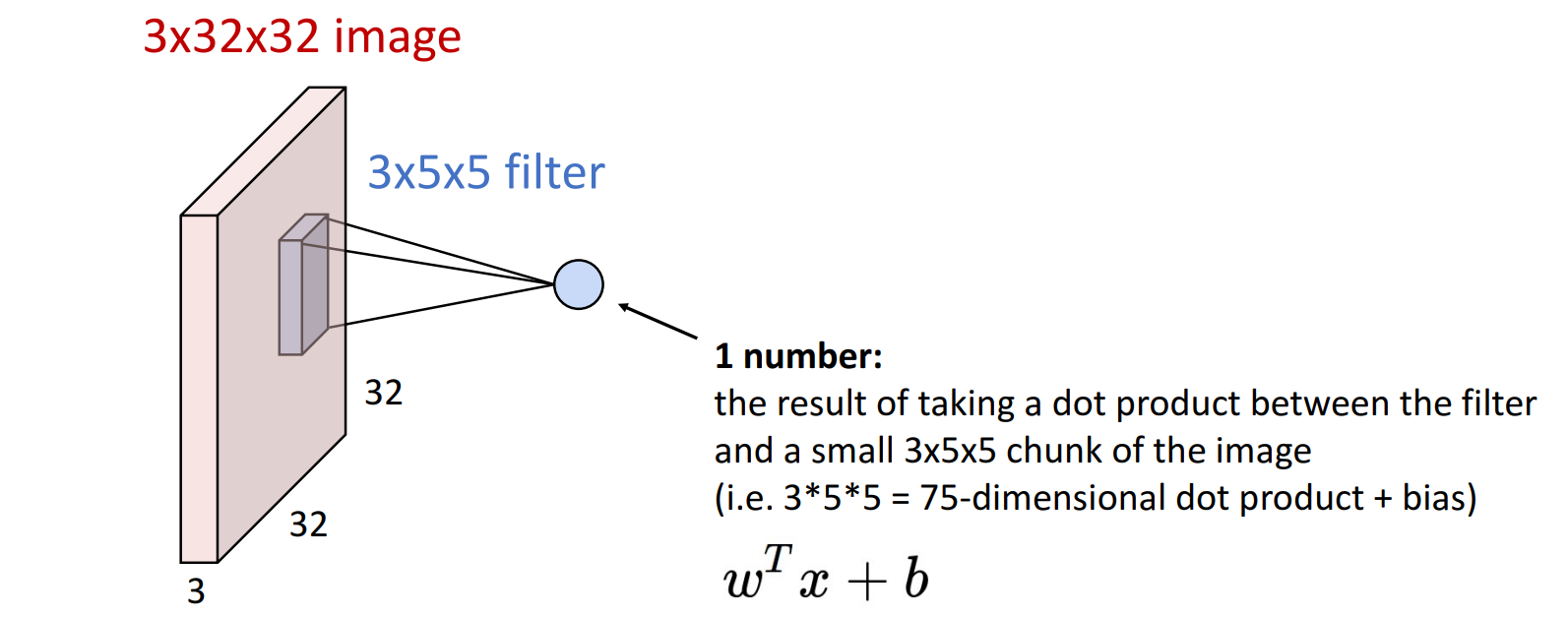
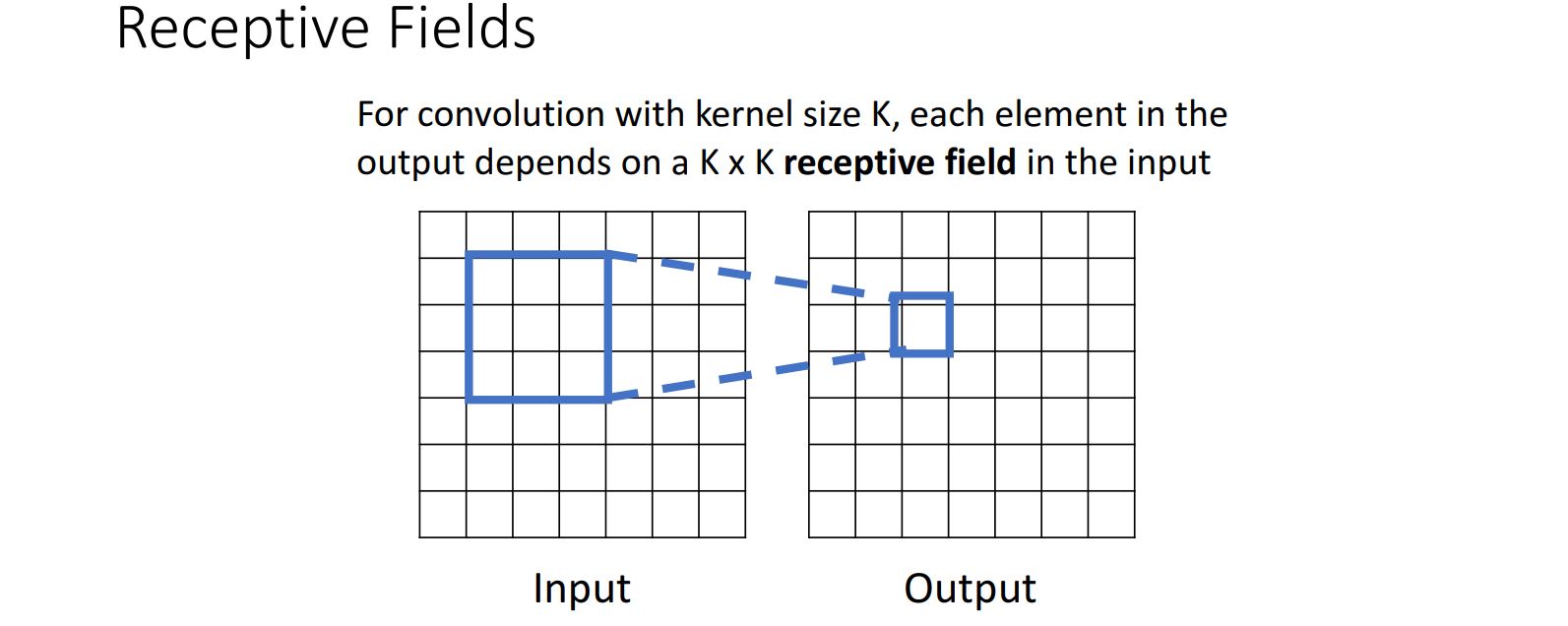
- 卷积结果表示 该chunk与filter的匹配程度,值越大表示匹配程度越高
- 后面的图示中通常会省略bias,但 计算中不要忘记bias项
边缘填充 (Padding)
在进行卷积操作时,边缘像素块没有得到很好的利用
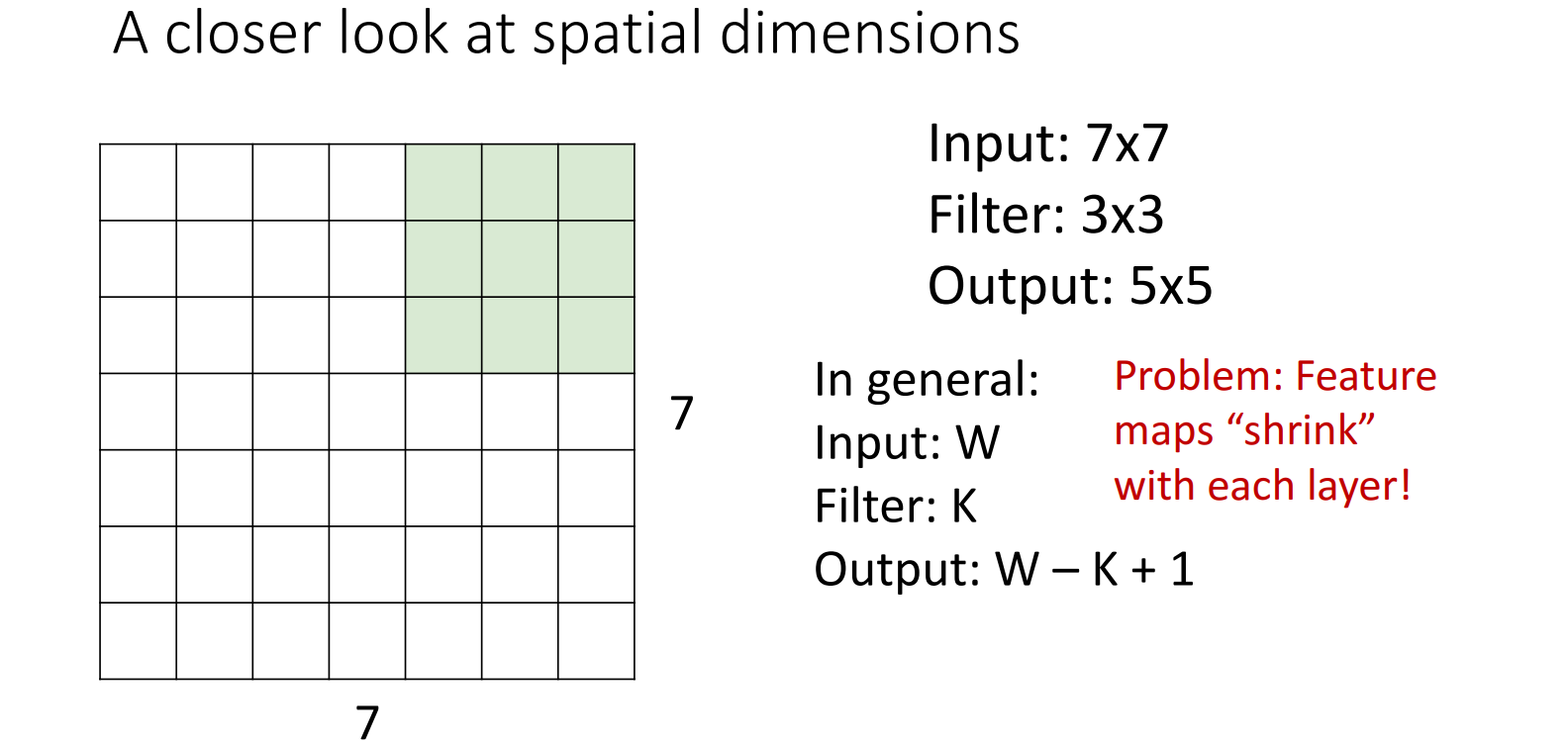
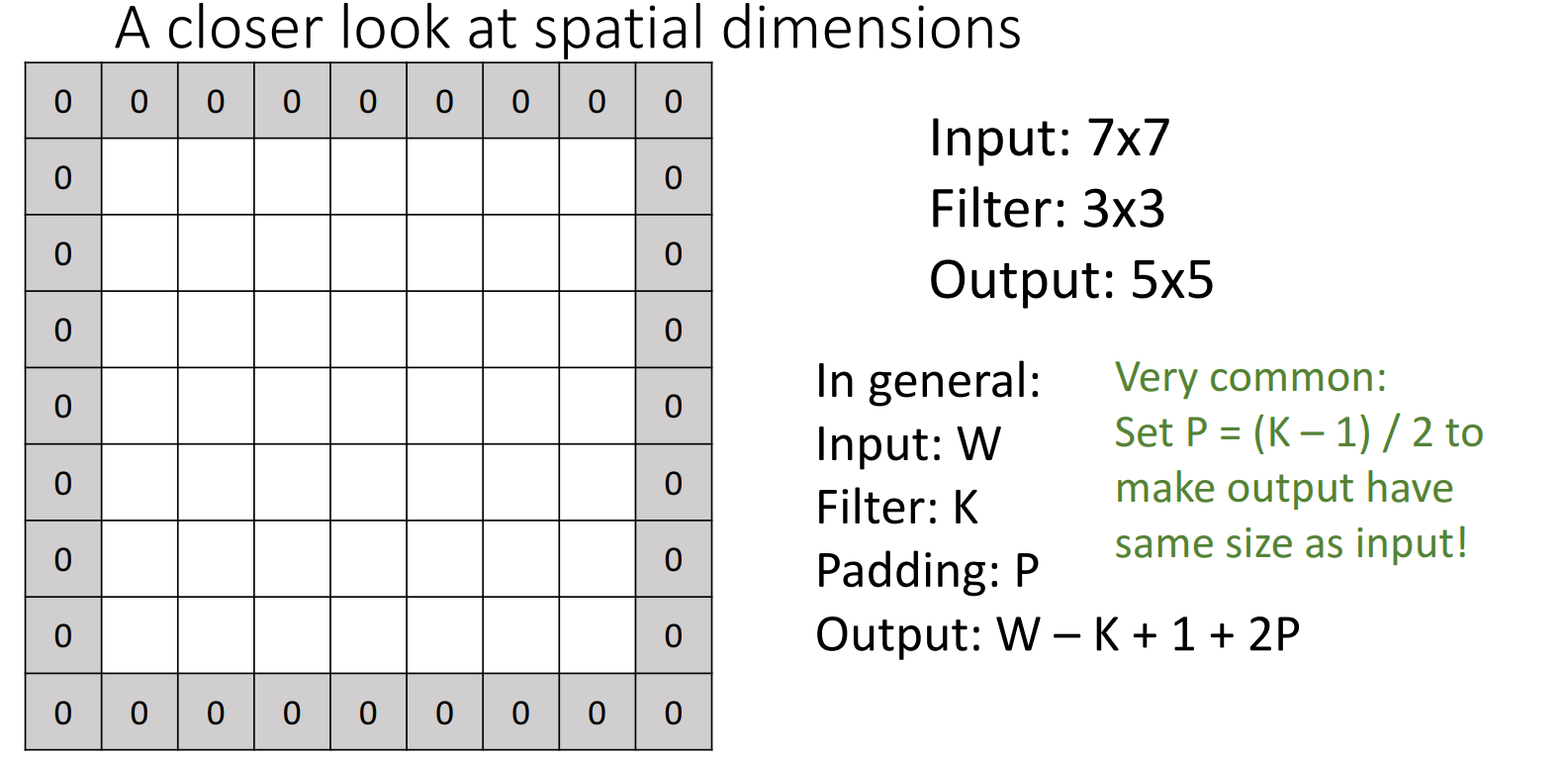
解决方法:在边缘填充0 (zero-padding),使得卷积操作可以覆盖到边缘像素块。
