![[EECS498/598] lecture 08: CNN Architectures(CNN经典架构)](https://raw.githubusercontent.com/LeoJeshua/PicGo/main/images/20241227205140.png)
[EECS498/598] lecture 08: CNN Architectures(CNN经典架构)
lecture 8: CNN Architectures(CNN经典架构)
slide: https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture08.pdf
- AlexNet, VGG, ResNet
- Size vs Accuracy
- Grouped and Separable Convolutions
- Neural Architecture Search
Problem: What is the right way to combine all these components?
pretrained models in PyTorch:
- AlexNet: https://pytorch.org/vision/main/models/alexnet.html
- VGG: https://pytorch.org/vision/main/models/vgg.html
- GoogLeNet: https://pytorch.org/vision/main/models/googlenet.html
- ResNet: https://pytorch.org/vision/main/models/resnet.html
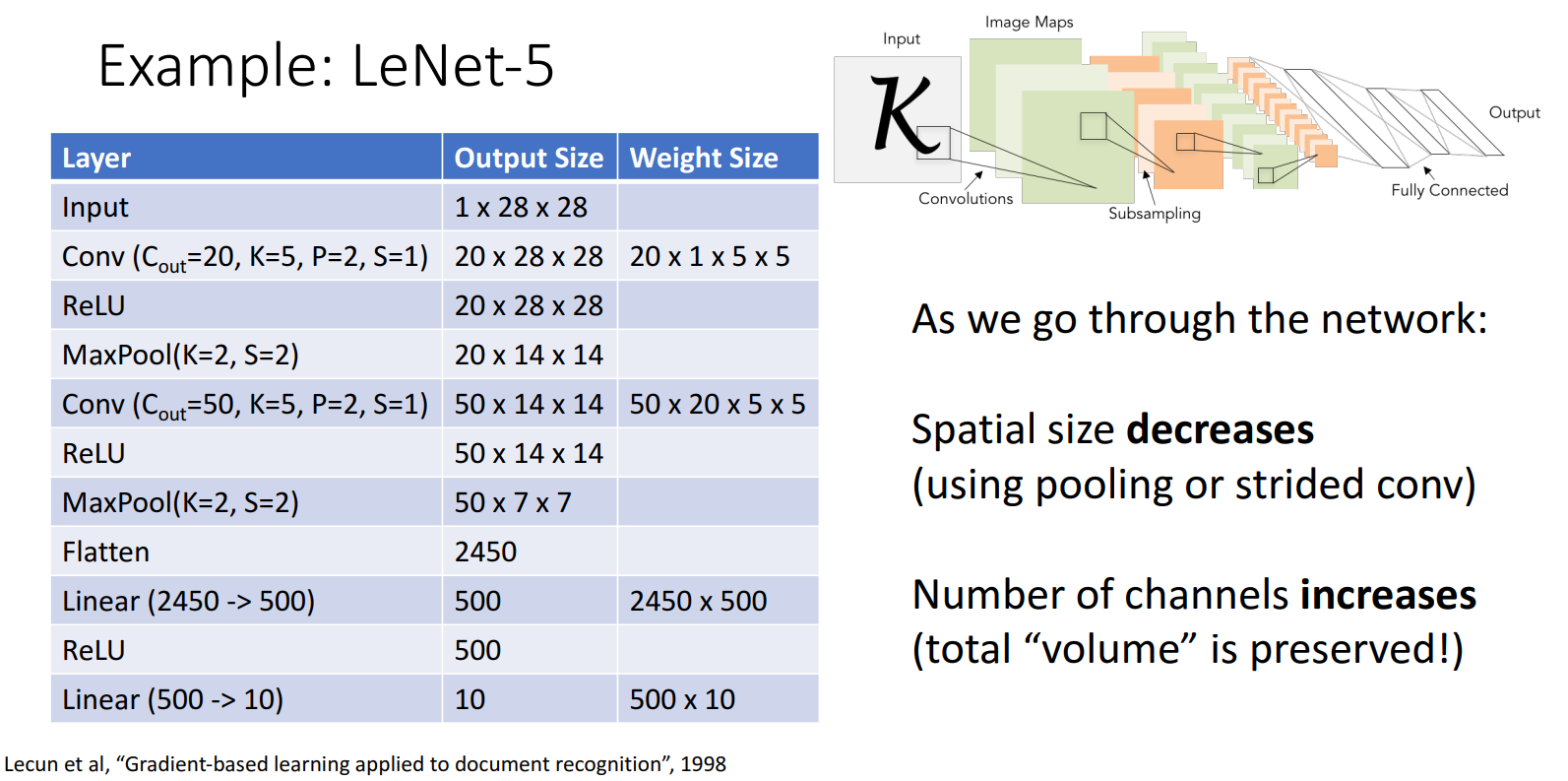
(1989) LeNet
- 1989年,LeCun等人提出LeNet-1,是第一个卷积神经网络。
- 1998年,LeCun等人提出LeNet-5
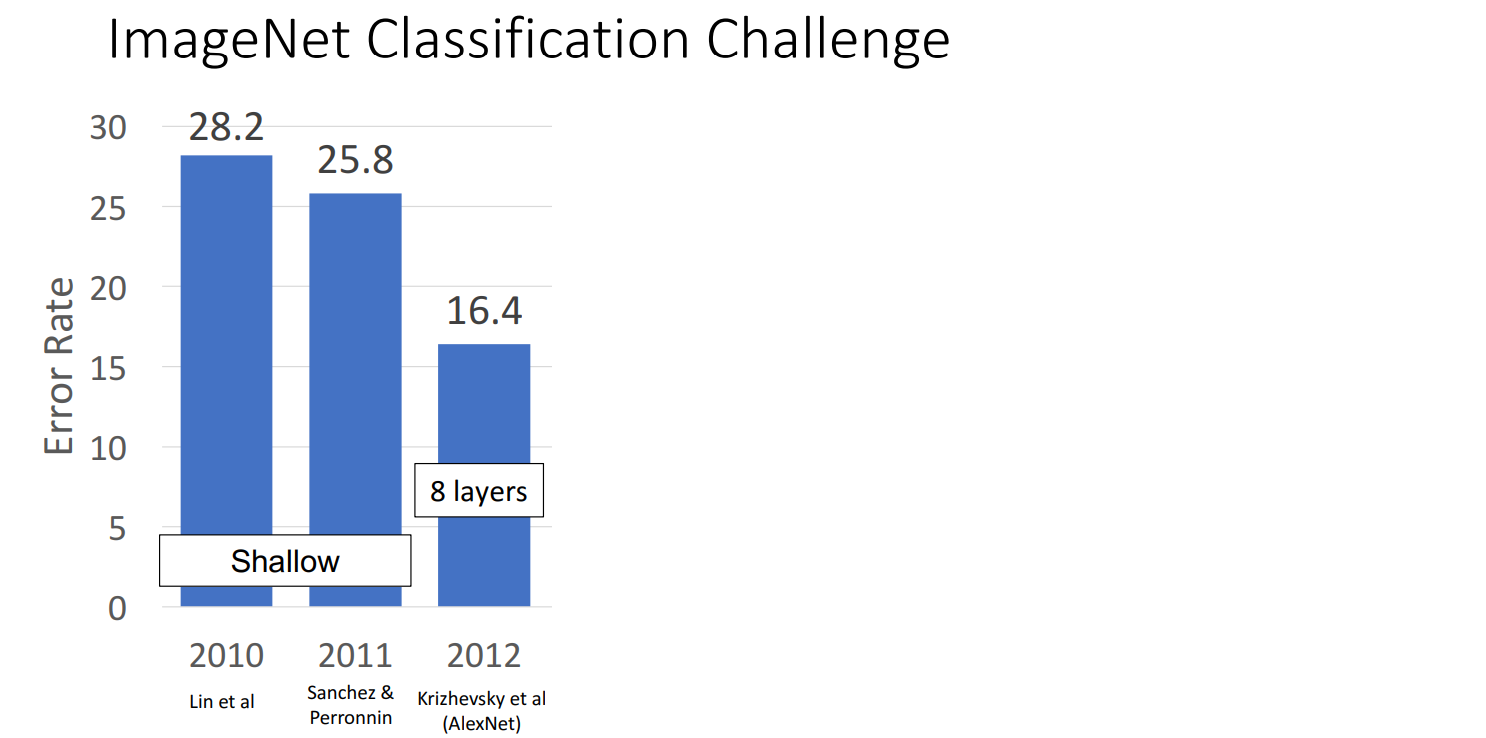
(2012) AlexNet
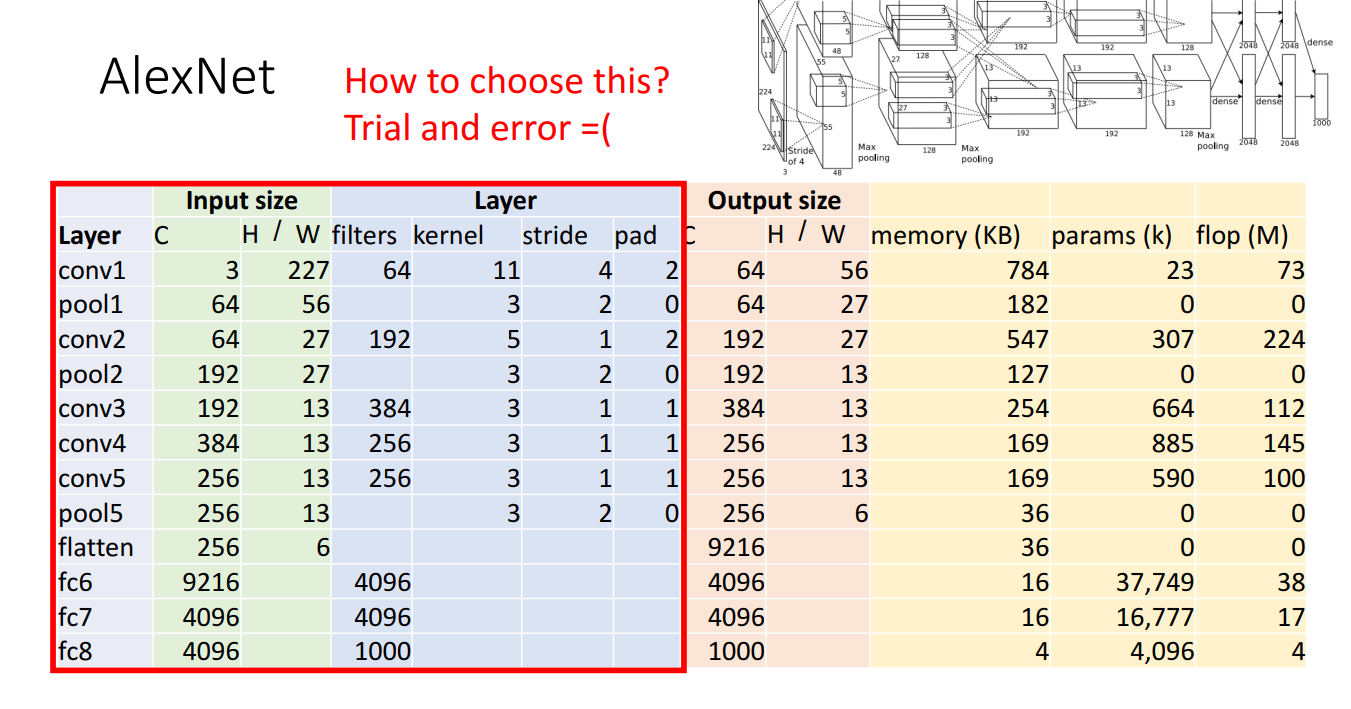
2012年以前,conv-nets的结构都比较简单、层数比较浅,AlexNet是第一个深度神经网络(DNN)。
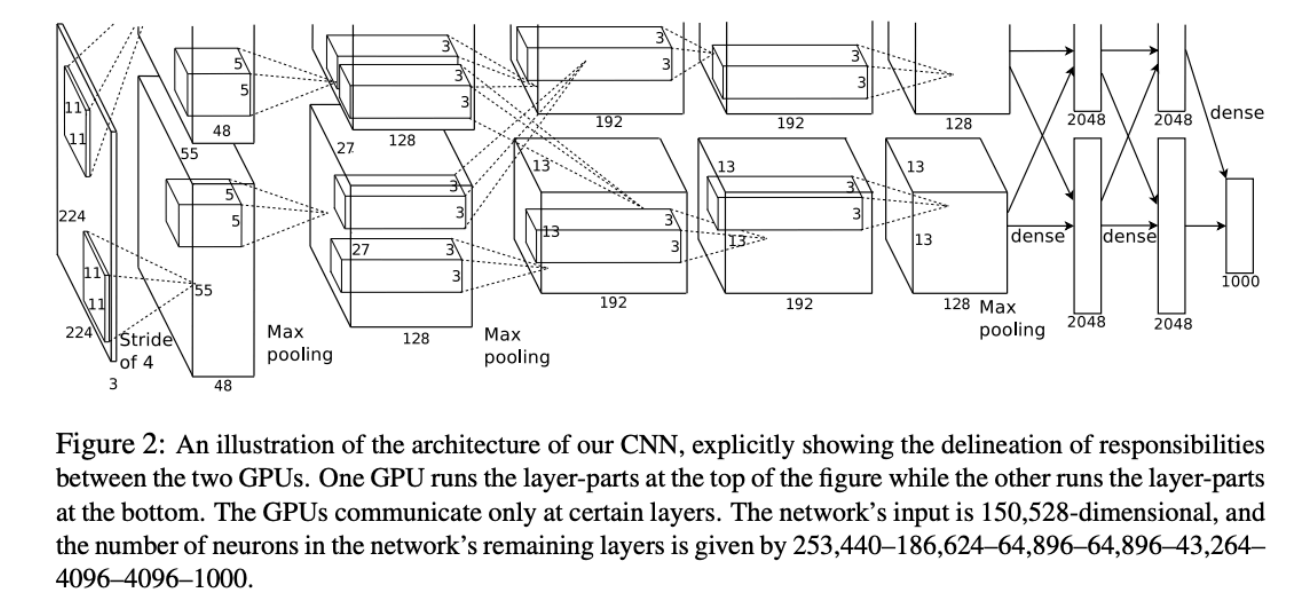
- 8 Layers:

- 5 Convolutional Layers
- Max Pooling
- 3 Fully Connected Layers
- ReLU Activation Function
- Used “Local Response Normalization” (Not used anymore)
- Trained on two GTX580 GPUs (only 3GB of memory each! Model split over two GPUs)
