![[EECS498/598] lecture 13: Attention(注意力机制)](https://raw.githubusercontent.com/LeoJeshua/PicGo/main/images/20241227205140.png)
[EECS498/598] lecture 13: Attention(注意力机制)
lecture 13: Attention(注意力机制)
slide: https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture13.pdf
- Multimodal attention
- Self-Attention
- Transformers
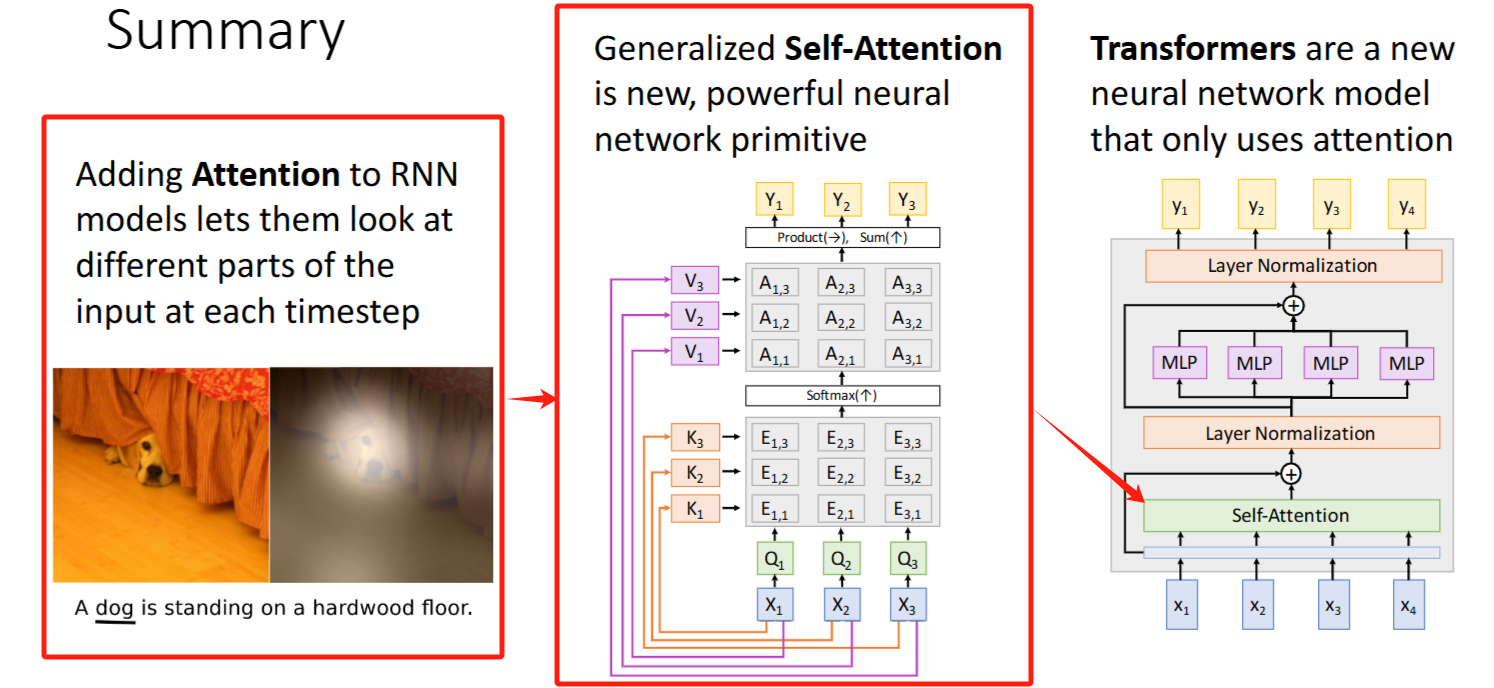
Attention机制