填充像素的大小P = (卷积核的大小K - 1) / 2
eg: 3x3卷积核(K=3) -> 填充像素大小P=(3-1)/2=1
跨步卷积 (Strided Convolution)
单步卷积的问题:
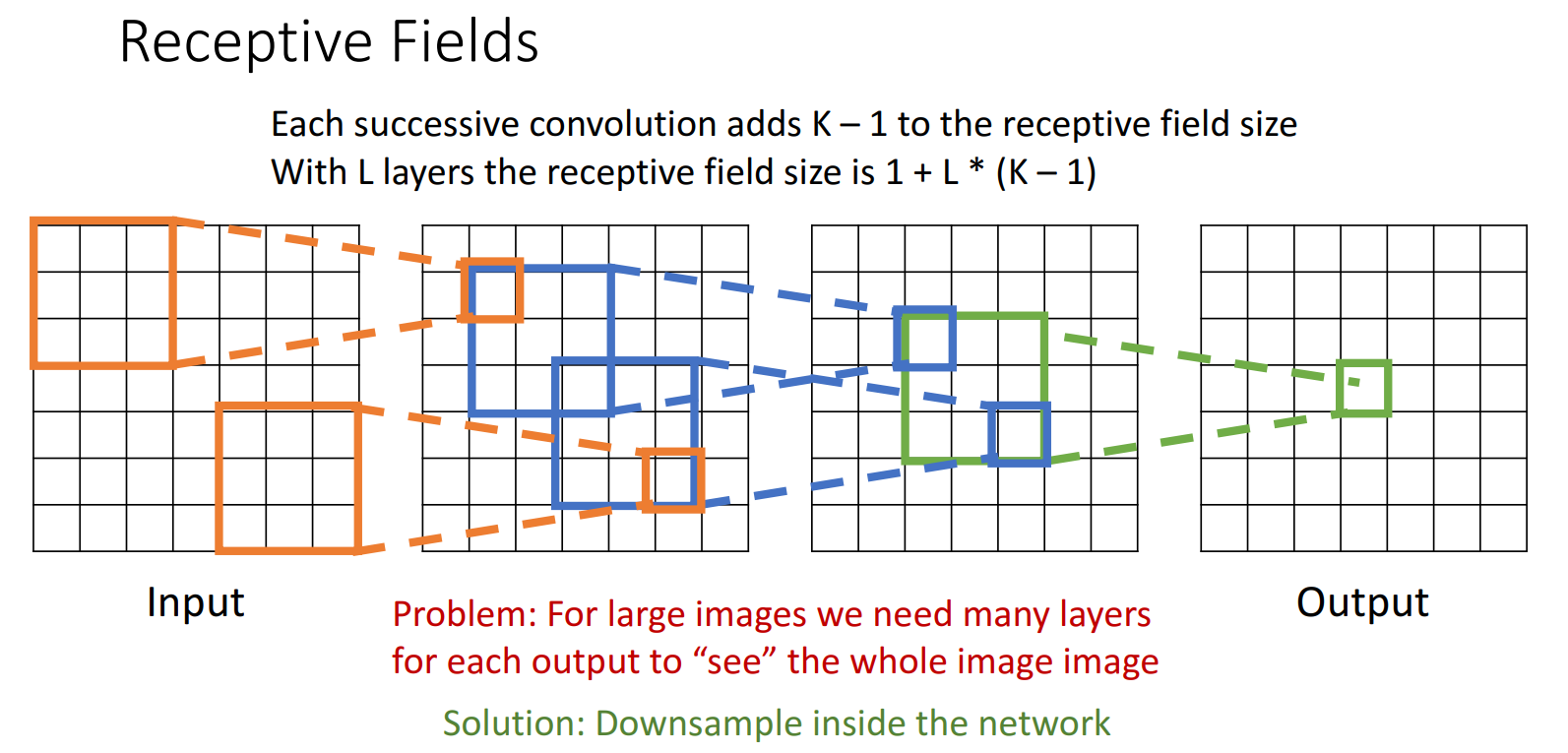
- 对于大图像,我们需要很多卷积层才能“看到”整个图像
- 计算量大
解决方案:下采样(Downsampling) ,包括各种使spatial size减小的方法,如跨步卷积、池化等。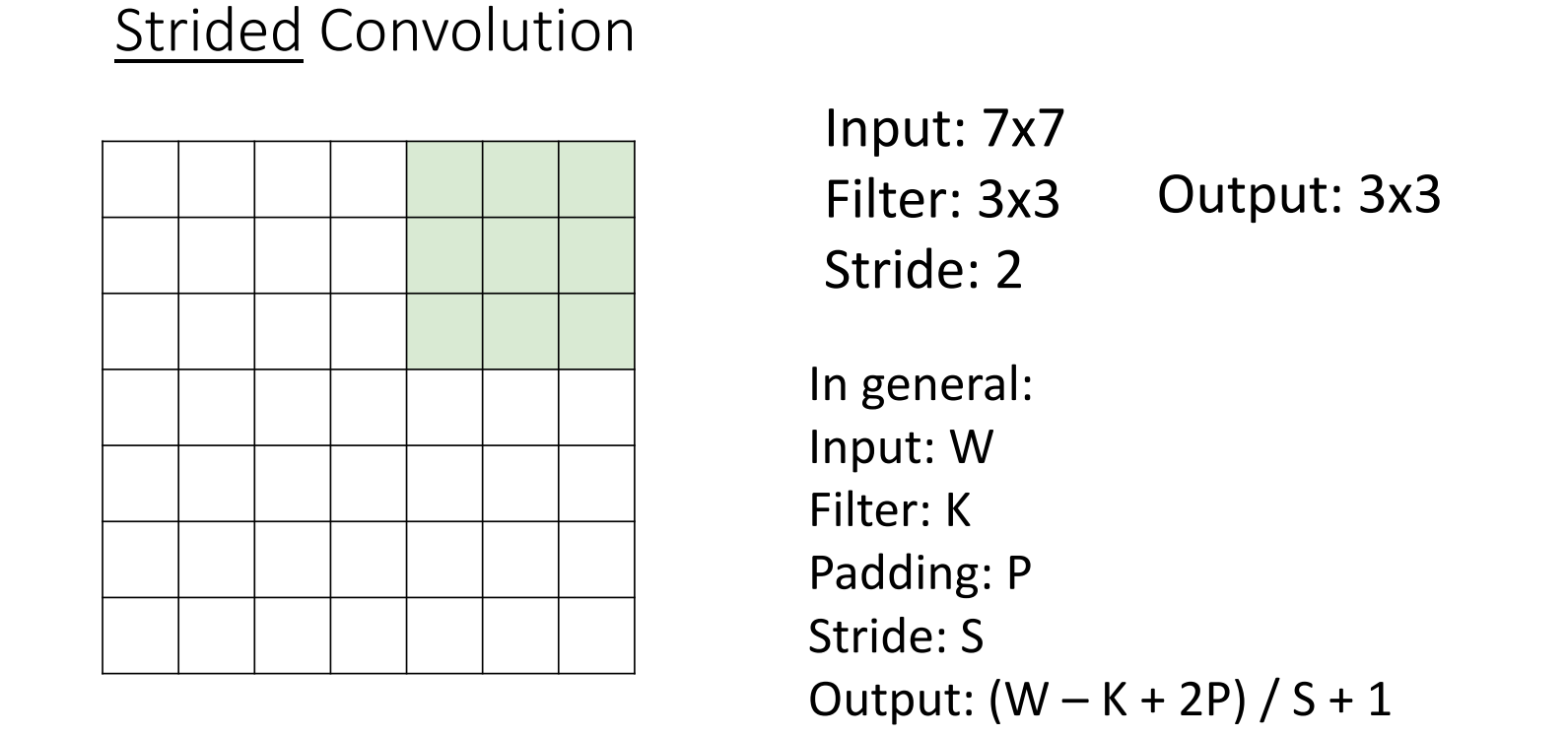