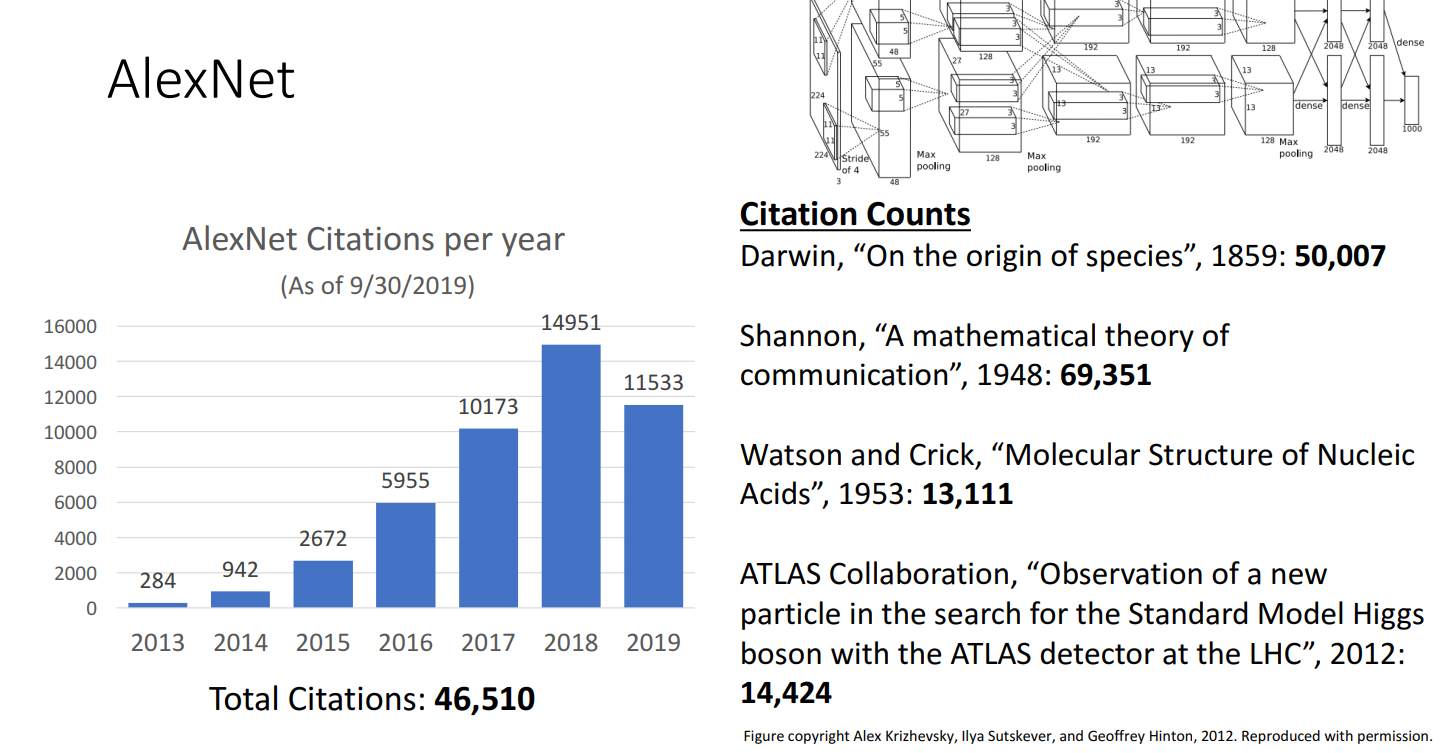
- Citations:
46510(As of 9/30/2019) - 计算量低,参数量大
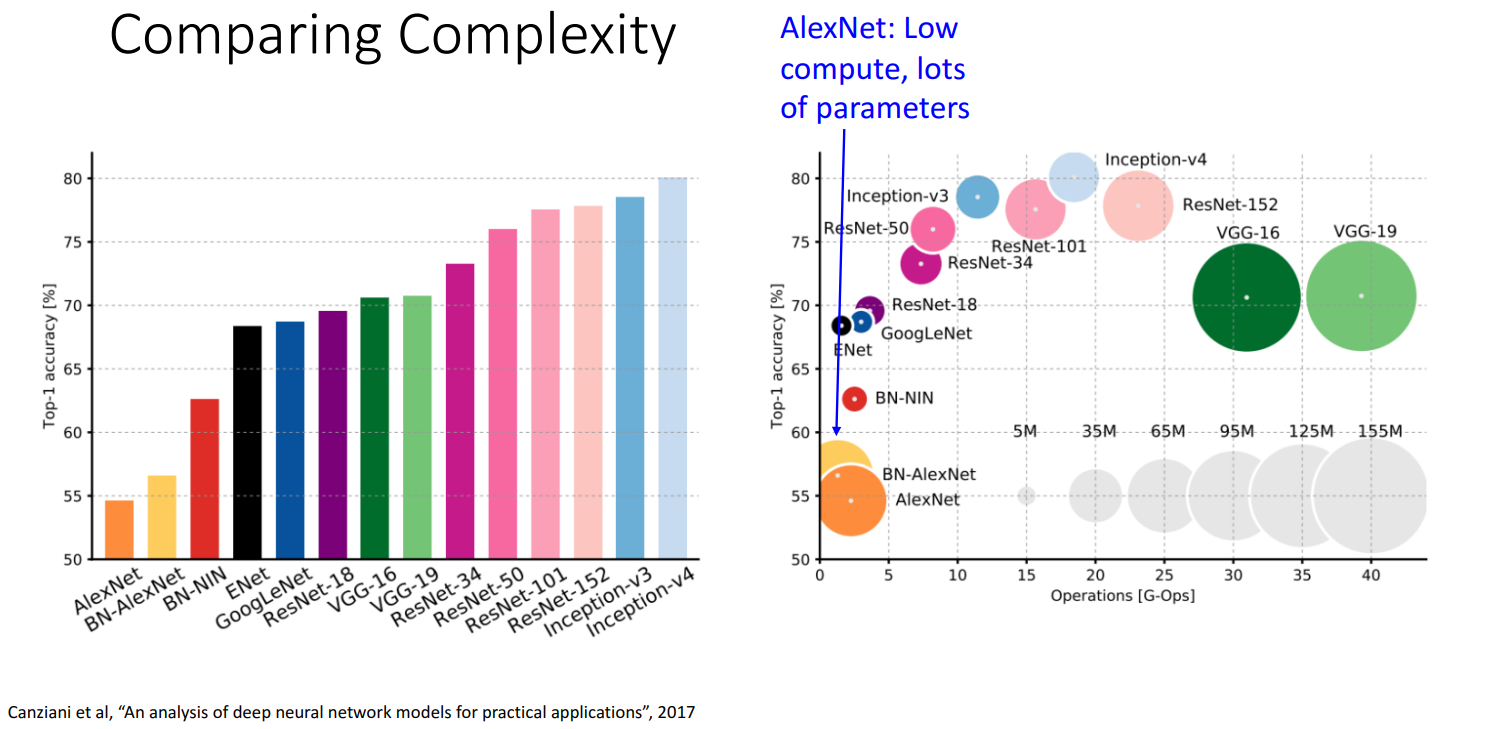
内存/参数量/计算量
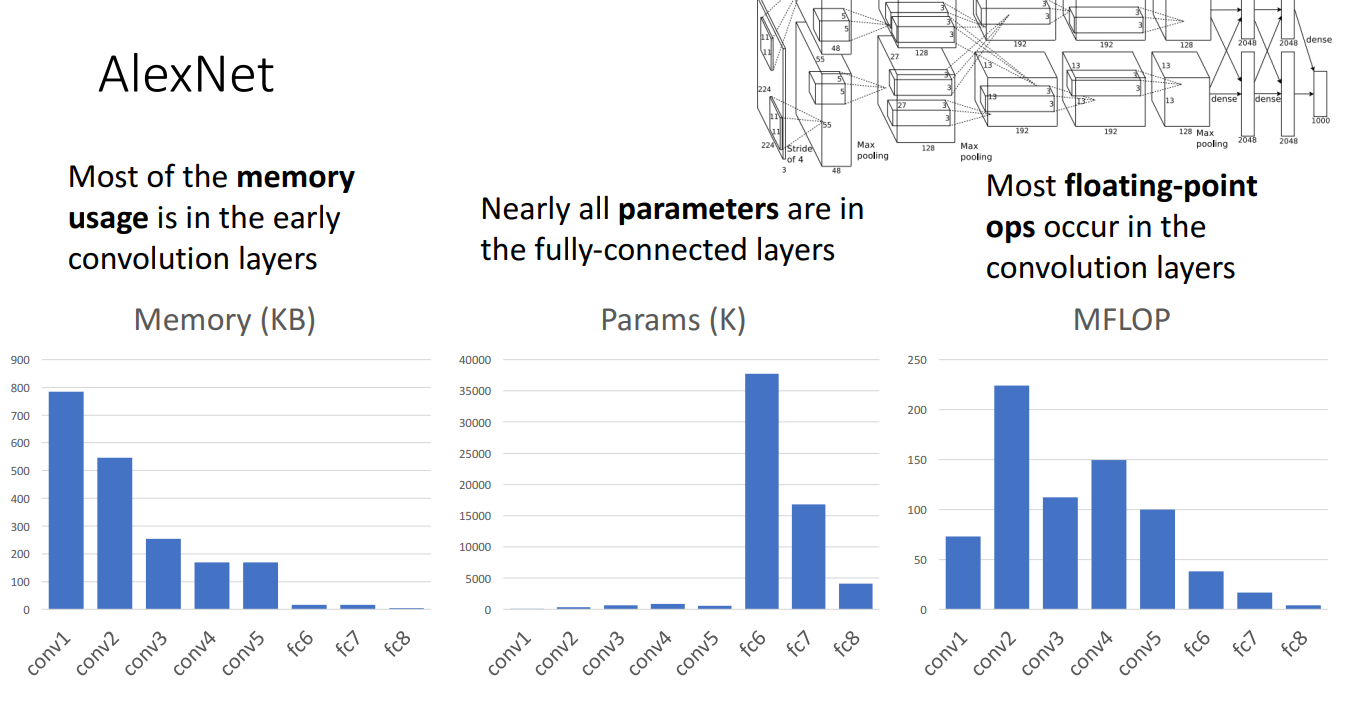
(start) 高分辨率的卷积层:
- 内存占用大
- 计算量大
- 参数量小
(end) 全连接层:
- 内存占用小
- 计算量小
- 参数量大
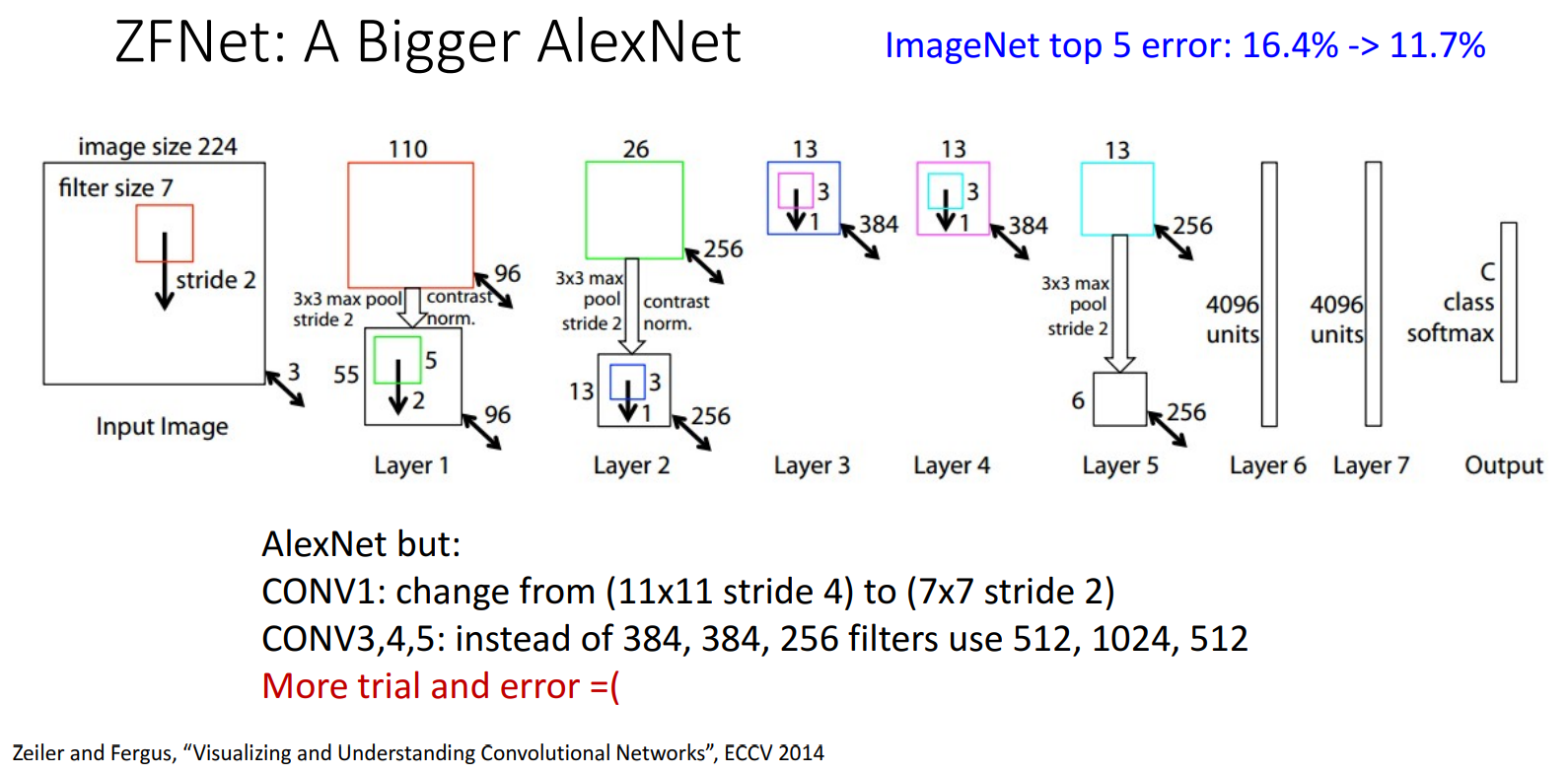
(2013) ZFNet
A Bigger AlexNet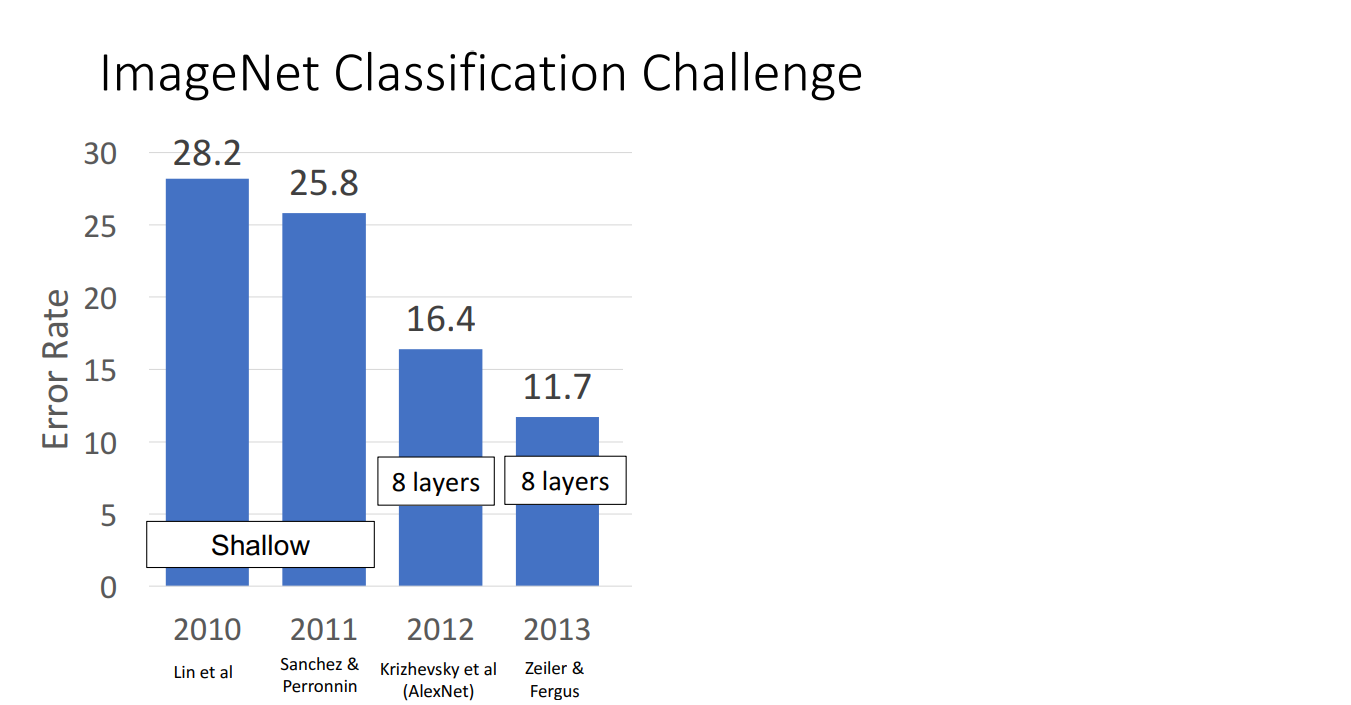
- 8 Layers
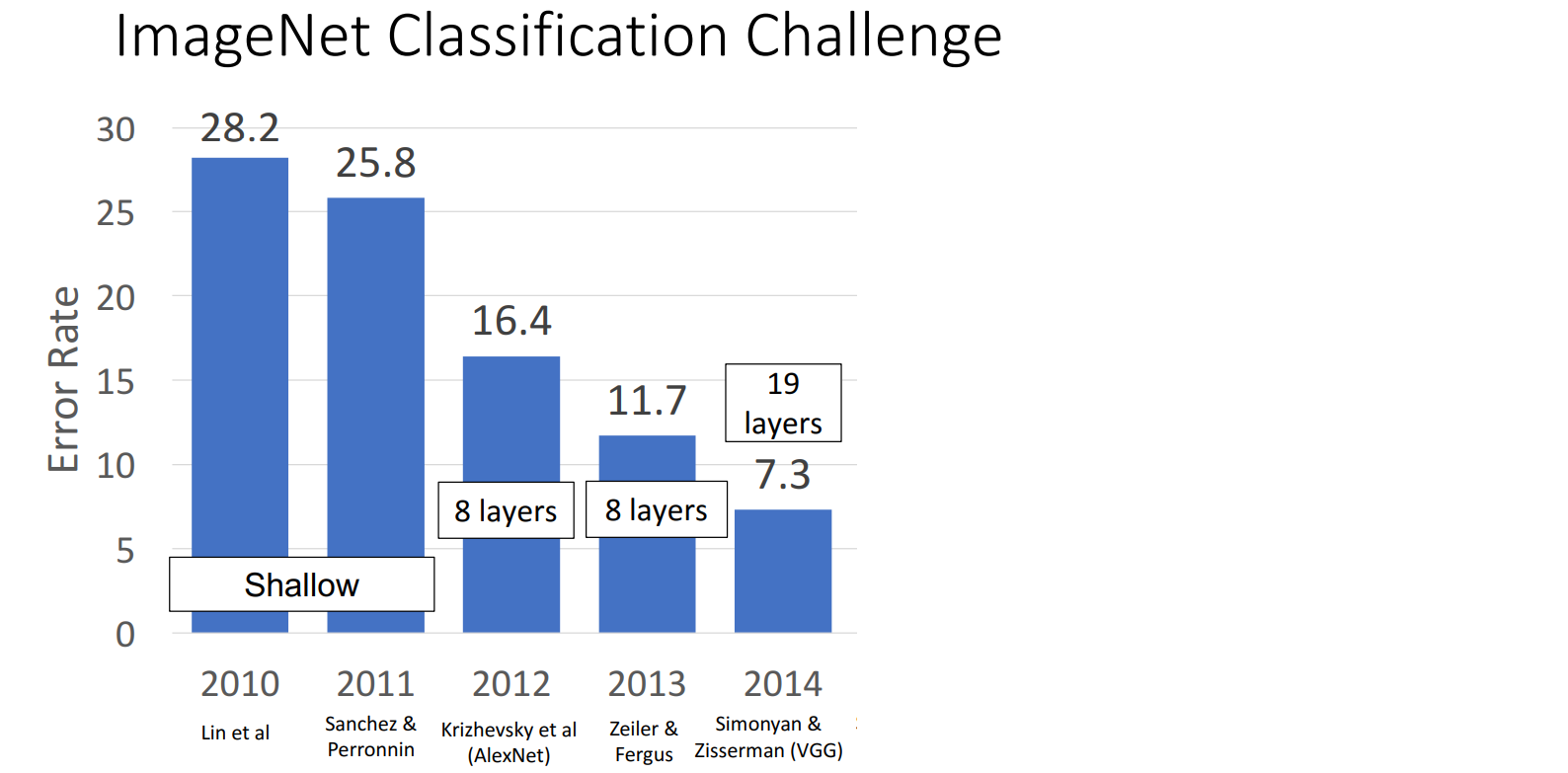
(2014) VGG
VGG表示Visual Geometry Group,是提出该网络的实验室的名称。
2014年之前的网络都是手工设计的网络,从VGG开始,遵循一些 Design Rule 进行设计。
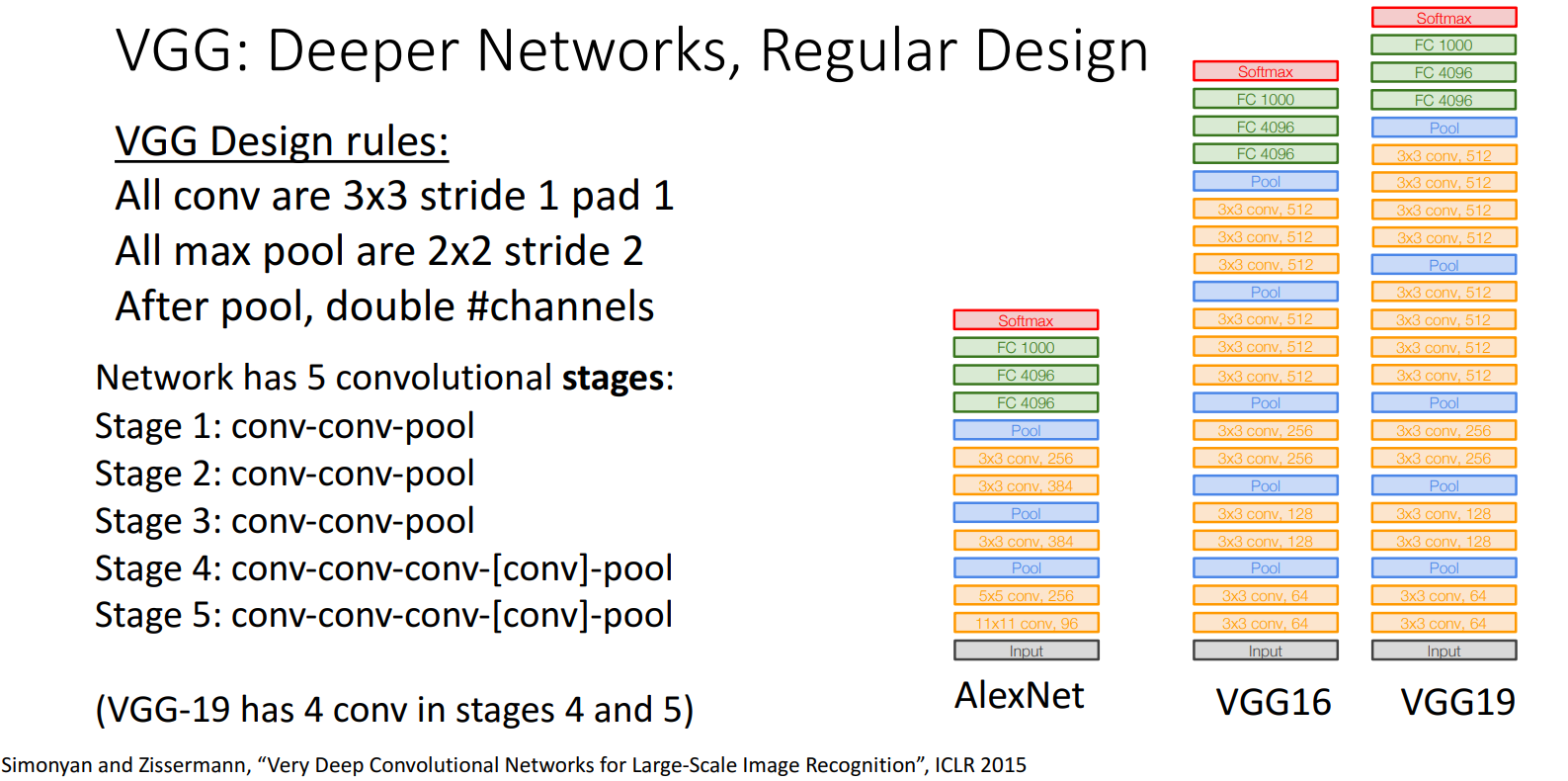
网络信息:
- 16/19 Layers
- VGG-16
- VGG-19
- 5 stages