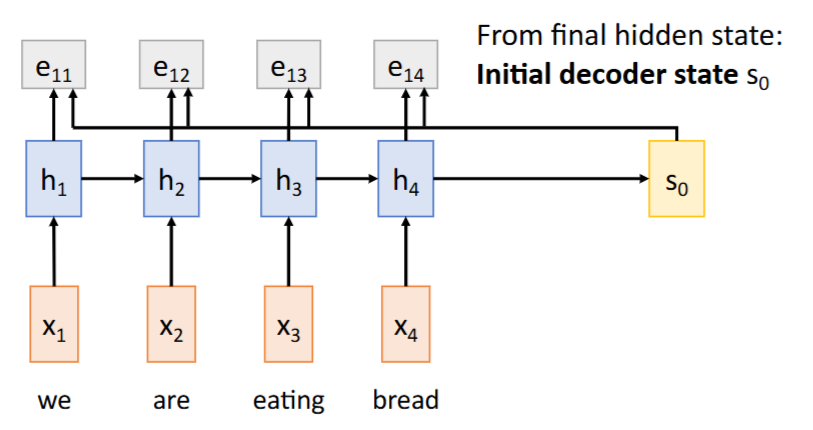
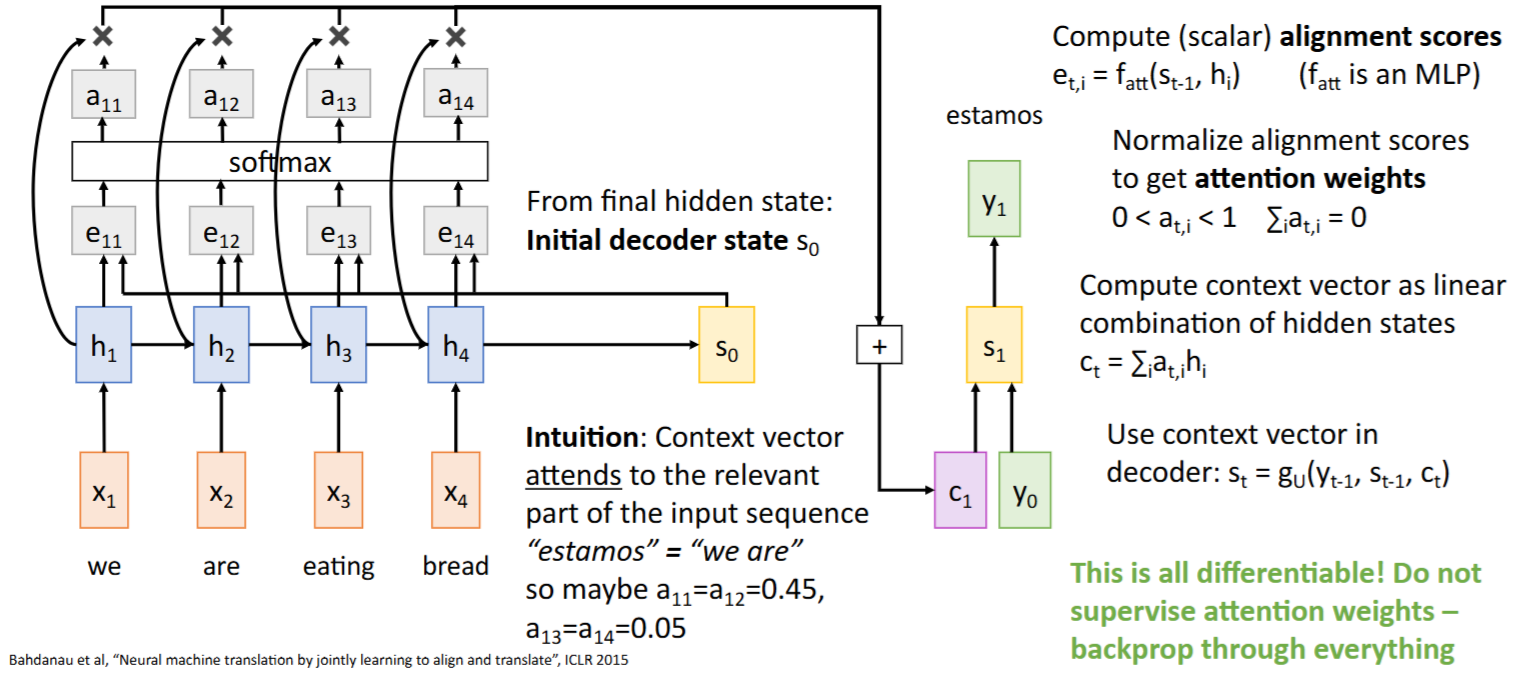
Recap: Encoder最终的隐藏状态(hidden state)
initial decoder state| 解码器初始隐藏状态 context vector| 上下文向量(编码了整个输入序列的信息)