输出图像大小:output_size = (input_size - filter_size + 2*padding) / stride + 1
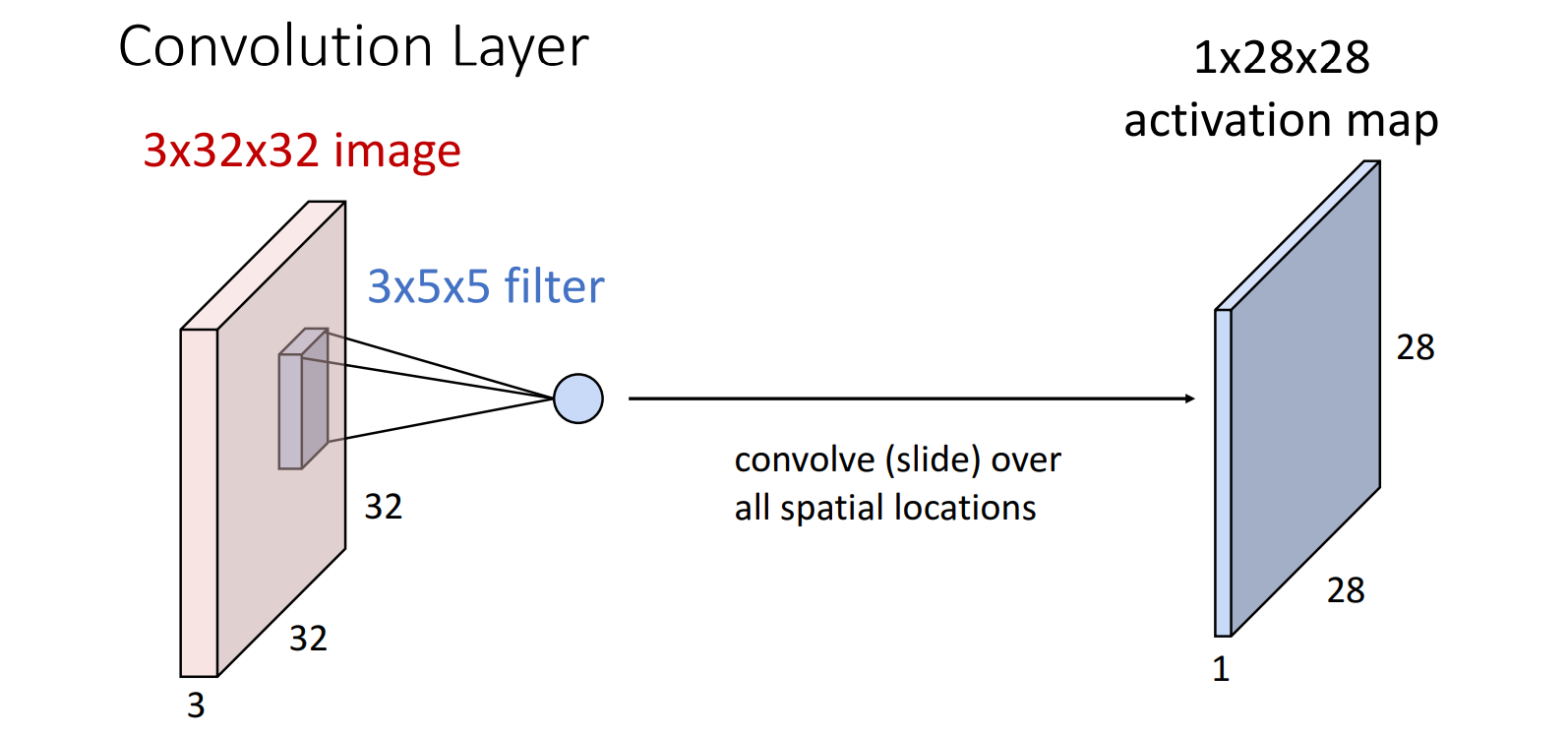
7.2.3 特征图/激活图 (Feature Map/Activation Map)
Feature Map/Activation Map的个数 = filter的个数
使用filter对input image进行卷积操作
-> 得到特征图(feature map)
-> 再经过激活函数得到激活图(activation map)