- Stage 1: conv-conv-pool
- Stage 2: conv-conv-pool
- Stage 3: conv-conv-pool
- Stage 4: conv-conv-conv-[conv]-pool
- Stage 5: conv-conv-conv-[conv]-pool
- 3 Fully Connected Layers
VGG的影响:
- 证明了大的网络通常有更好的效果
- 给出了几个指导性原则,减少了超参量,使得网络结构的扩展变得方便
VGG的效率:内存占用高,计算量大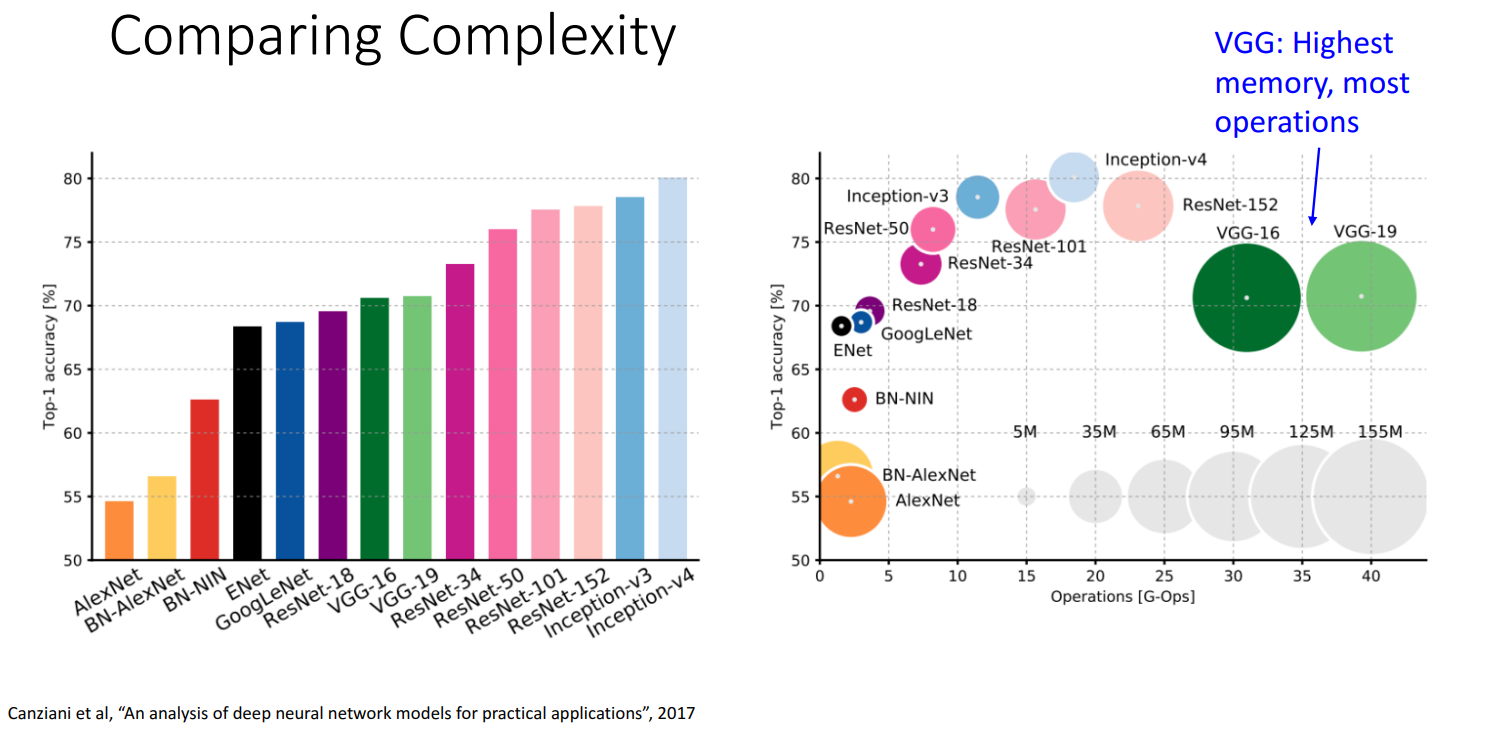
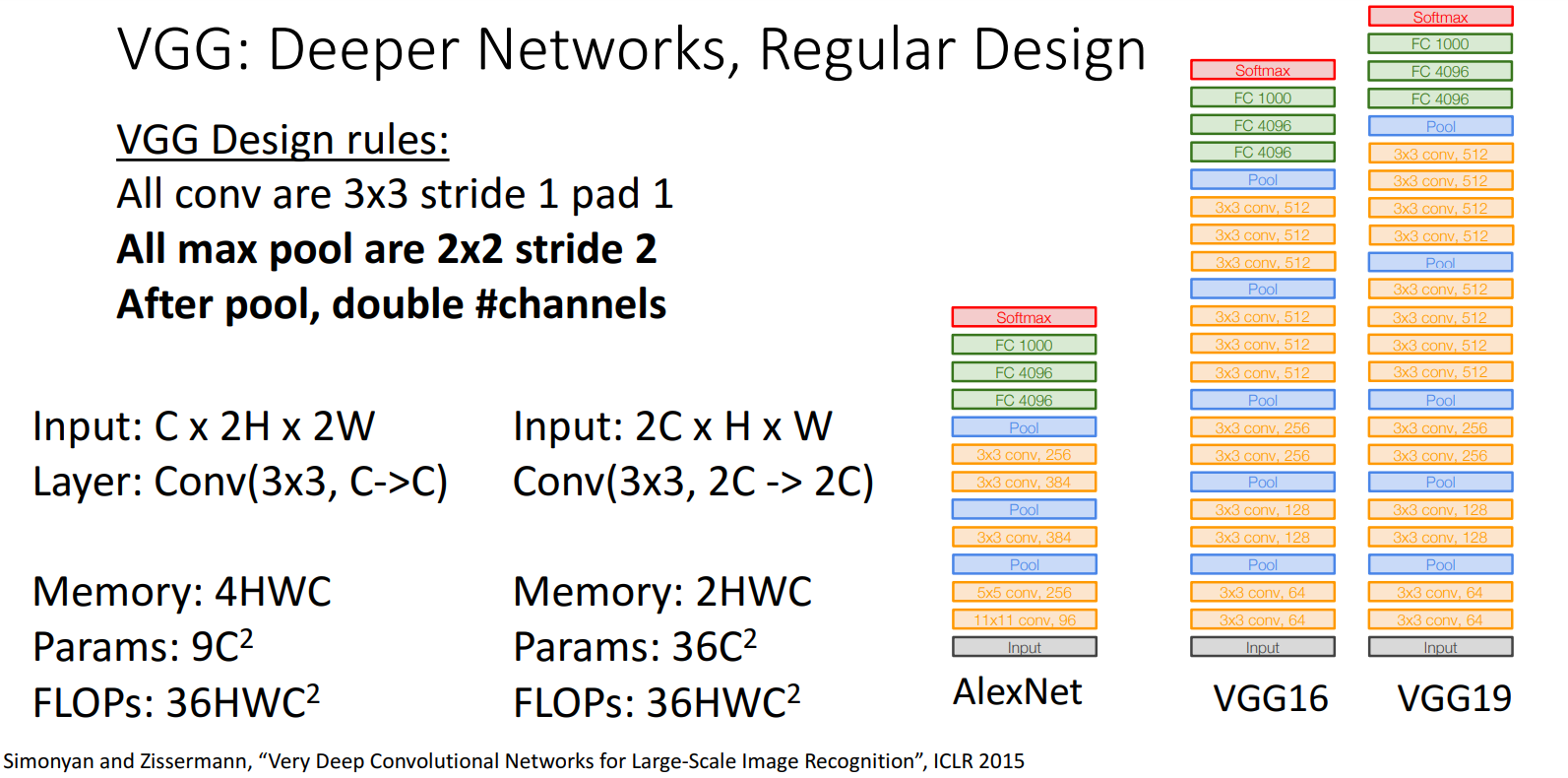
VGG Design Rules
- All conv are 3x3 stride 1 pad 1(都是
3x3卷积核)- VGG认为没有必要使用大的filter,将filter的大小固定为3x3。因为大的filter可以通过多层小filter组合得到,且参数量更少。
- eg: 2个3x3卷积核 == 1个5x5卷积核
- All max pool are 2x2 stride 2(都是
2x2池化) - After pool, double #channels (池化后,
通道数变成原来的2倍) -> 使不同大小的卷积层有相同的计算量

内存/参数量/计算量