Seq2Seq with RNNs的问题:所有输入序列信息必须压缩到 固定长度的上下文向量(Context Vector) 中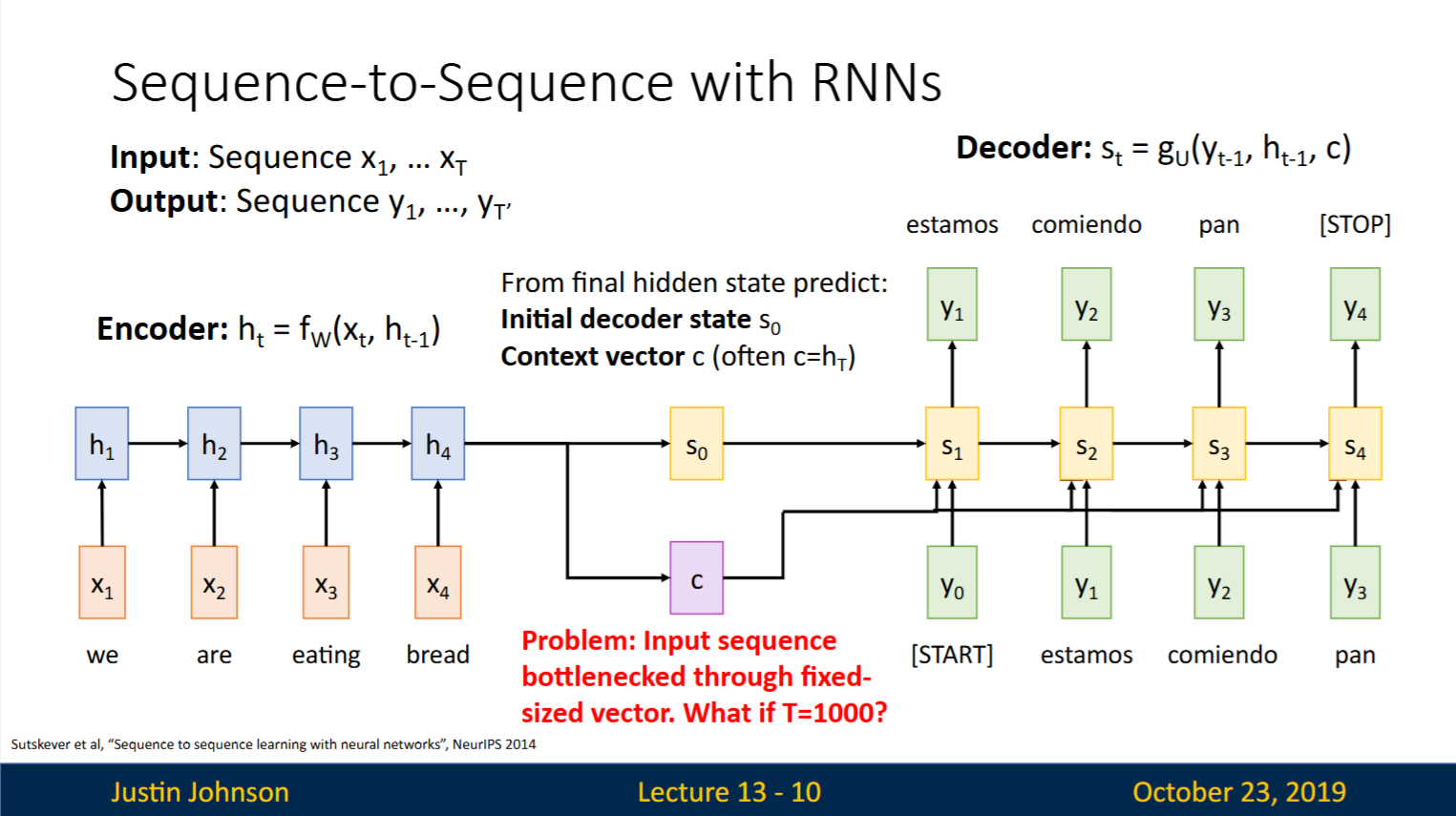
灾难性后果:
- 信息瓶颈问题:长序列时关键细节丢失(”记忆力不足”)
- 对齐能力弱:解码过程各时间步使用相同上下文向量,无法动态关注输入相关部分
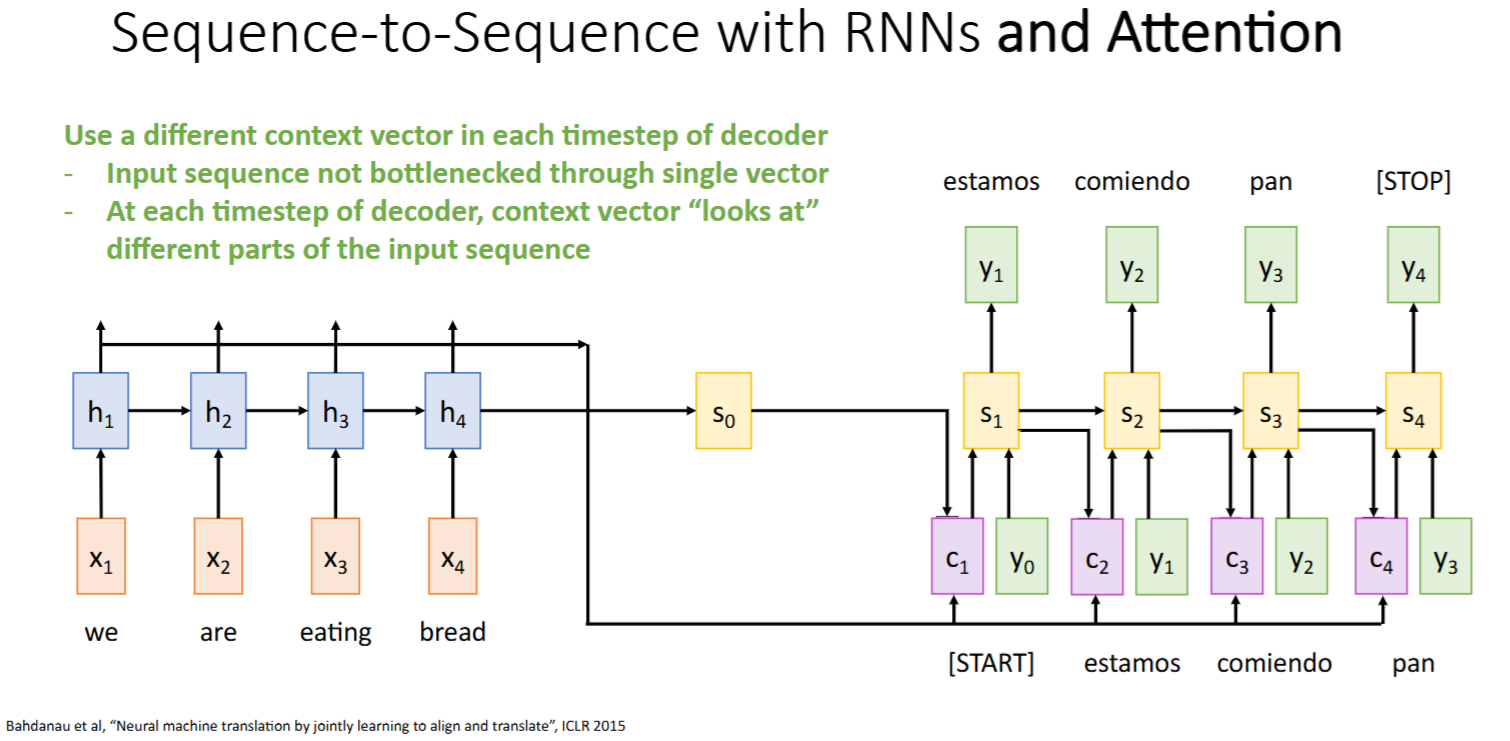