使用另一个filter进行卷积操作,得到另一张Feature Map/Activation Map。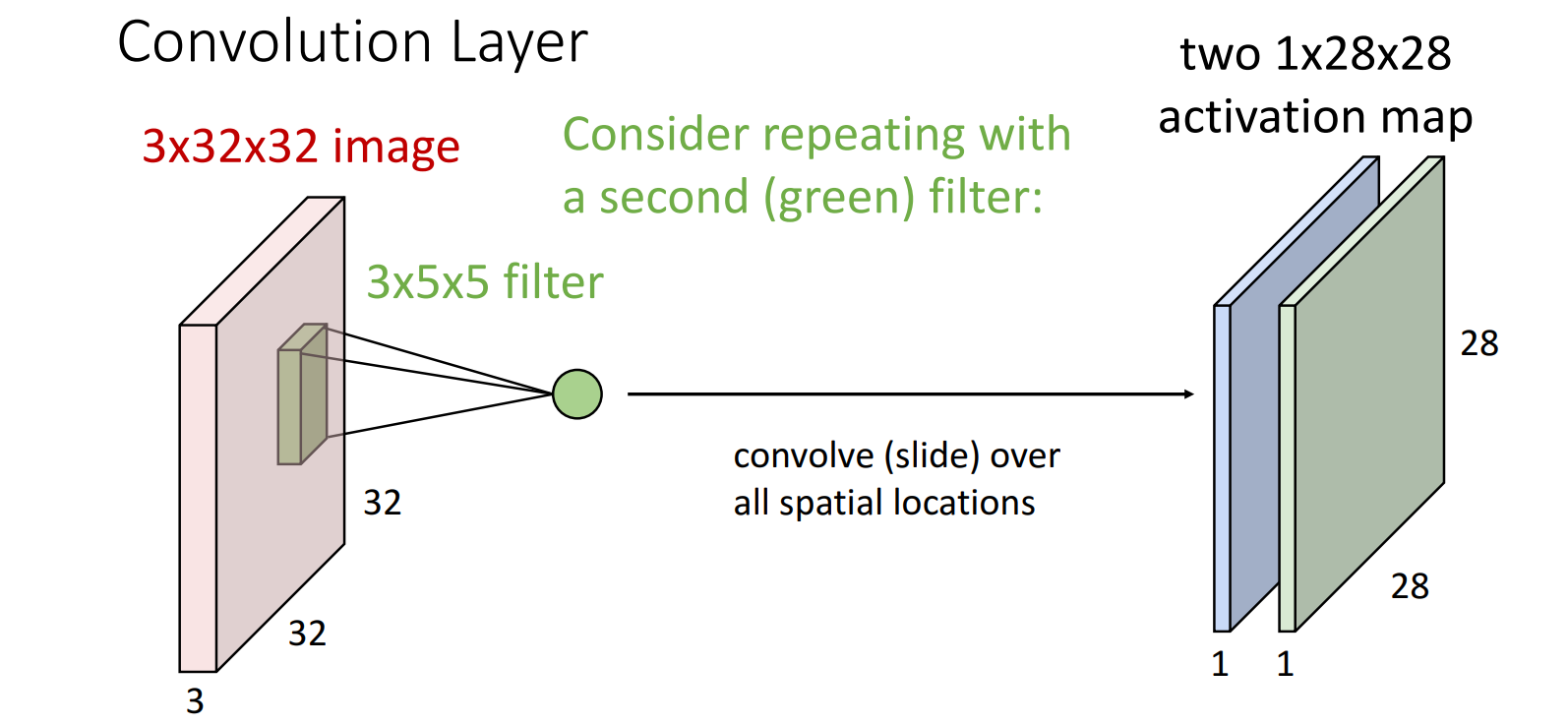
视角1:多个单通道 Feature Map/Activation Map
eg: 6个filter -> 得到 6个 通道数为1的 Feature Map/Activation Map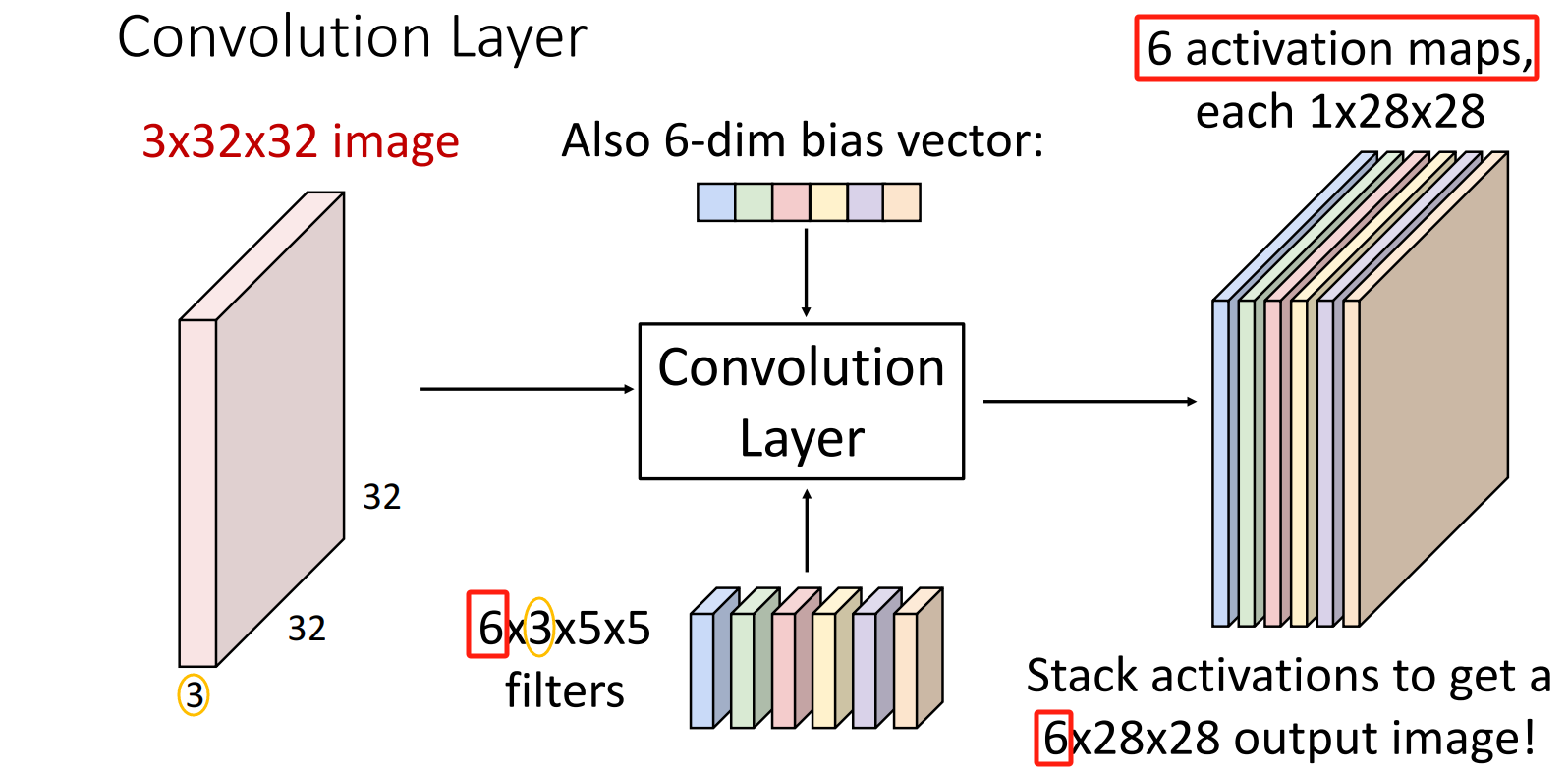
视角2:一个多通道 Feature Map/Activation Map
eg: 6个filter -> 得到 1个 通道数为6的 Feature Map/Activation Map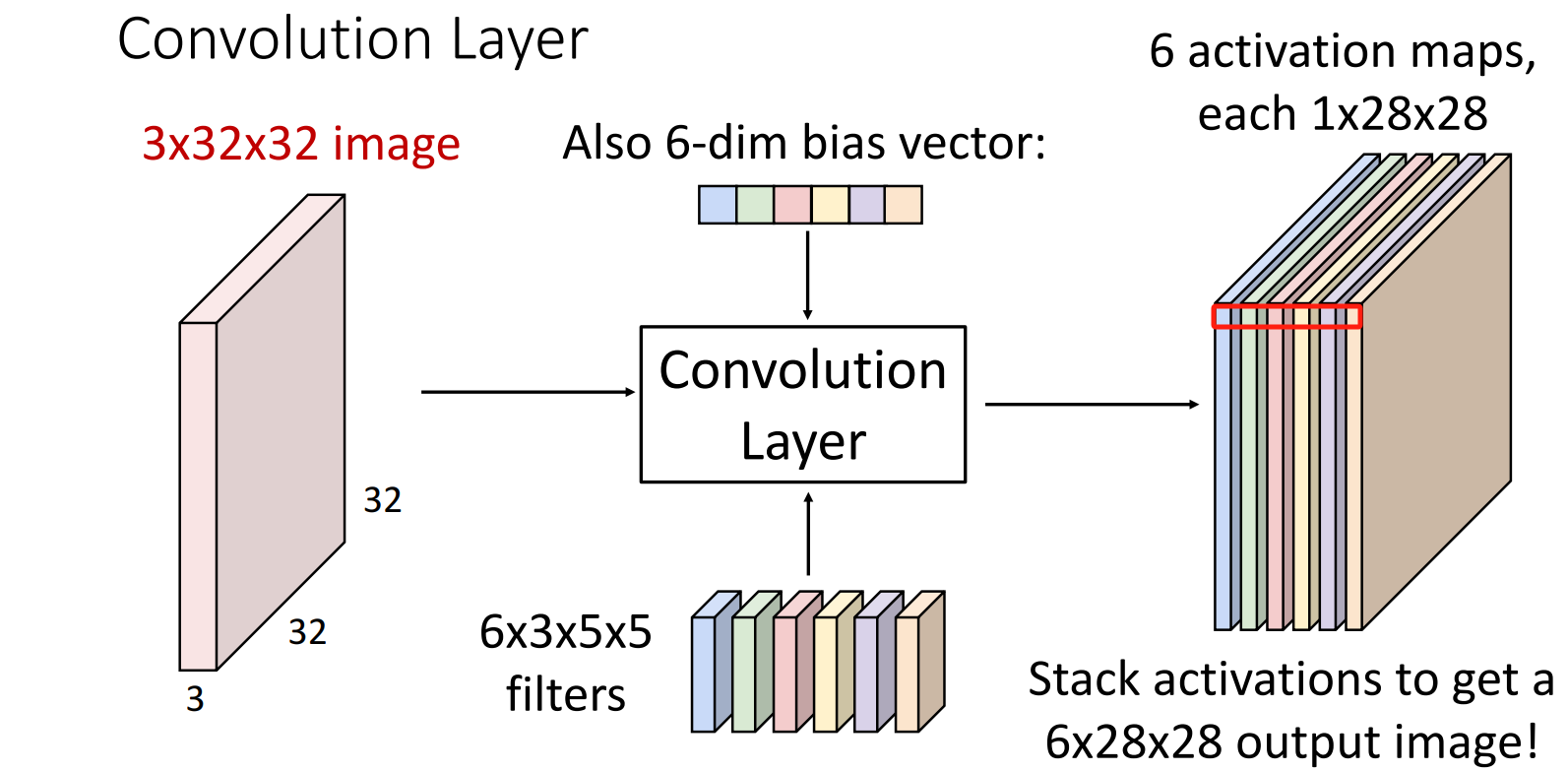