Much bigger than AlexNet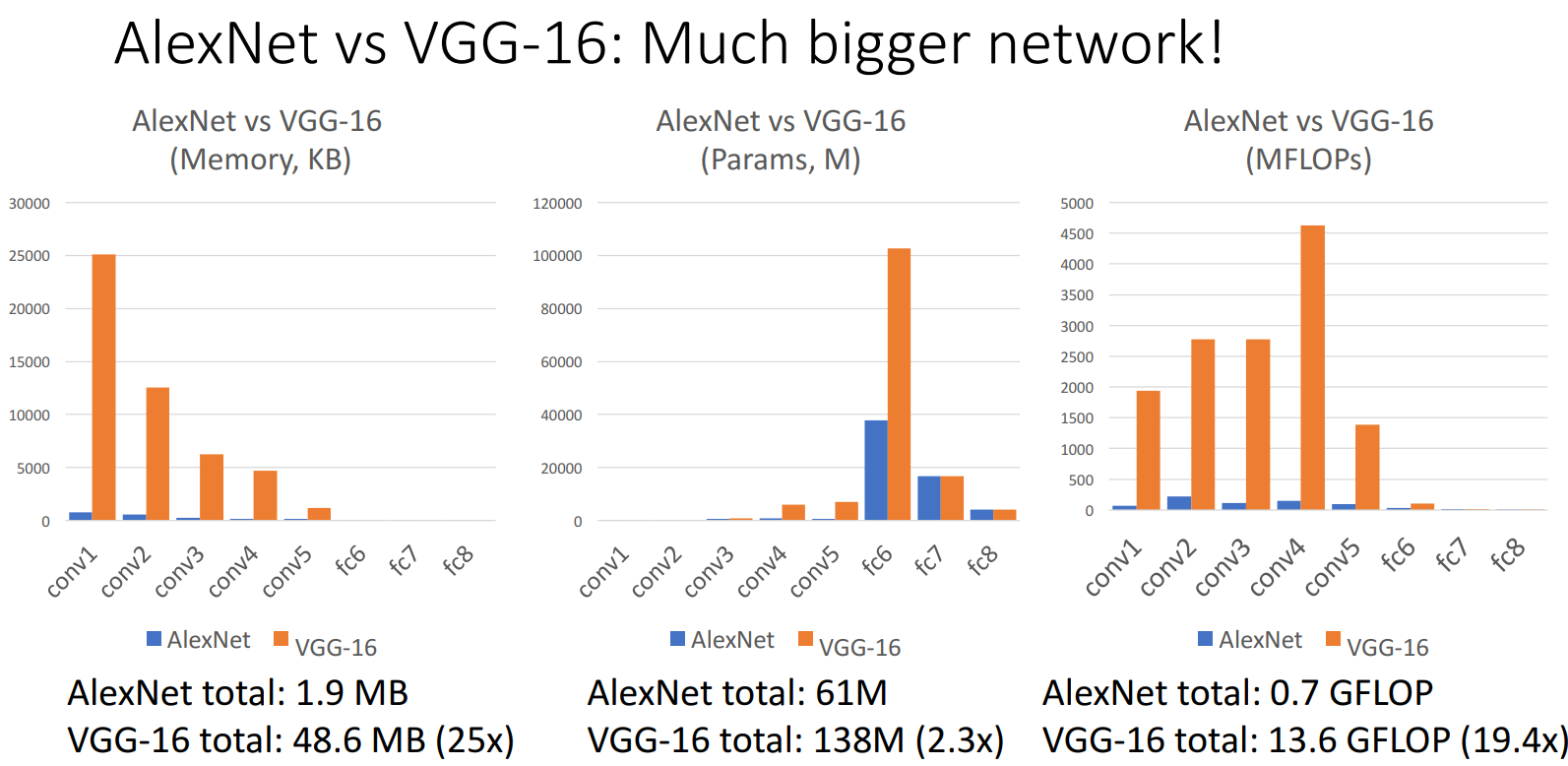
(2014) GoogLeNet
由Google团队提出,名称中的L大写以致敬LeNet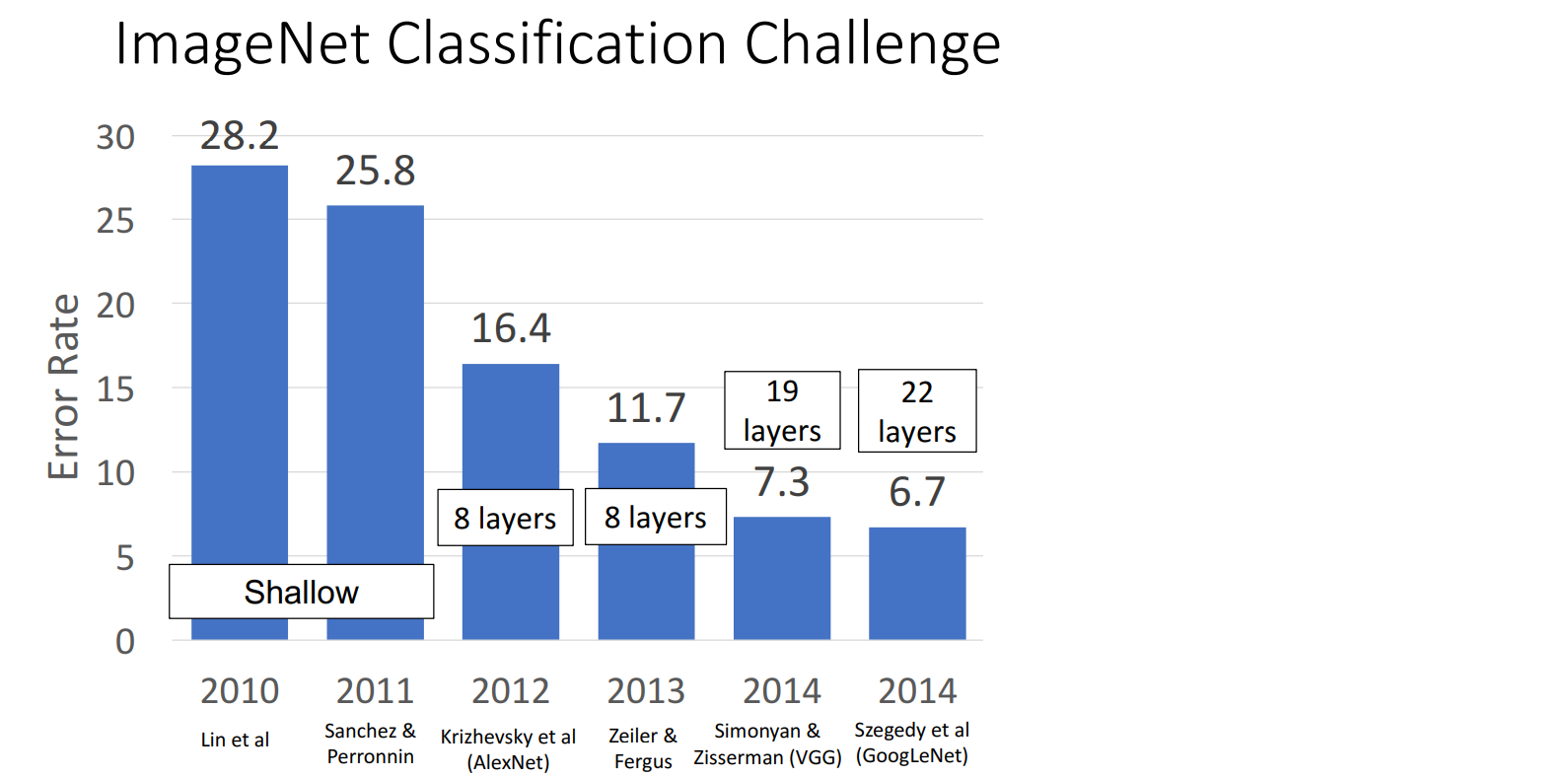
- 22 Layers
- GoogLeNet核心目标 -> 更高效 (以便在数据中心和手机上运行)
Many innovation for Effciency: reduce parameter count, memory usage, and computation.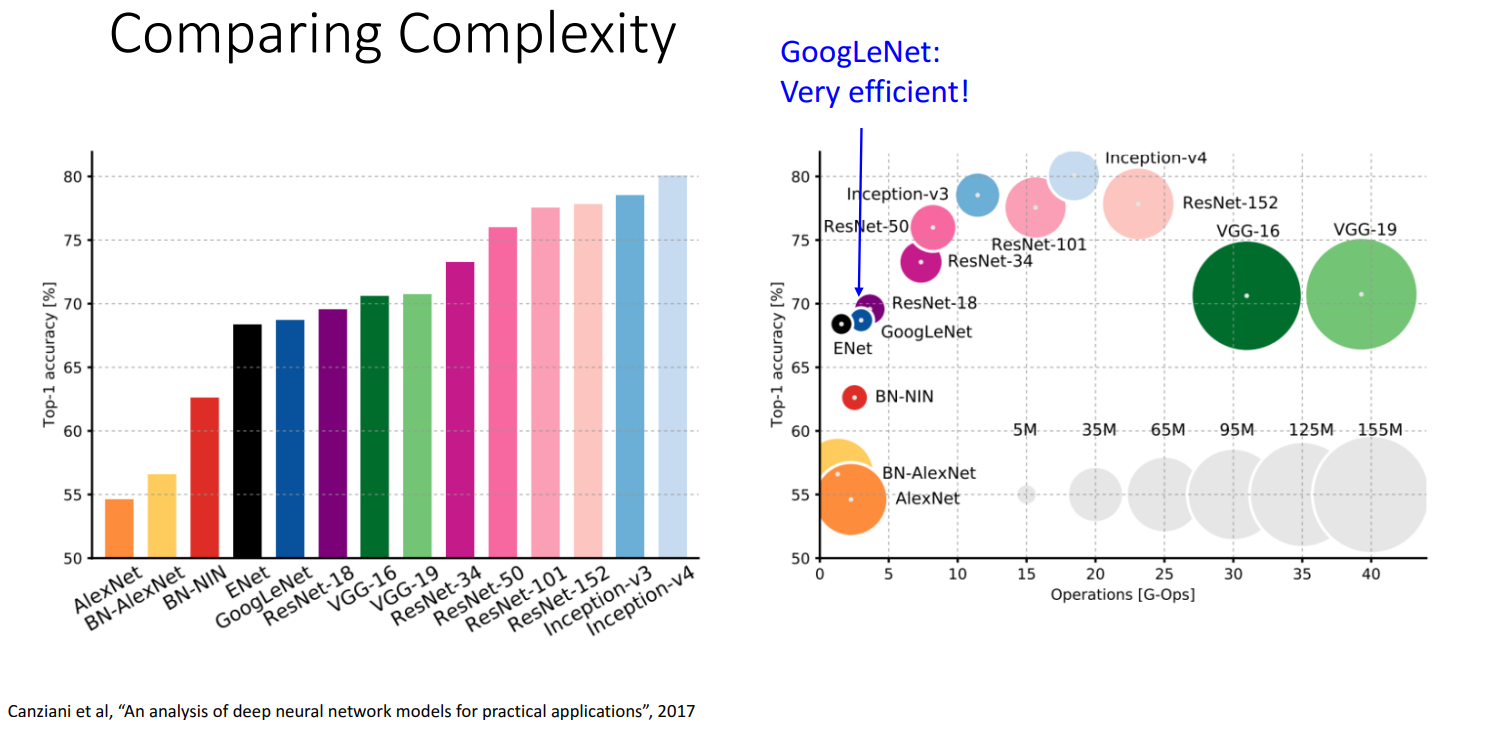
1.Stem network
开始时的 Stem network 对input进行积极的下采样 -> 减少计算量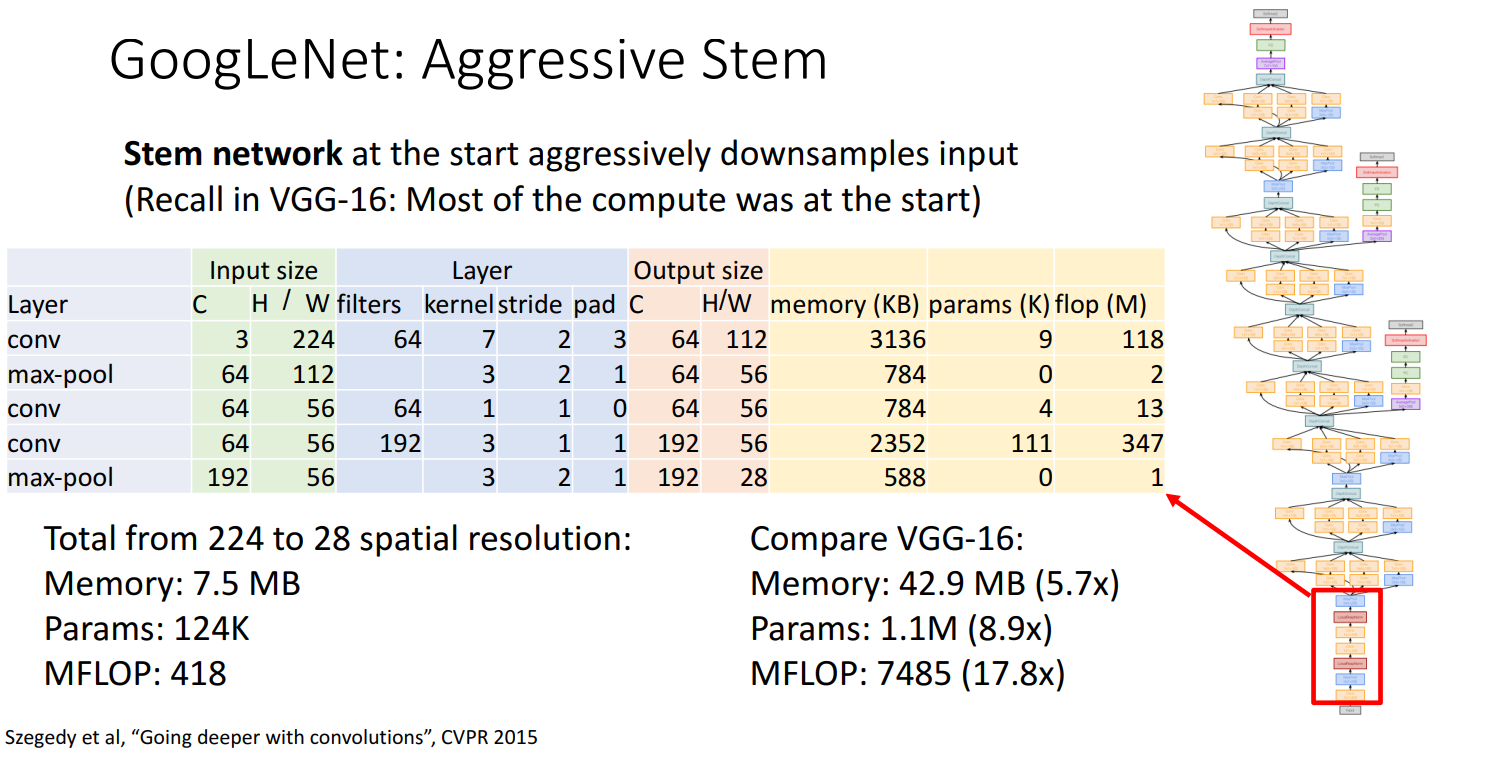
2.Inception Module
局部结构重复多次 -> 把每种size的filter都加进去(解决超参的另一种思路)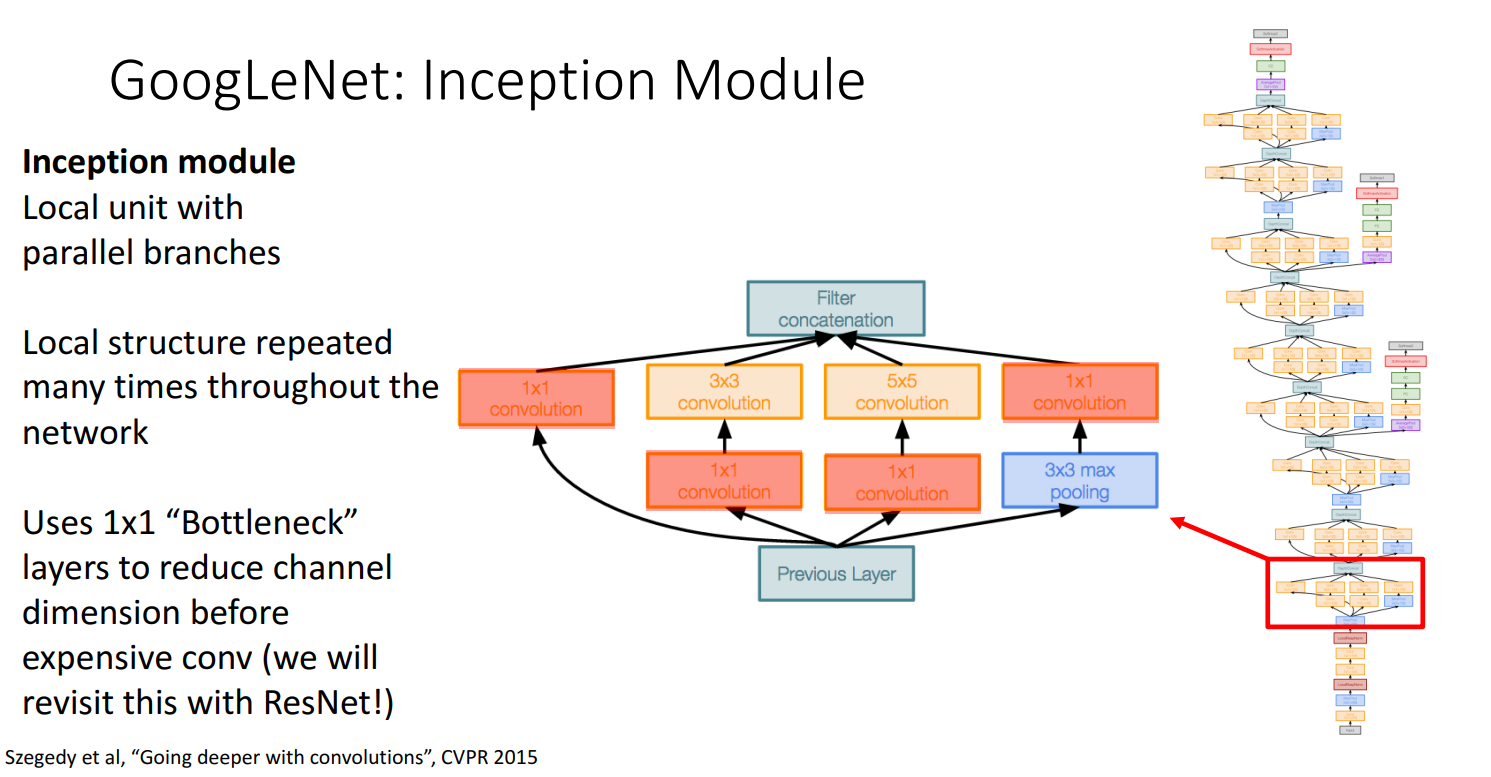
3.Global Average Pooling
在FC层之前进行 全局平均池化(Global Average Pooling) -> 减少参数量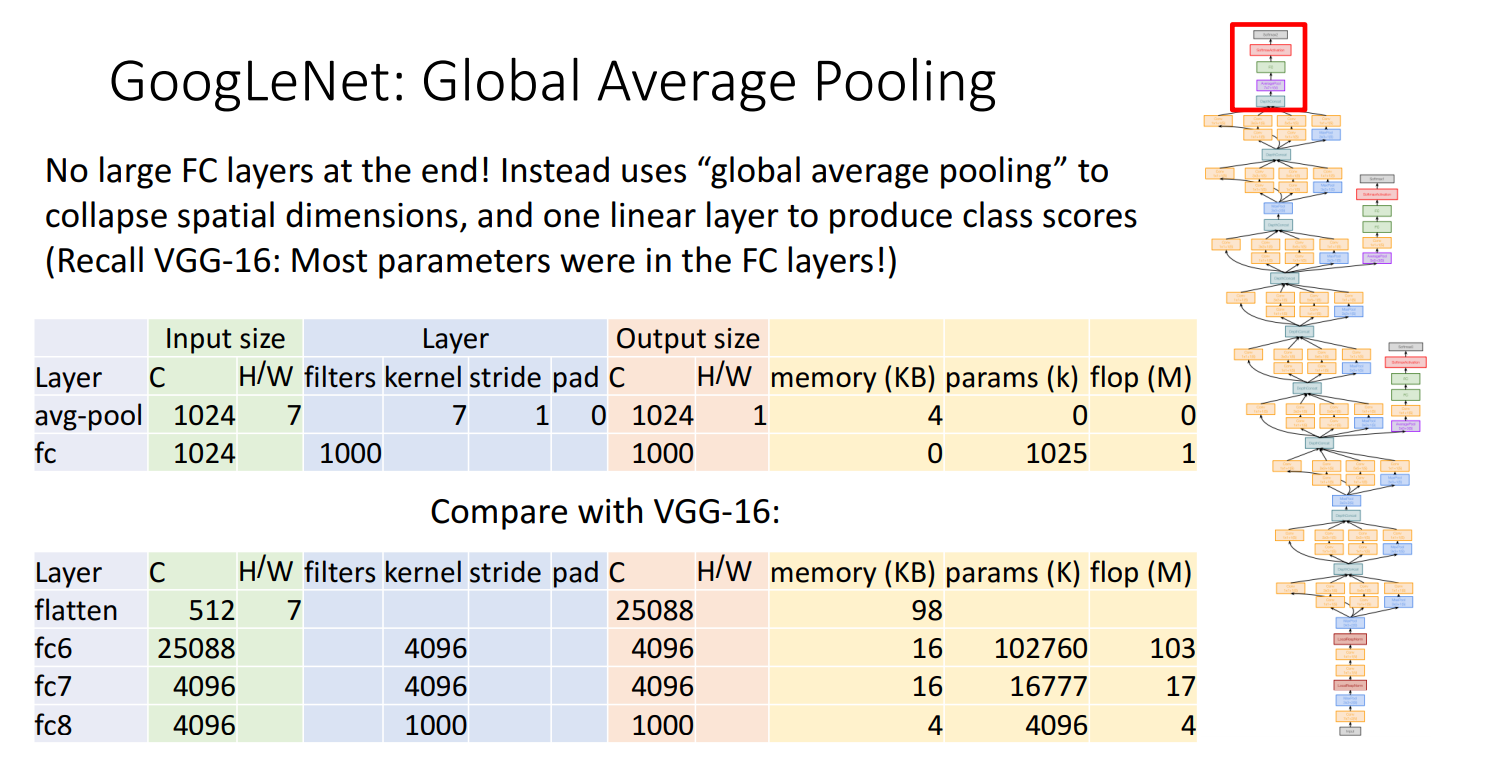
4.Auxiliary Classifier