改进方案:RNN + Attention
Intuition: 让模型在解码的每个时间步使用不同的
context vector,动态关注输入的不同部分Method: 对每个时间步
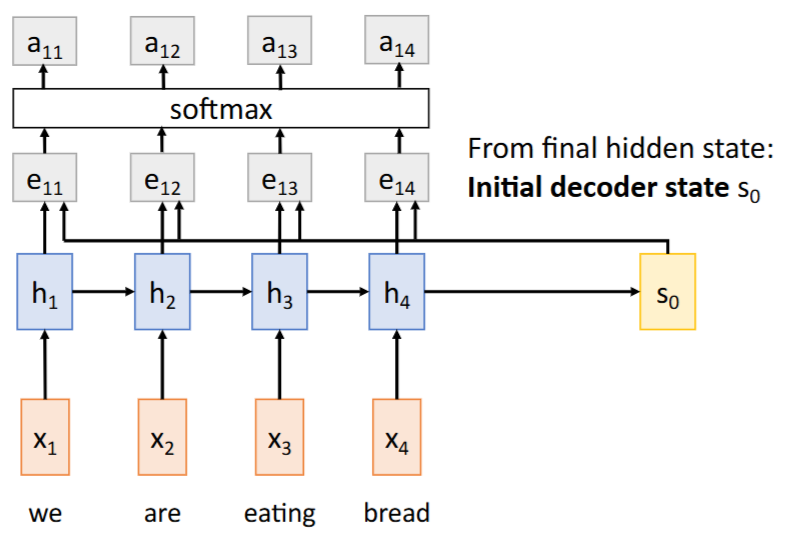
,计算一个 context vector,该向量是输入序列所有hidden states 的加权和 Steps:
- 将前一时间步的hidden state
与输入序列所有hidden states进行 相似度匹配 (is an MLP) -> 得到 与每个hidden states的【相似度/对齐分数( alignment scores)】

- 使用softmax函数将这些相似度/对齐分数(
alignment scores) 归一化为 -> 每个hidden states对应的【注意力权重(attention weights)】
- 每个hidden states与对应的【注意力权重(
attention weights)】相乘求和 -> 得到当前时间步的【context vector】
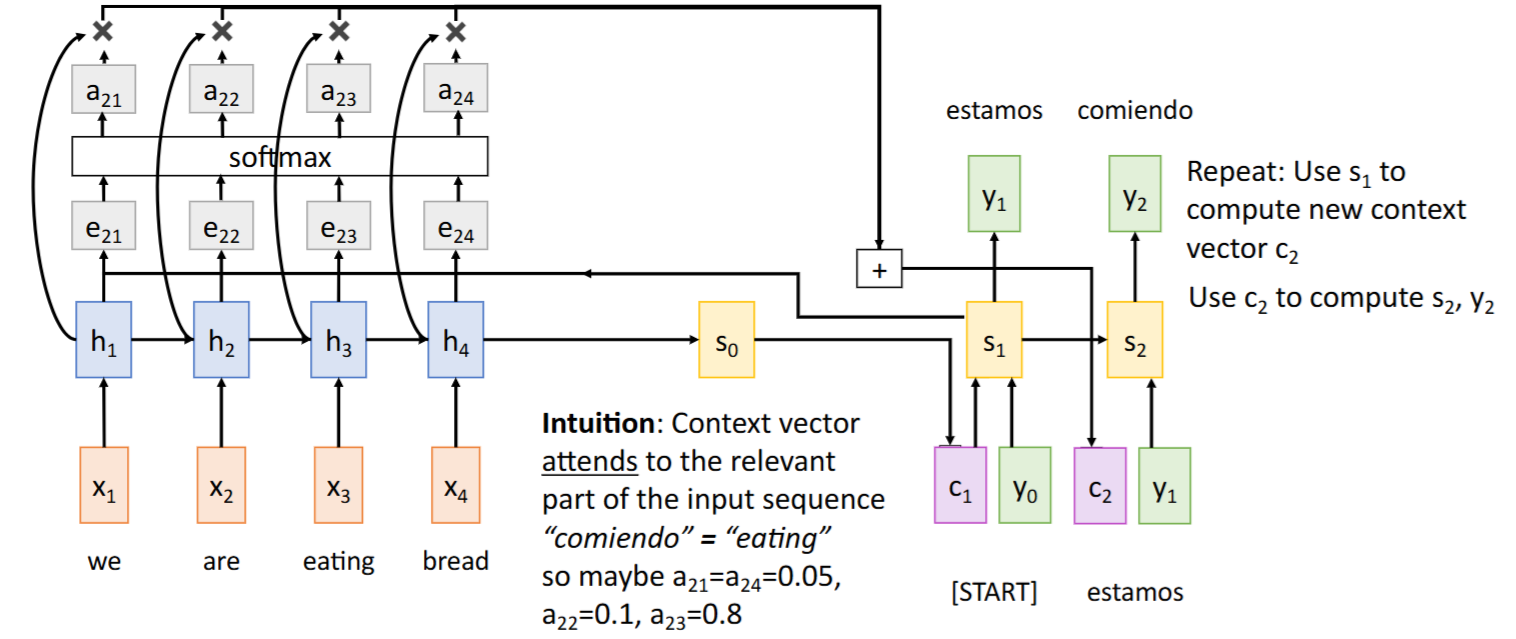
- 重复该过程:
-> , ->
- 将前一时间步的hidden state
注意力权重(