7.2.4 卷积层的训练设置
批量输入
batch_size = N > 1
N张 input image -> 得到 N张 Feature Map/Activation Map
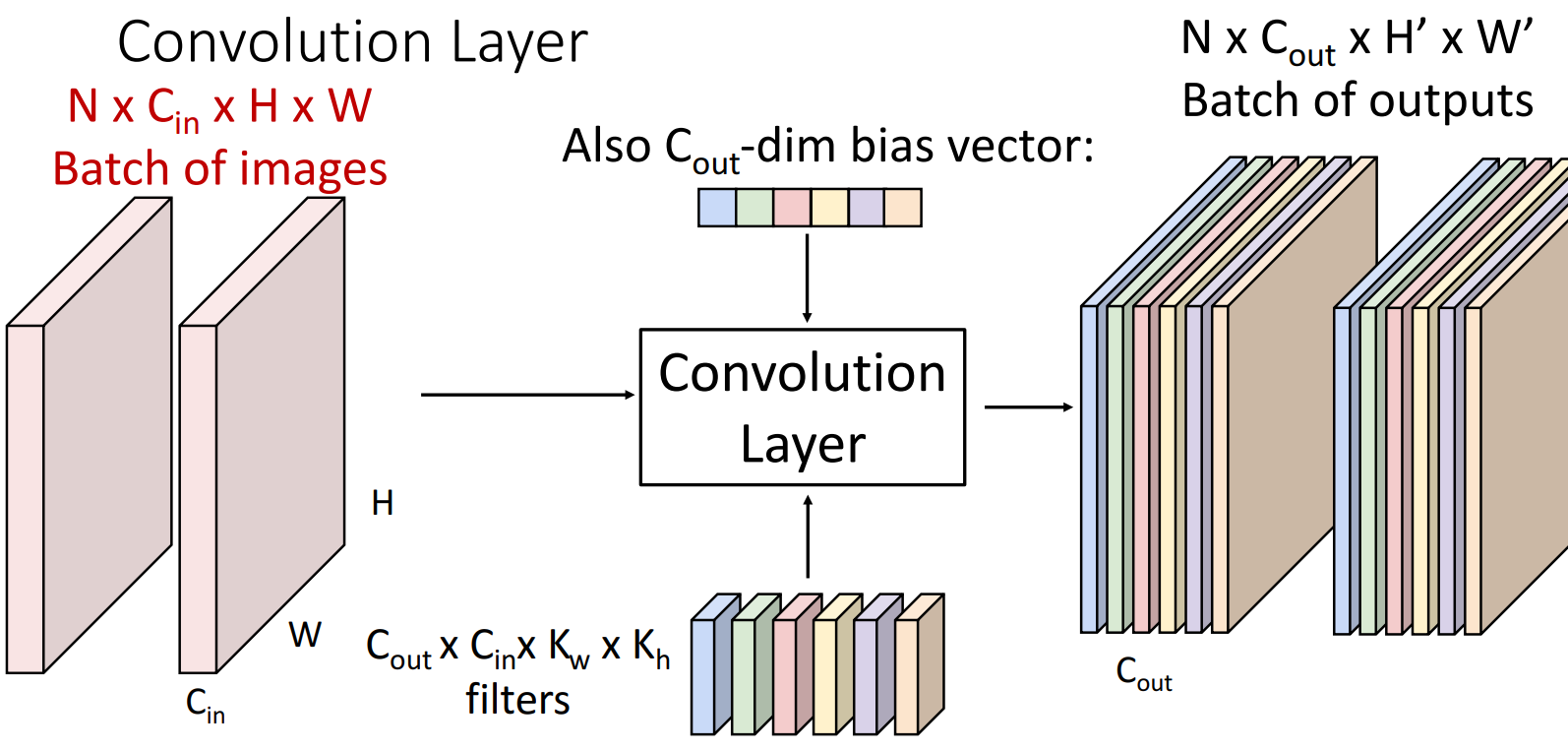
参数量和计算量

超参的一般选择

- 1x1卷积核:改变通道数(不改变spatial size大小)。可以用于降低参数量。
- 跨步卷积:stride > 1,用于下采样。
PyTorch实现
2D卷积
1D和3D卷积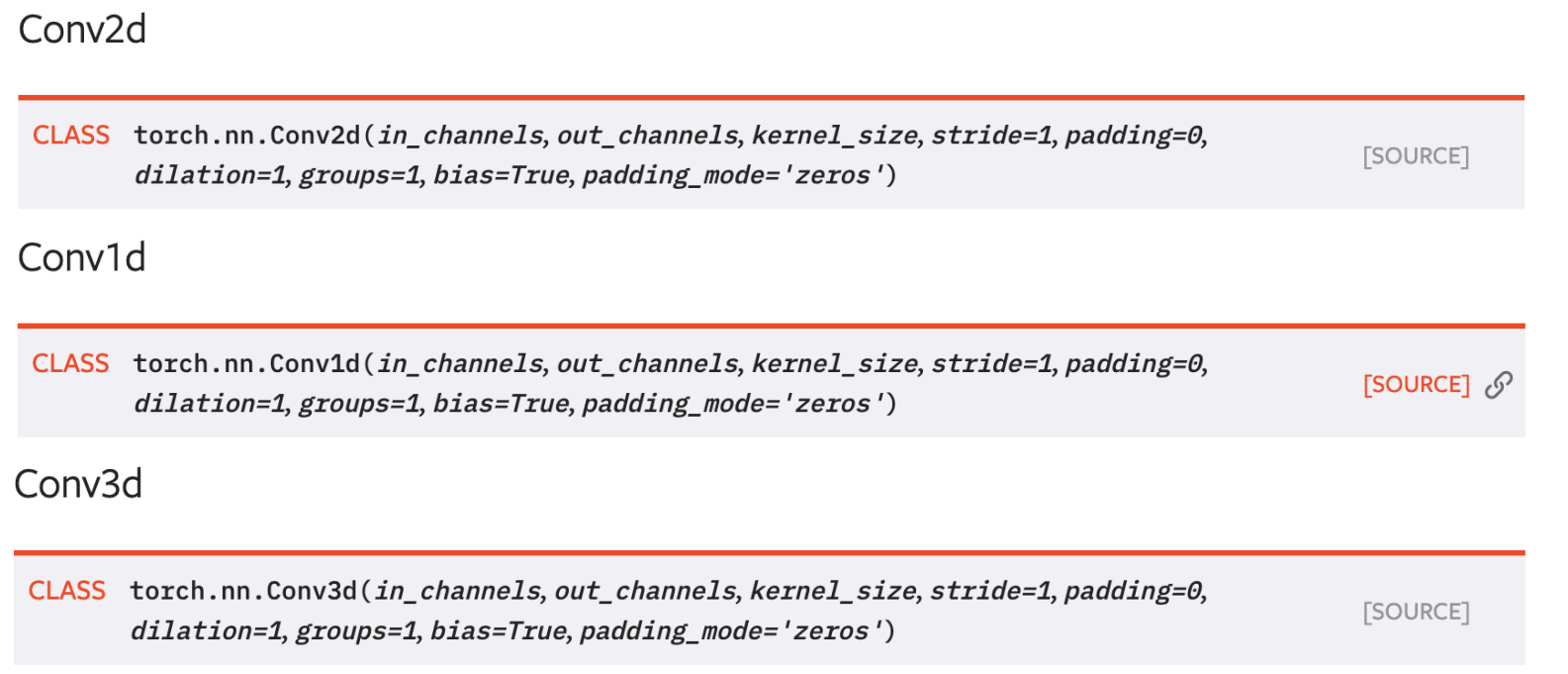