使用了 辅助分类器(Auxiliary Classifier) ,对三个分类器的输出进行组合获得结果。(更容易反向传播获取梯度 -> 更新网络)
因为GoogLeNet太deep了,所以需要这种trick。但在15年batch normlization出现后,就不需要这种trick了。
(2015) ResNet
2015年的important news,席卷了imagenet数据集的所有赛道(classification,localization,detection),以及coco数据集的另一个比赛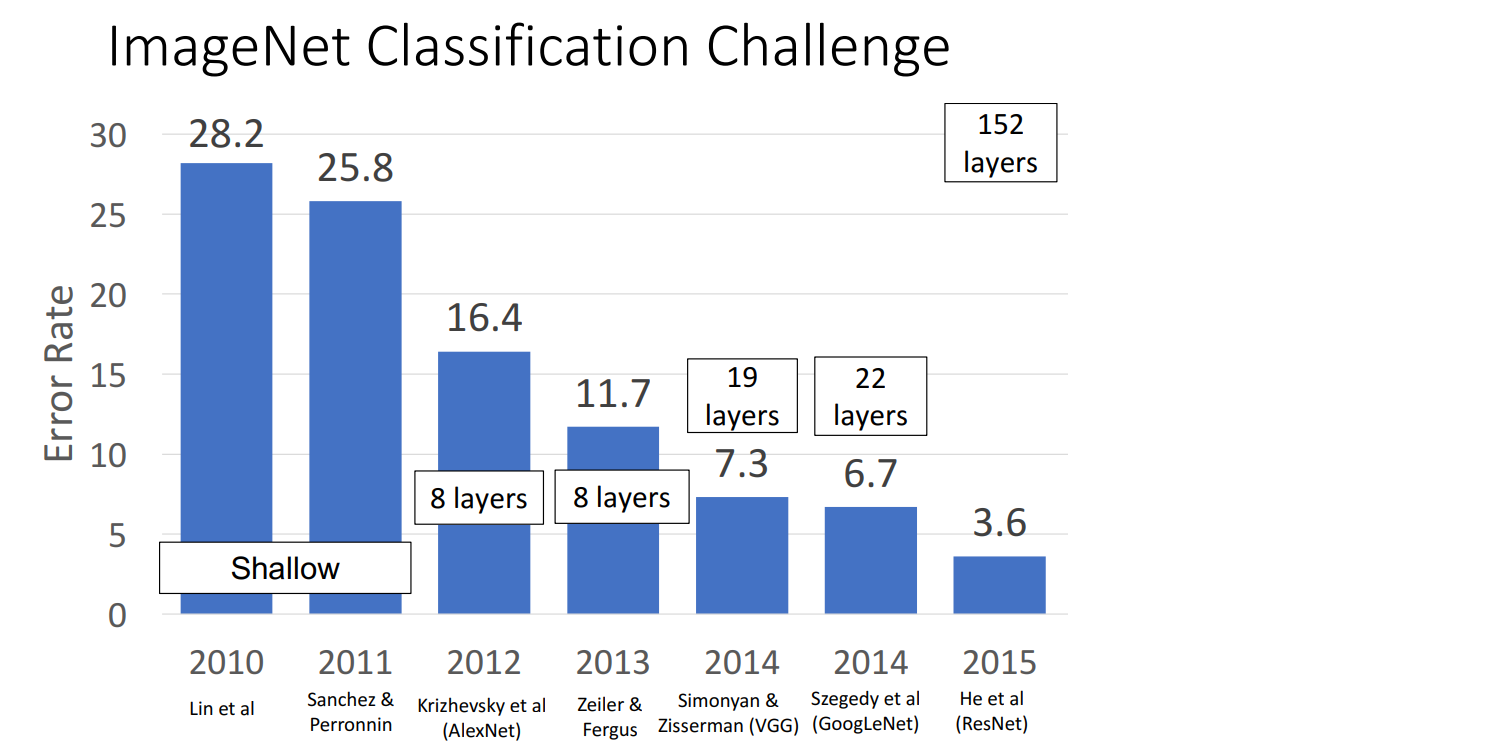

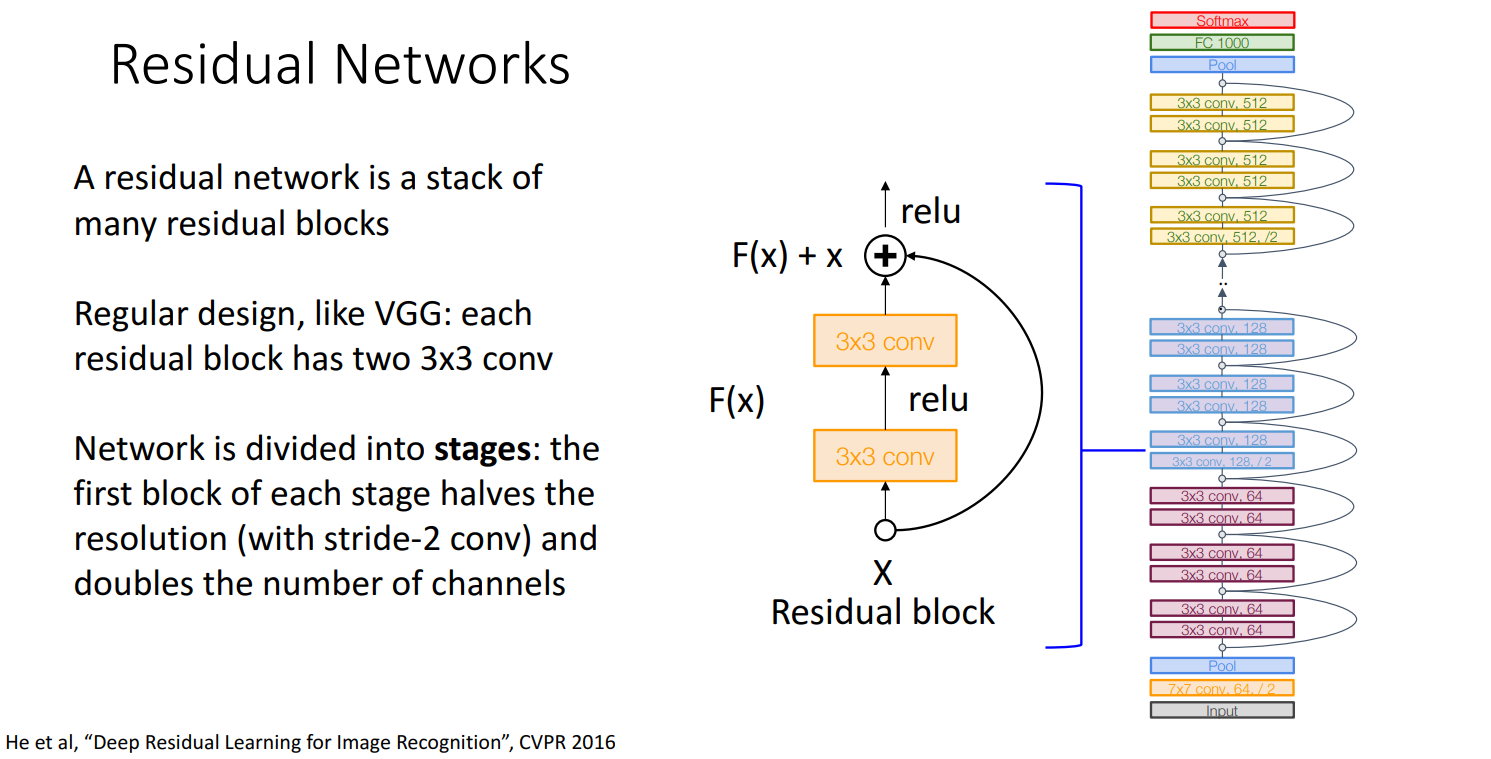
网络信息:
- 18/34/50/101/152 Layers
- ResNet-18
- ResNet-34
- ResNet-50
- ResNet-101
- ResNet-152
- ResNet采用了残差结构,其中“
残差块(Residual Block)”的设计 允许在不丢失特征的情况下进行高效学习。 - 借鉴了VGG和GoogLeNet的一些思想:
- 卷积后
通道数变为两倍(借鉴VGG。但VGG通道数的增加通常是在池化操作之后;而ResNet则是卷积操作之后,特别是在跨过“残差块”时) - 使用
stem network进行积极的下采样(借鉴GoogLeNet) - 使用