7.2.5 线性卷积层的问题
多个线性卷积层叠加 == 一个线性卷积层
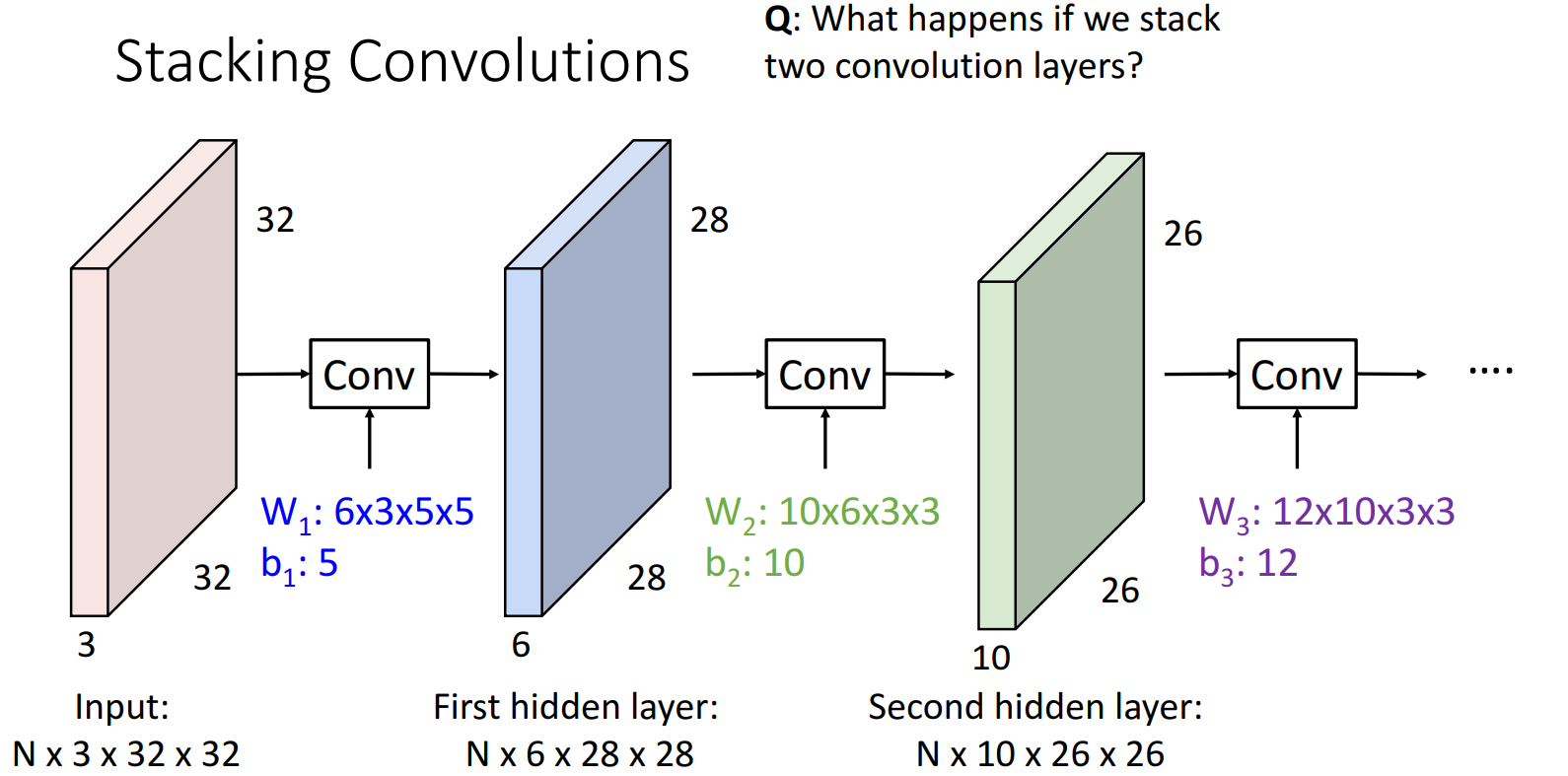
解决思路:和全连接层一样,需要非线性的引入(如Activation Function,Pooling Layer)。
7.3 Activation Function
目的:引入非线性,使神经网络可以学习到更复杂的模式。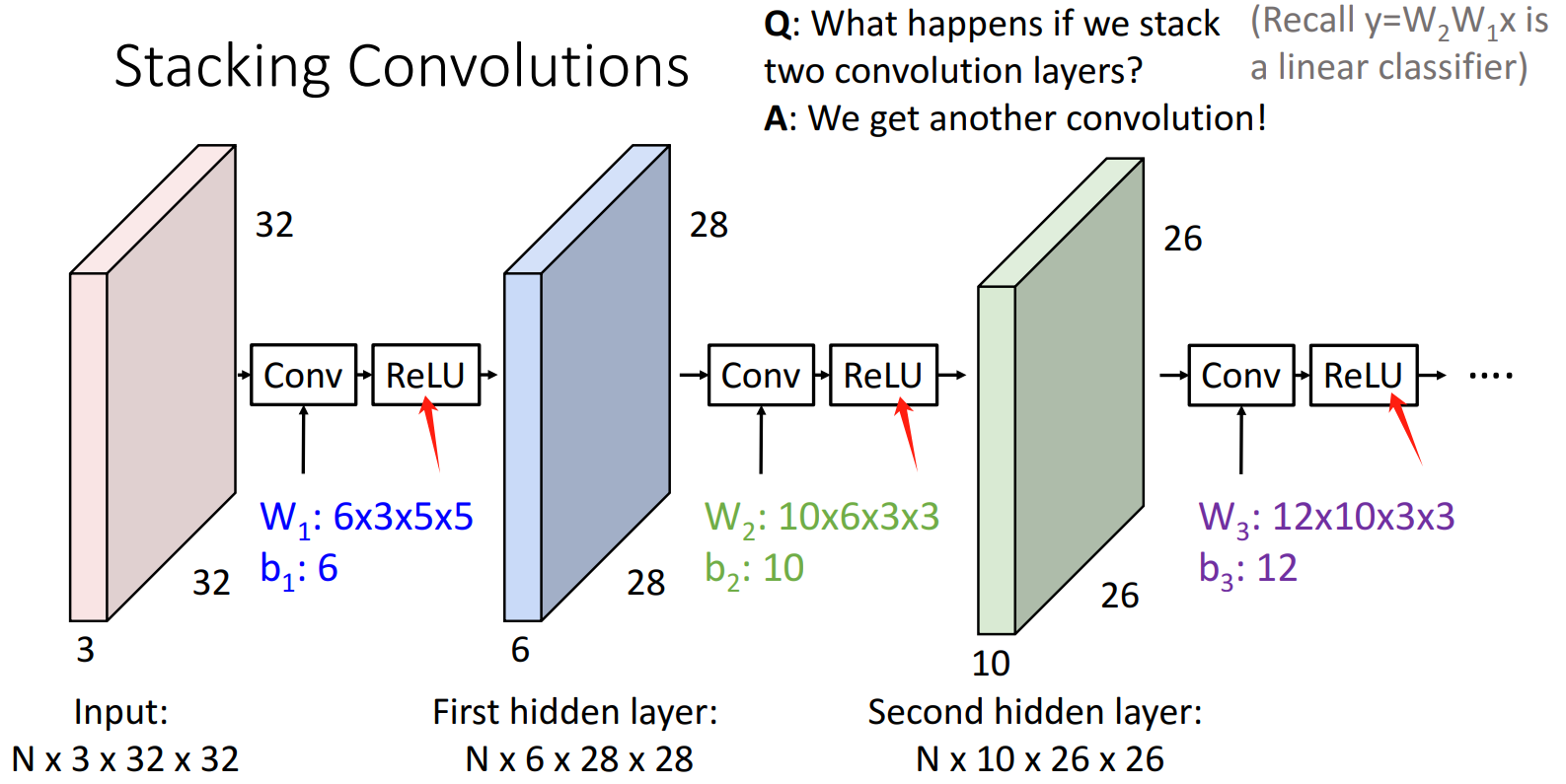
7.4 Pooling Layer
- 下采样的另一种方式,减小参数量
- 同时也能引入非线性
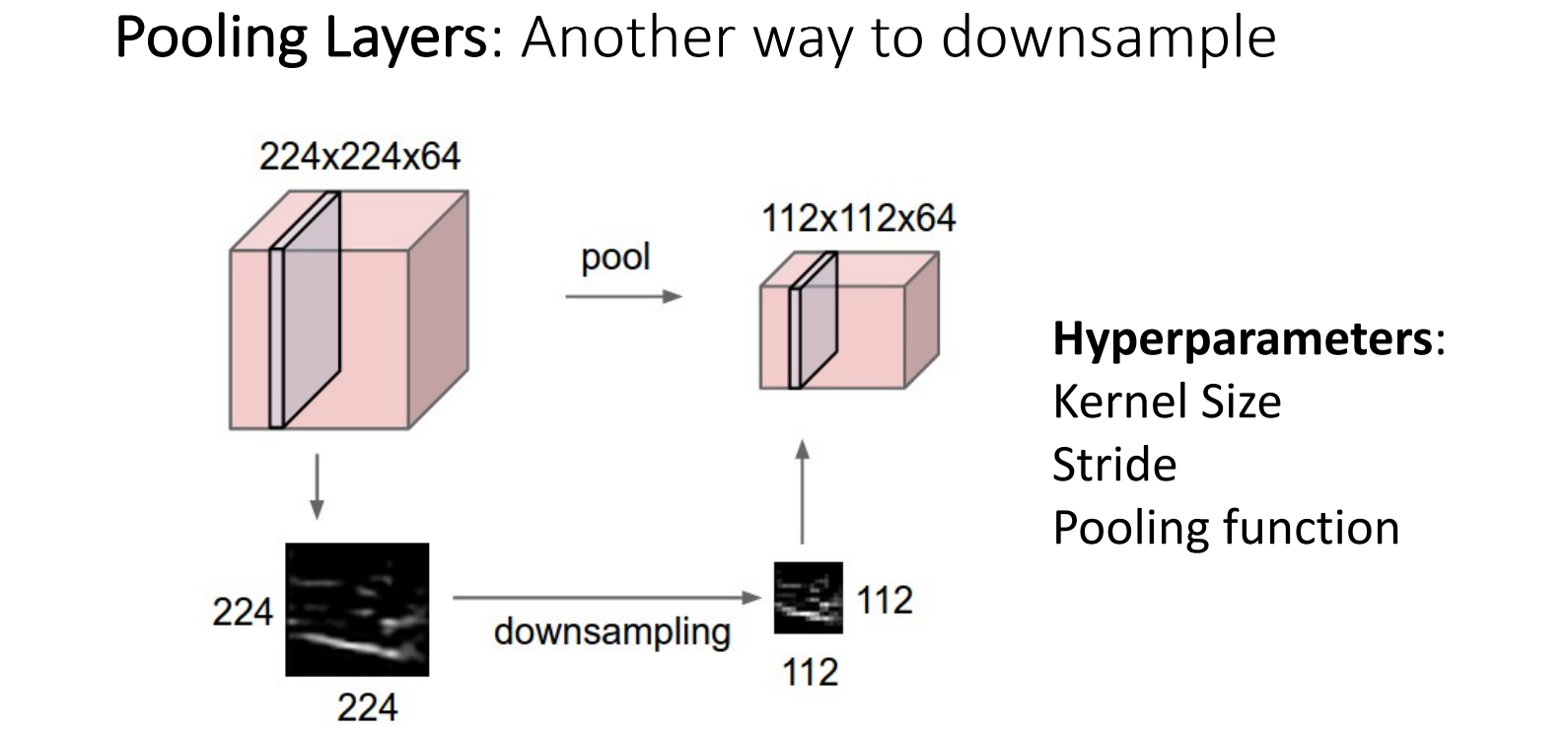
7.4.1 Types of Pooling
Max Pooling:取池化窗口内的最大值
Average Pooling:取池化窗口内的平均值Global Average Pooling:取整个feature map的平均值 (2014年,GoogLeNet提出)
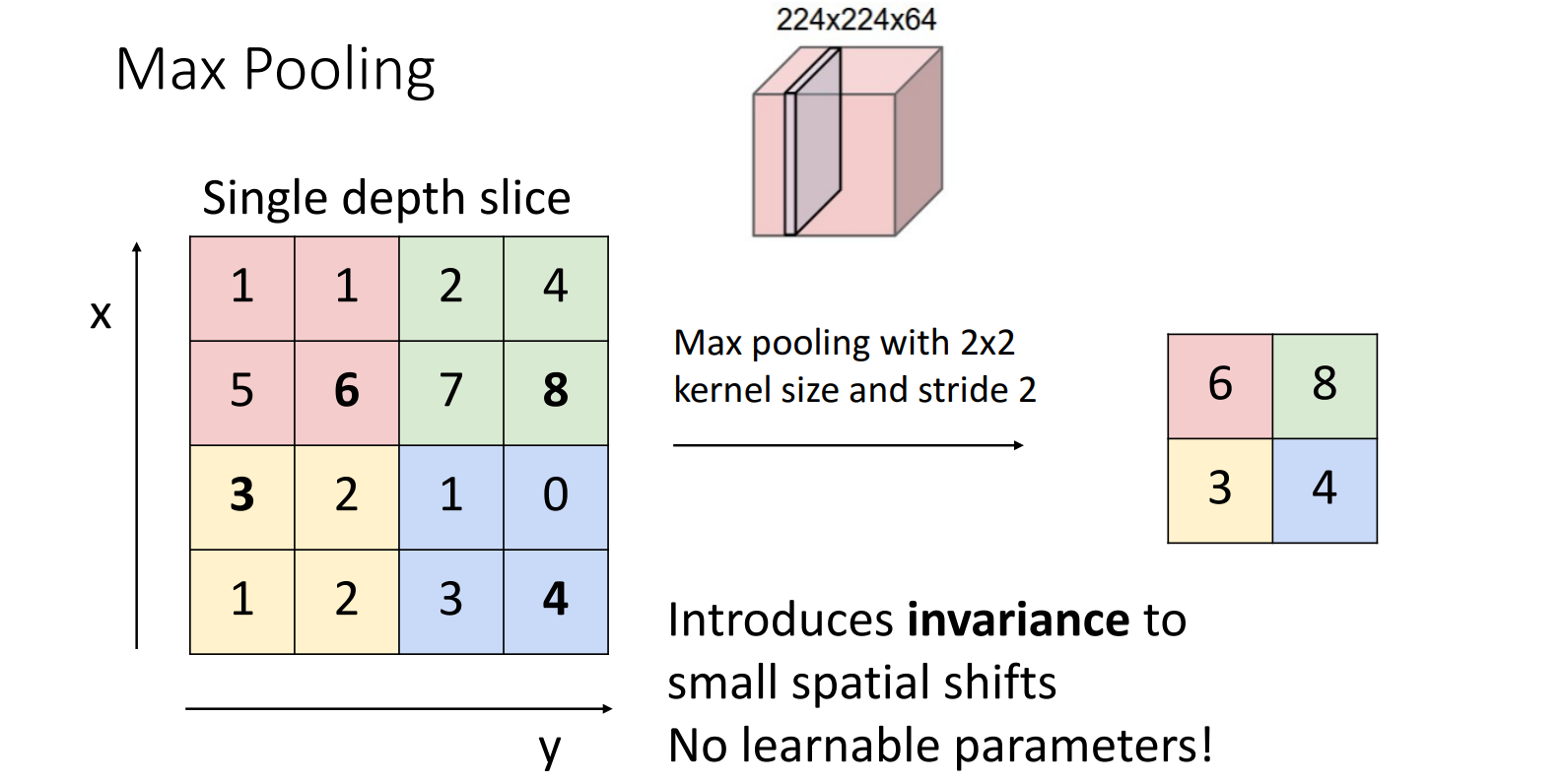
7.4.2 参数量 = 0

7.5 (2015) Normalization
Problem: Deep Networks are very hard to train!