全局平均池化(Global Average Pooling)以减少参数量(借鉴GoogLeNet)
- 卷积后
- 因此和GoogleNet一样也非常高效:



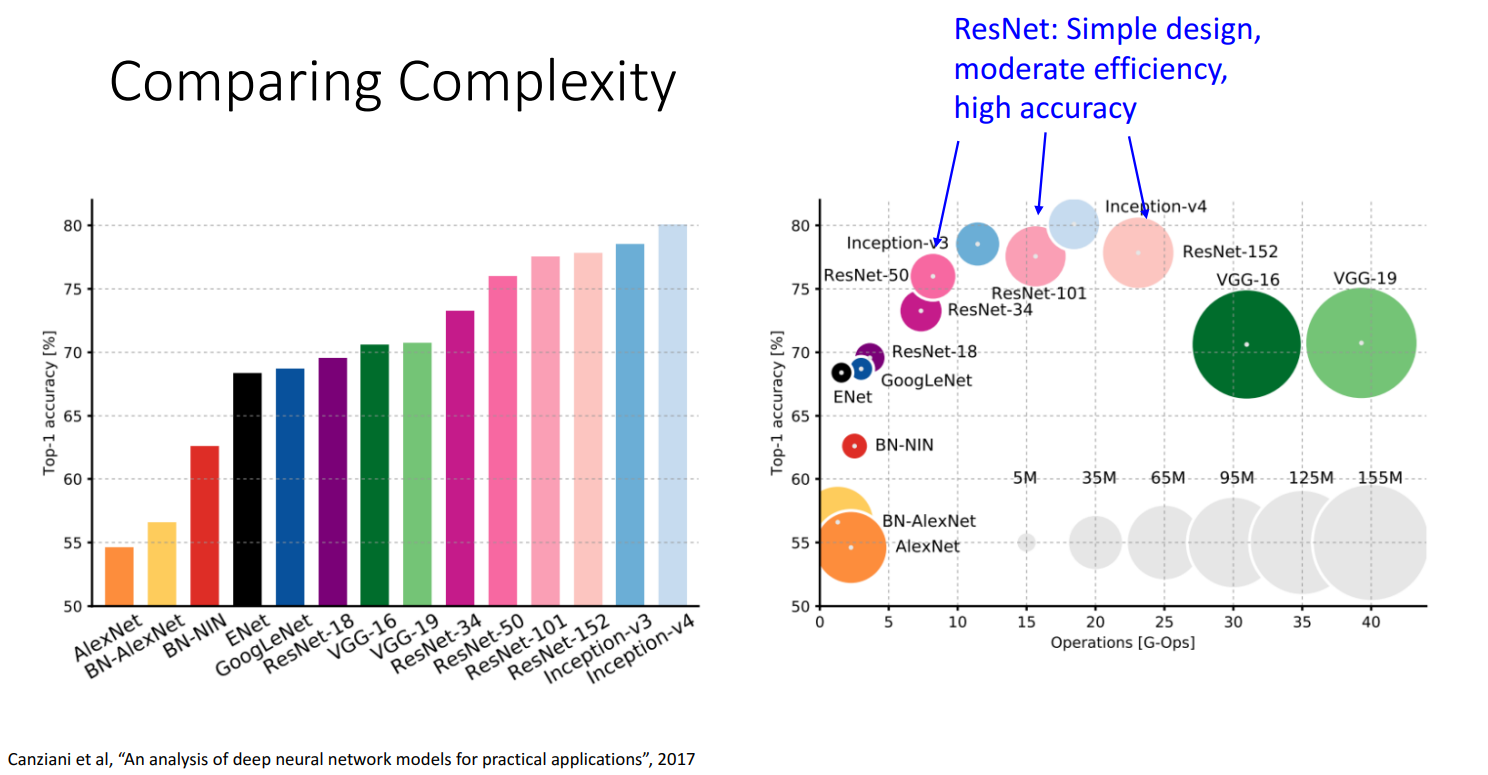
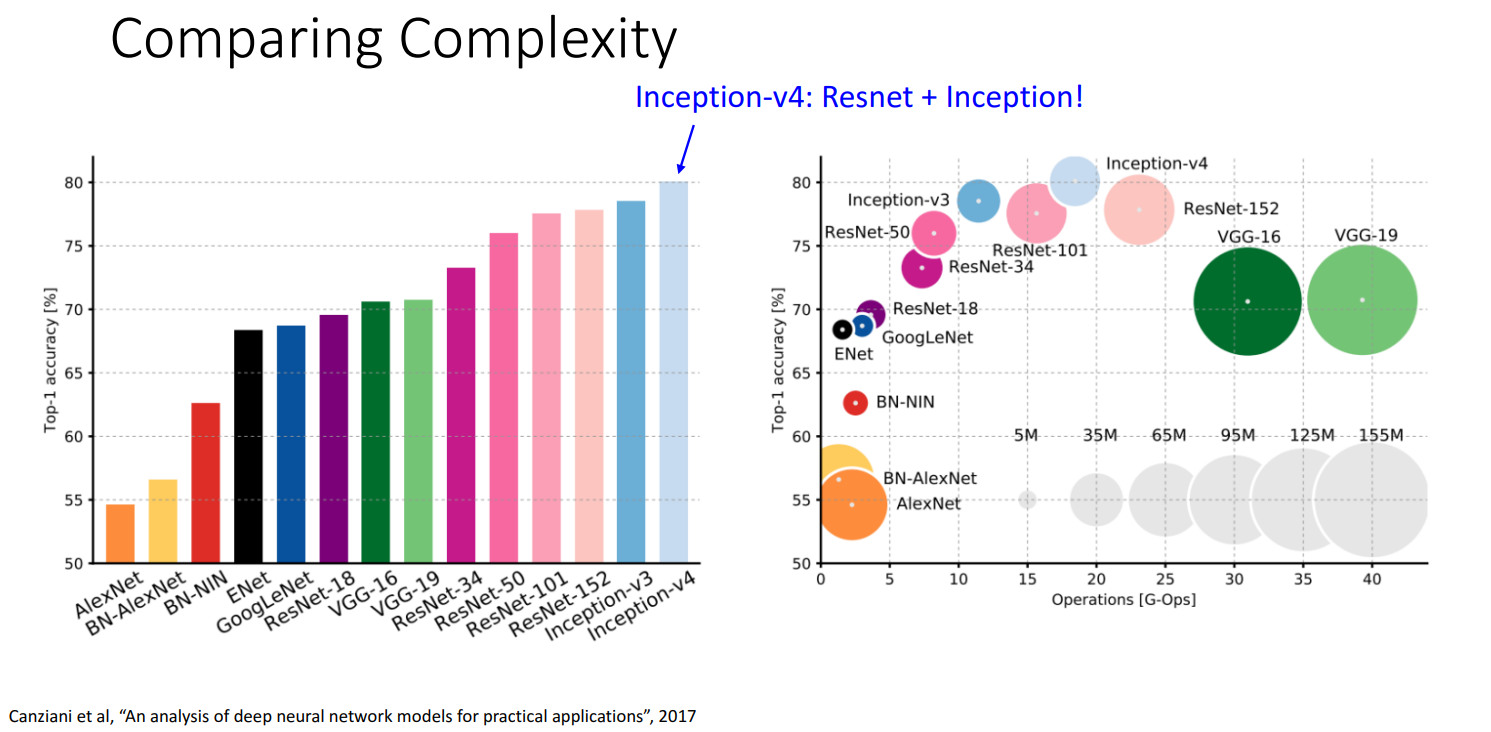
背景

- 背景:人们发现太深的模型表现反而不如浅的模型
- 原因:欠拟合(underfitting) ,训练集和测试集的表现都不佳
- 分析:
- 但是一个deeper model理论上可以模拟shallower model的(只需要- 复制前面的层,并让后面的层都是identity的就行)
- 因此deeper model至少应该表现和shallower mode相当
- 猜想:这是一个优化问题 -> deeper model 的优化比较难 -> 需要改变网络结构,以学习 恒等函数(identity function)
Residual Block
A Residual Network is a stack of Residual Blocks.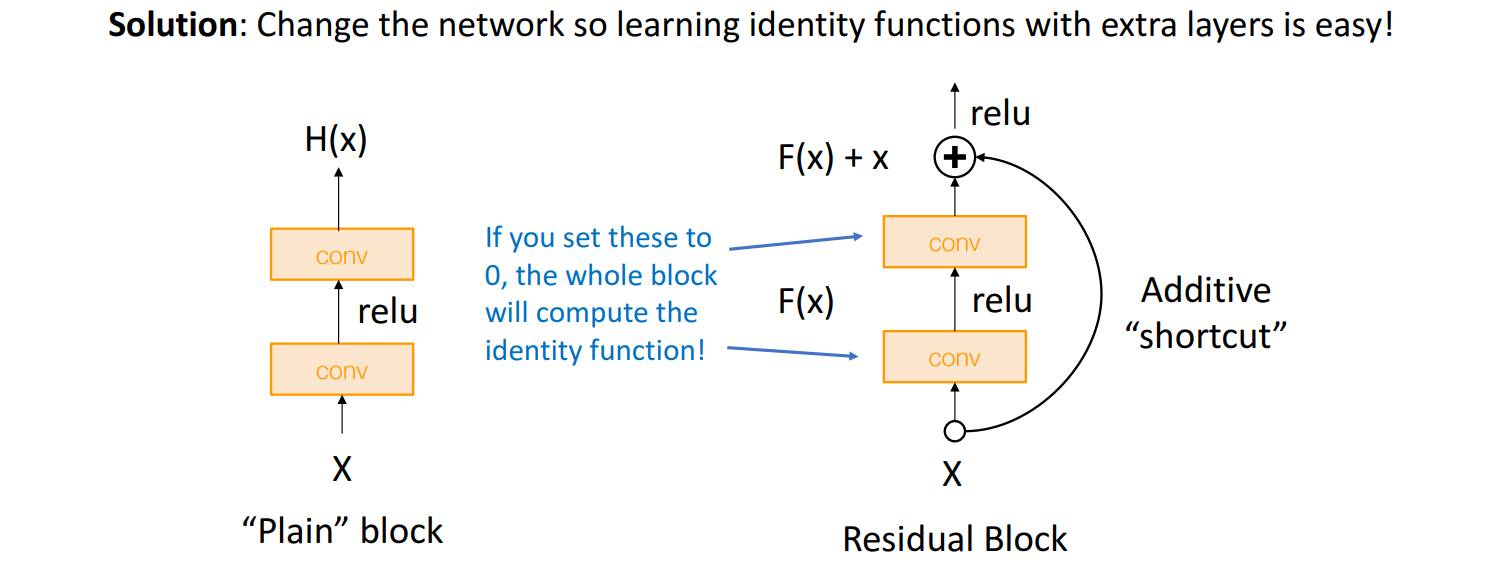
Bottleneck Block

- ResNet-50提出
- 更多的层和非线性,更少的计算量
eg: 从ResNet-34到ResNet-50,在几乎不增加计算量的情况下,将性能大幅提高)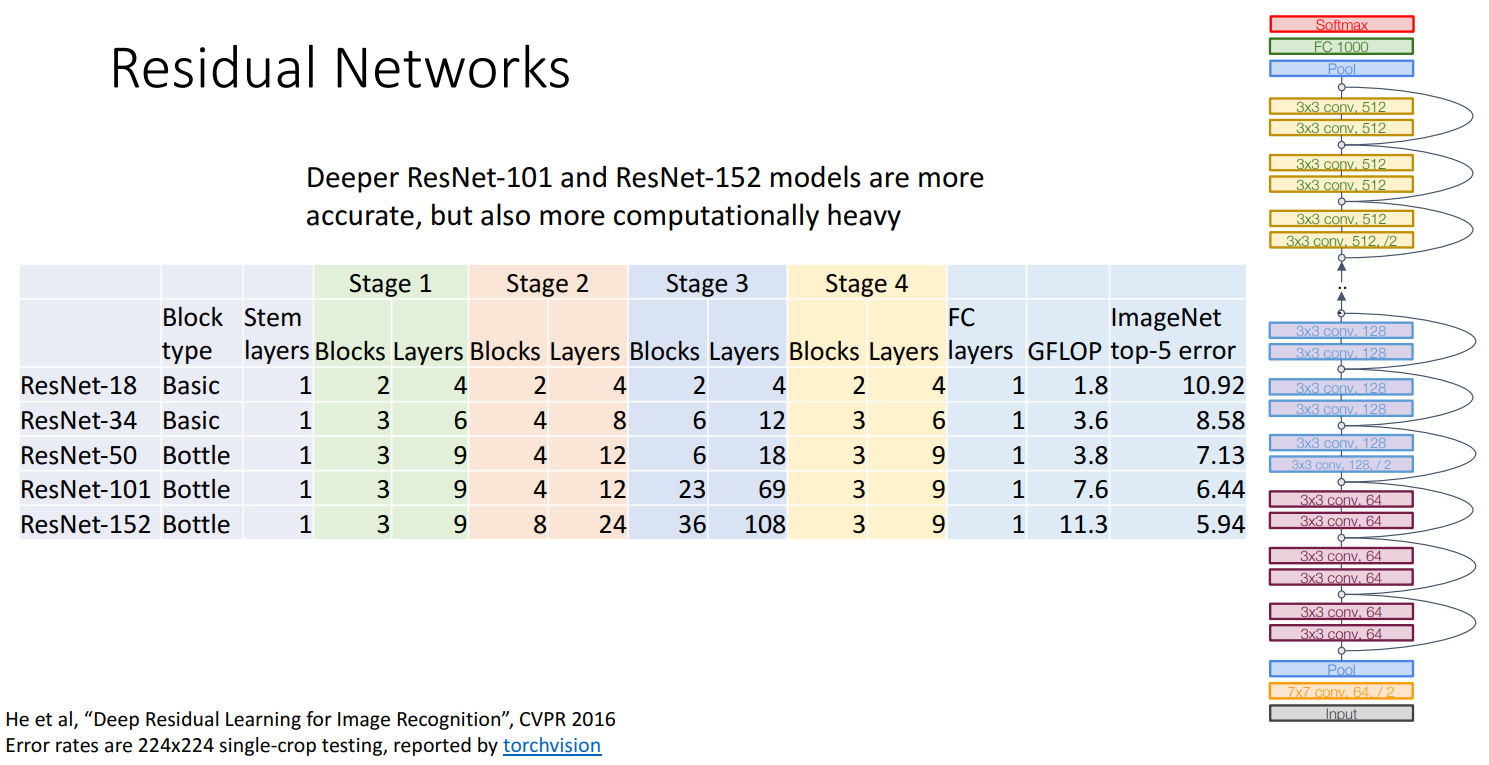