Solution: Normalising the input data (mean 0, variance 1)
- makes the data distribution more consistent
- and speeds up training
Ioffe and Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift”, ICML2015 [link]

Types of Normlization: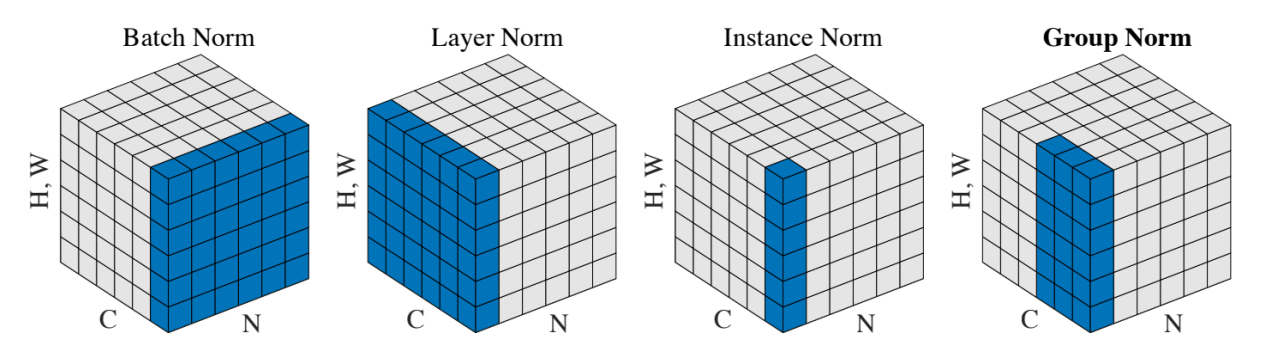
Batch Normalization
对 同一batch的不同图像(size=N) 进行归一化,使得 图像 之间分布一致。
- 归一化输入:对于每一层的输入,Batch Normalization 通过计算小批量的平均值和标准差,将输入标准化为 均值为0、方差为1的分布 。这有助于缓解深层神经网络中的“
内部协变量偏移(internal covariate shift)”问题,从而稳定学习过程。 - 可学习参数:在标准化的基础上,Batch Normalization 引入了两个可学习的参数,即
尺度参数(gamma)和偏移参数(beta)。这允许网络在标准化后能够 恢复适当的表示能力,以便于学习复杂特征。是标准化后的输入,则标准化后的输出可以表达为:


注:在训练和测试时,Batch Normalization的计算方式不同
- 训练时的
和 是根据当前batch计算的 - 而 测试时的
和 是根据训练集计算的固定值


Layer Normalization
对 同一图像的不同通道/层(depth=D) 进行归一化,使得 通道/层 之间分布一致。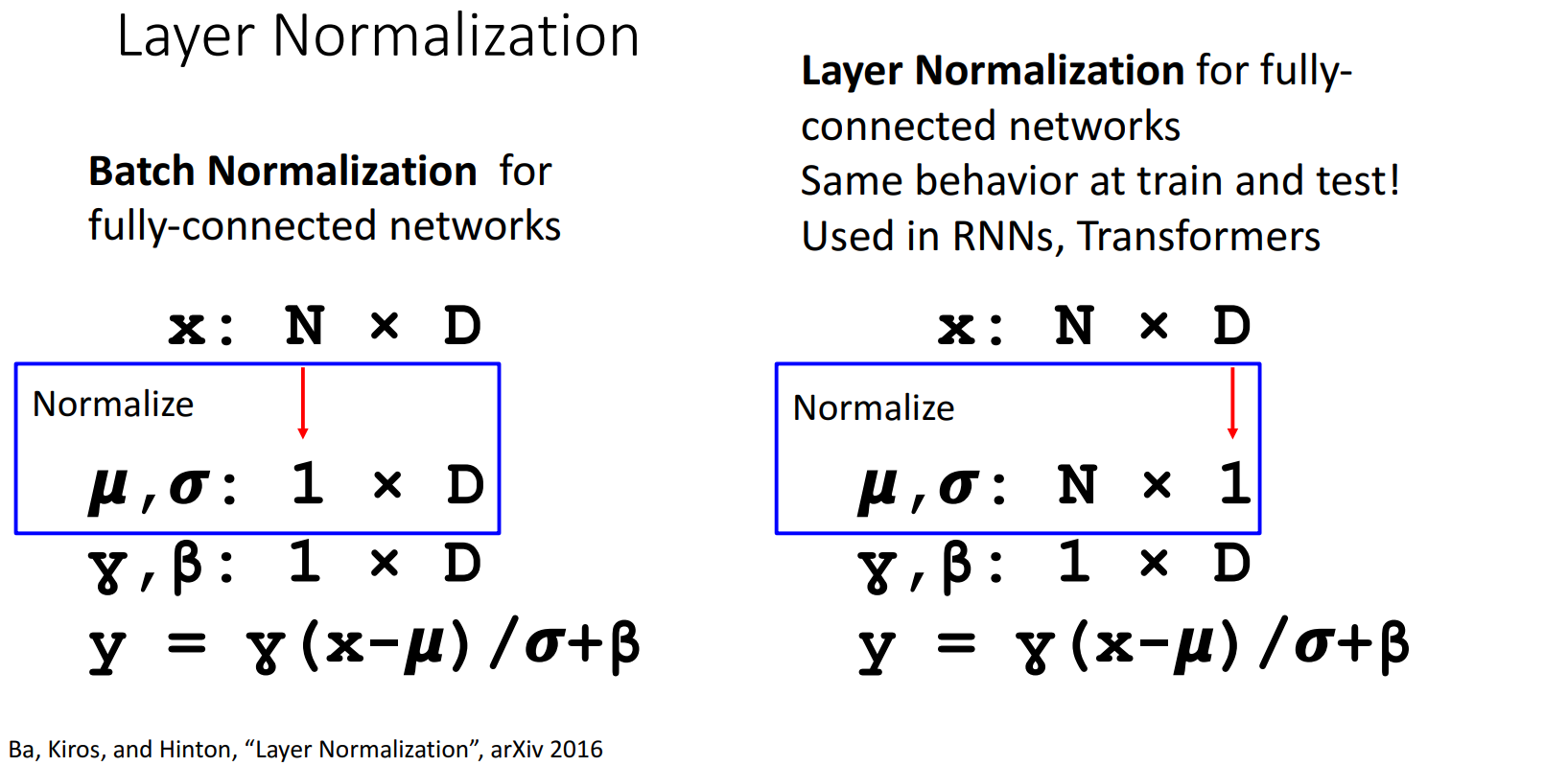
Instance Normalization
对 同一通道/层的不同空间维度(H/W) 进行归一化,使得 空间维度 之间分布一致。
Group Normalization
对 同一图像的多个通道/通道组(group) 进行归一化,使得 通道组 之间分布一致。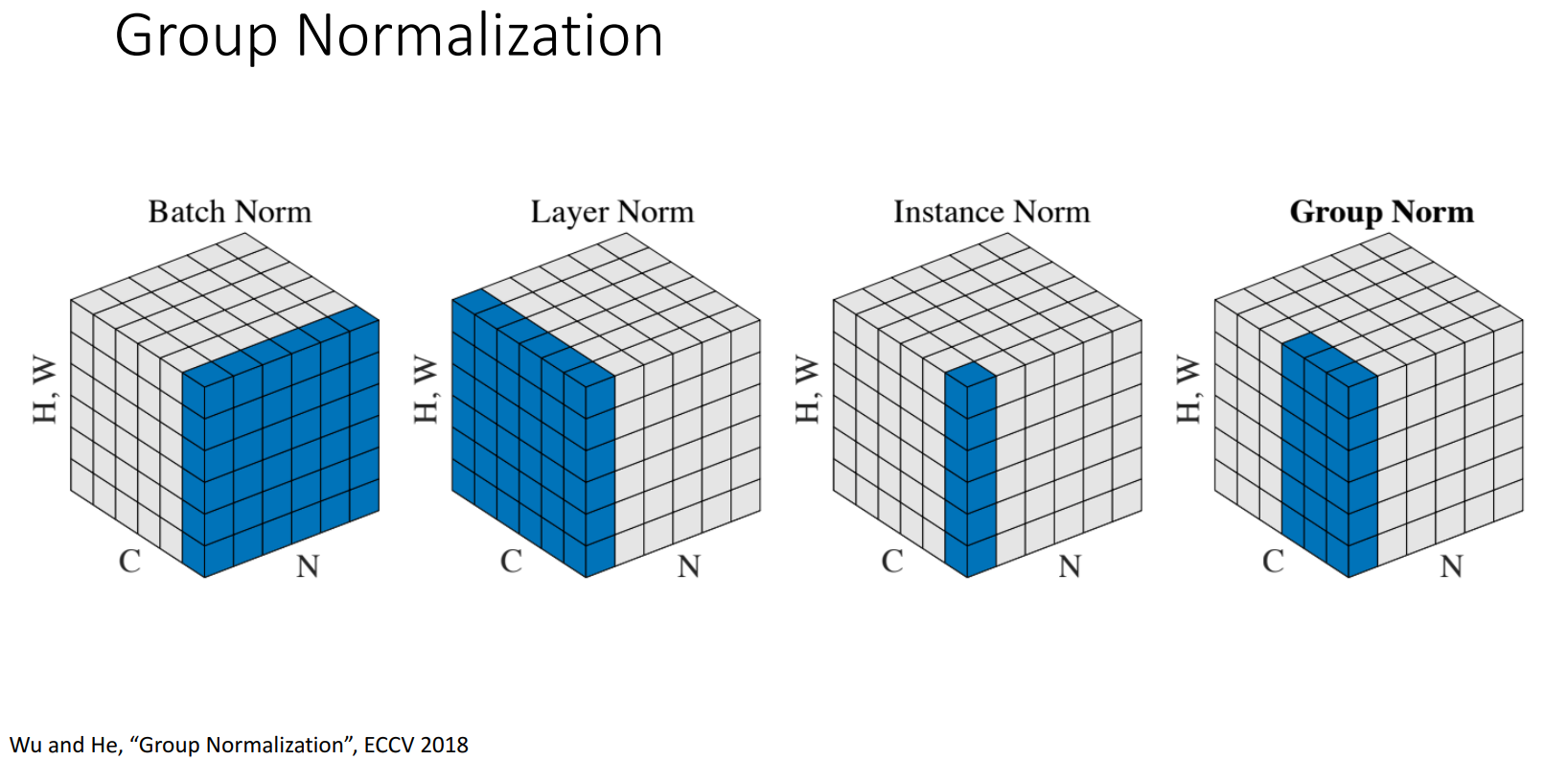
- Title: [EECS498/598] lecture 07: Convolutional Networks(CNN)
- Author: LeoJeshua
- Created at : 2025-01-01 08:07:00
- Updated at : 2025-03-10 20:23:55
- Link: https://leojeshua.github.io/Course/eecs498/eecs498-07/
- License: This work is licensed under CC BY-NC-SA 4.0.