“Pre-Activation” [CVPR’16]
预激活的残差块(能真正学习到identity function)
- He et al. CVPR2016
- 先激活再卷积
- 稍微提升了准确率
- 但在实践中没有被使用


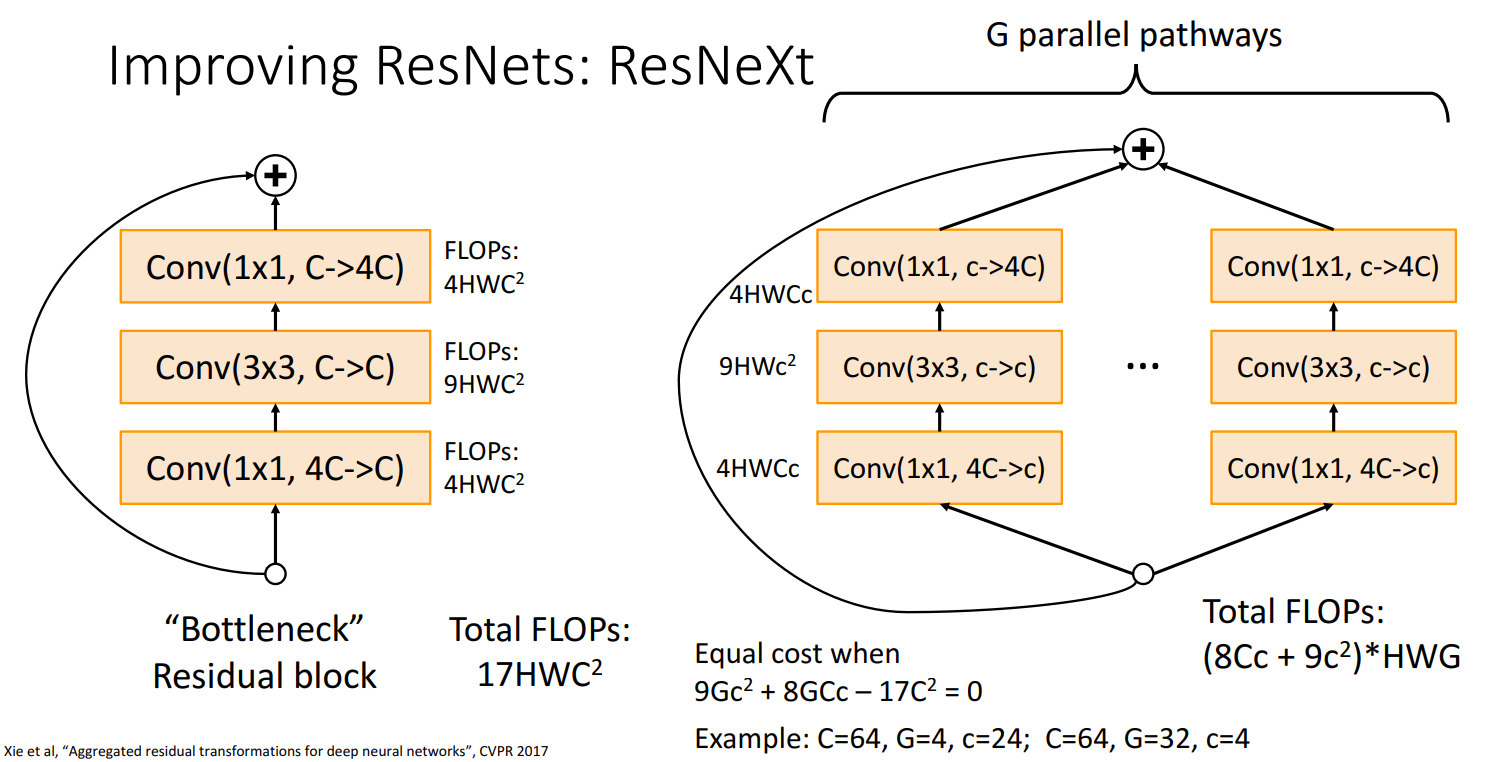
“ResNeXt” [CVPR’17]
G个并行的残差块
- Xie et al. CVPR2017
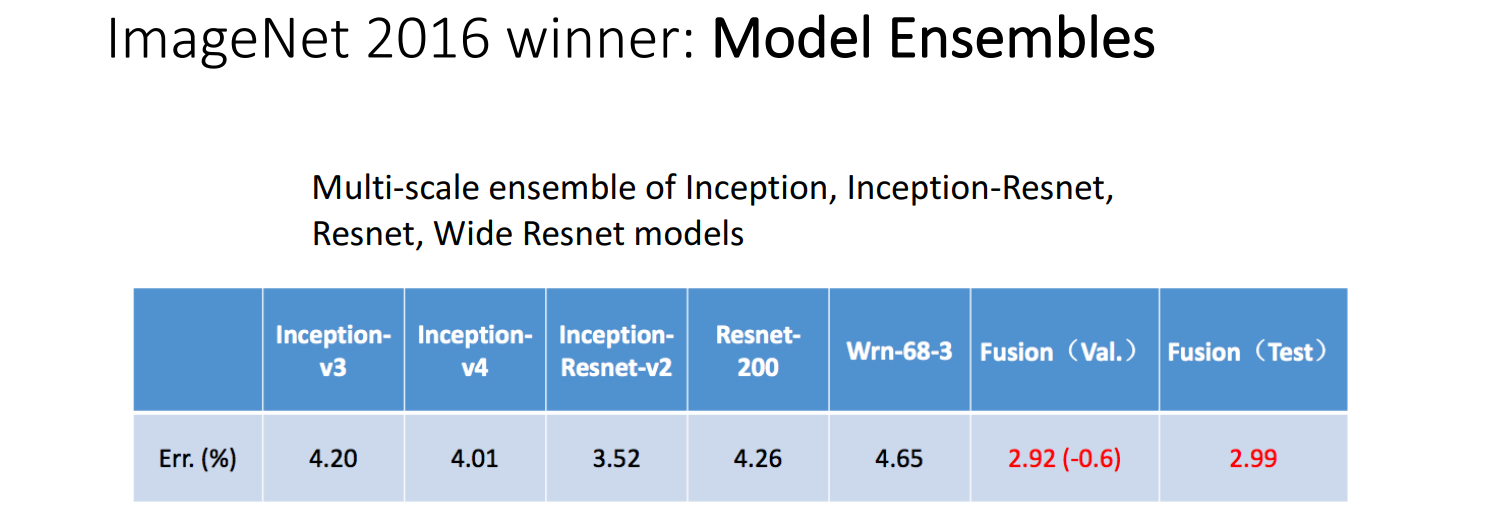
(2016) Model Ensembles
集成多个模型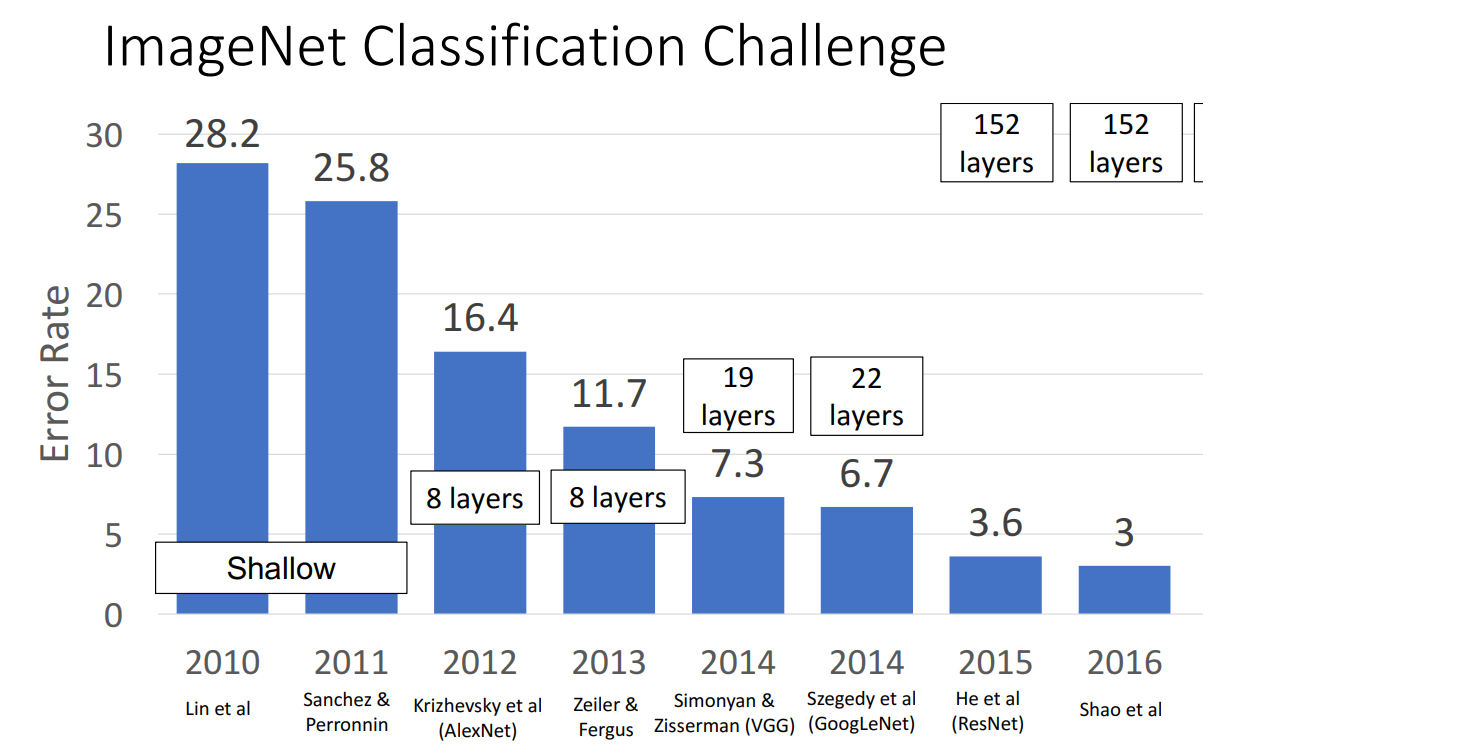
(2017) SENet
- Title: [EECS498/598] lecture 08: CNN Architectures(CNN经典架构)
- Author: LeoJeshua
- Created at : 2025-01-01 08:08:00
- Updated at : 2025-03-10 20:23:58
- Link: https://leojeshua.github.io/Course/eecs498/eecs498-08/
- License: This work is licensed under CC BY-NC-SA 4.0.