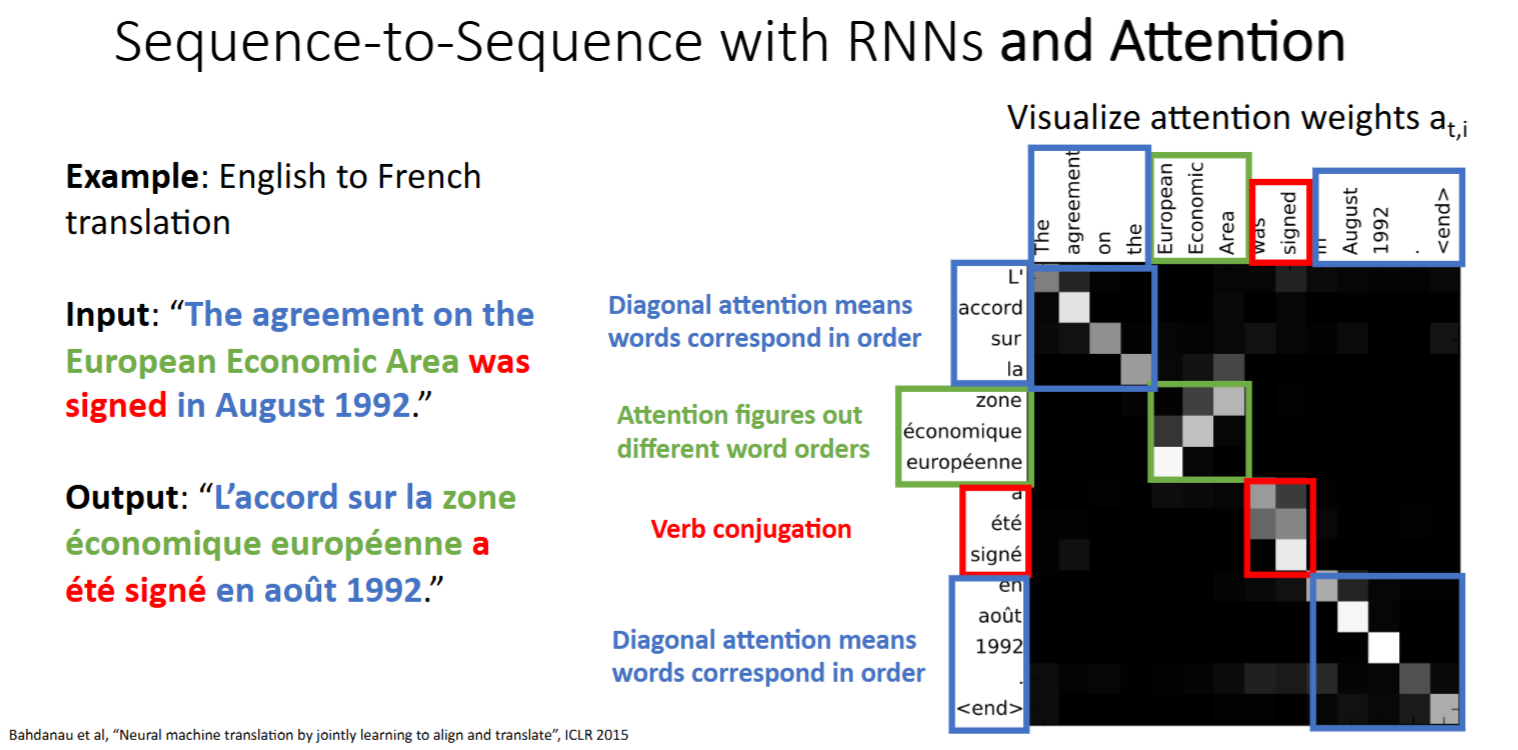
attention weights)可视化:颜色越浅表示注意力权重越大
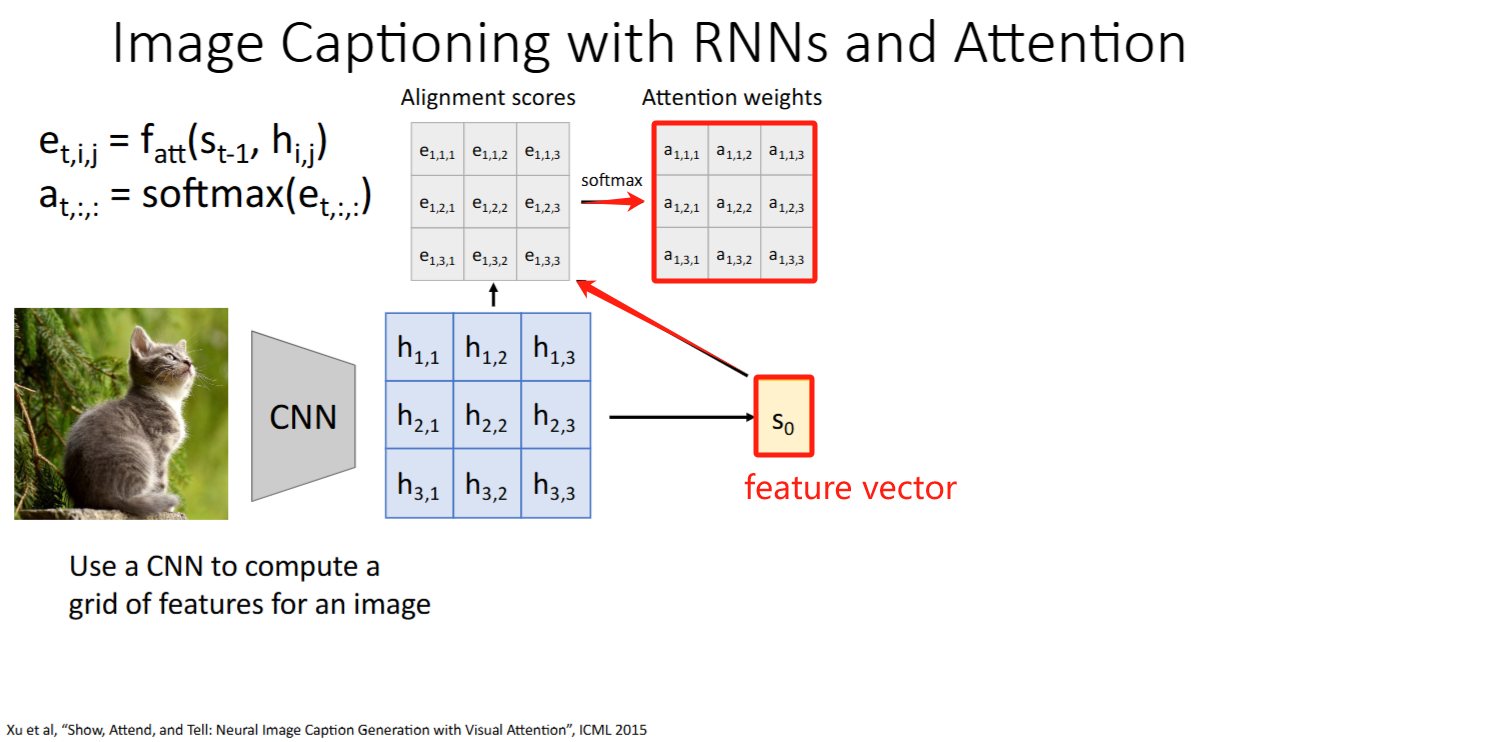
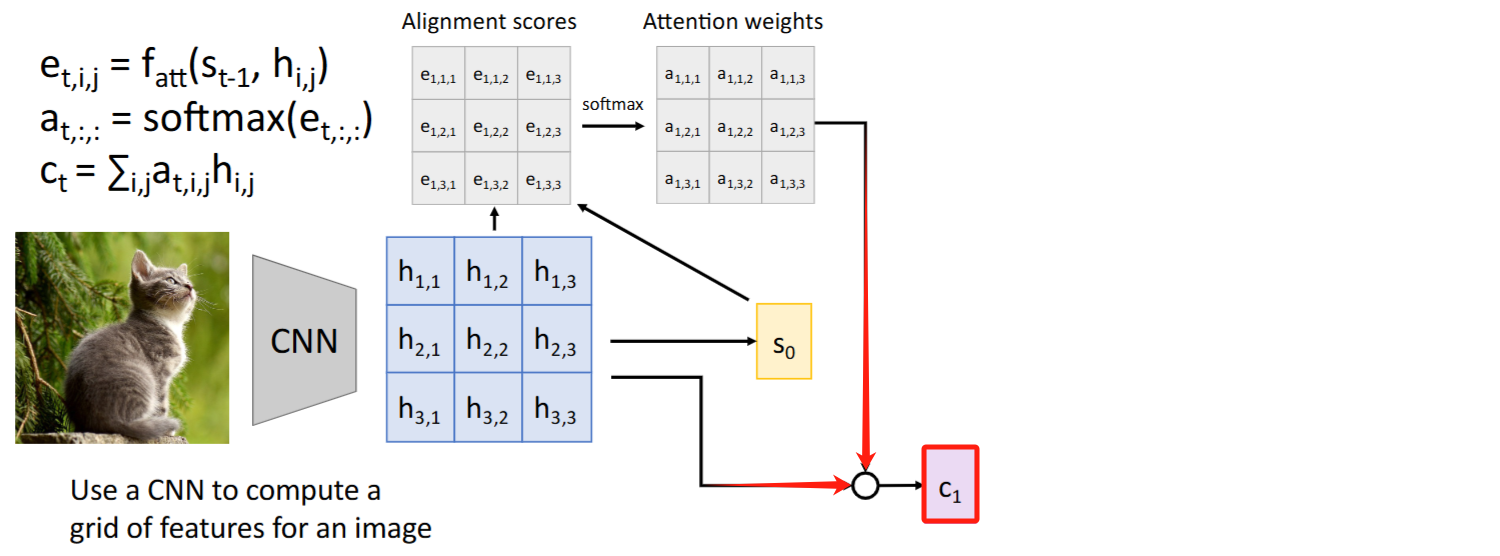
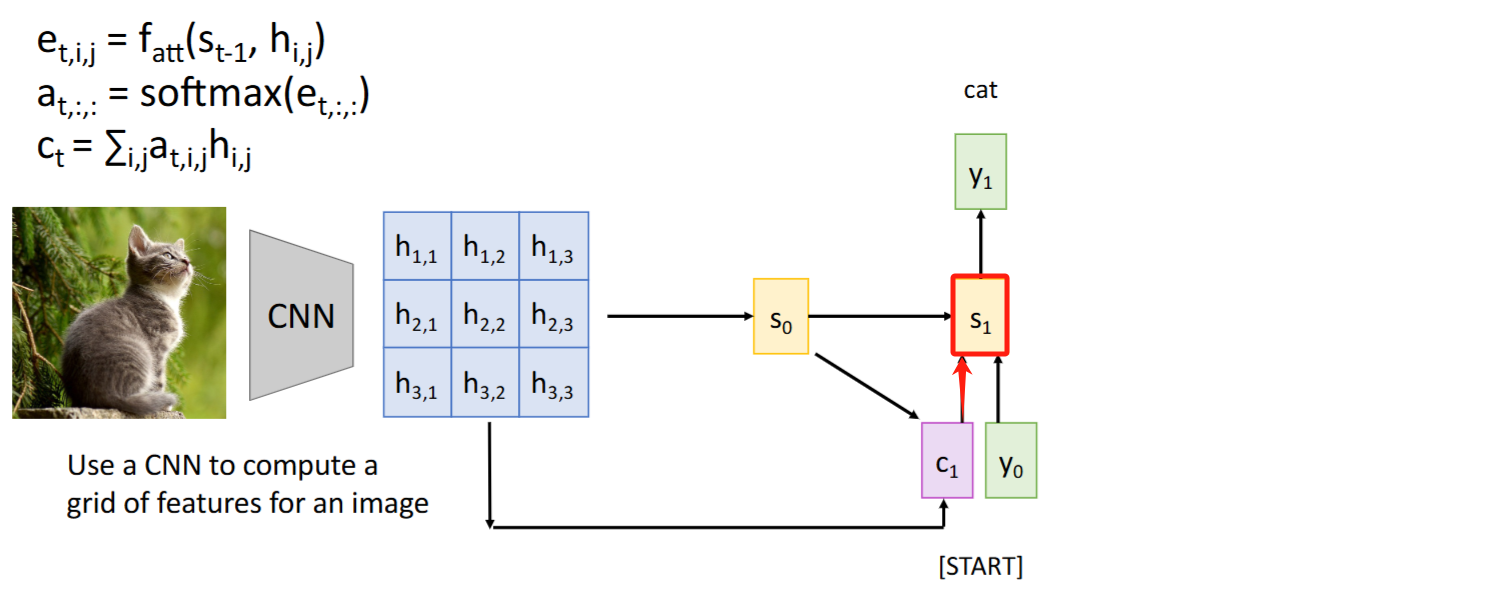
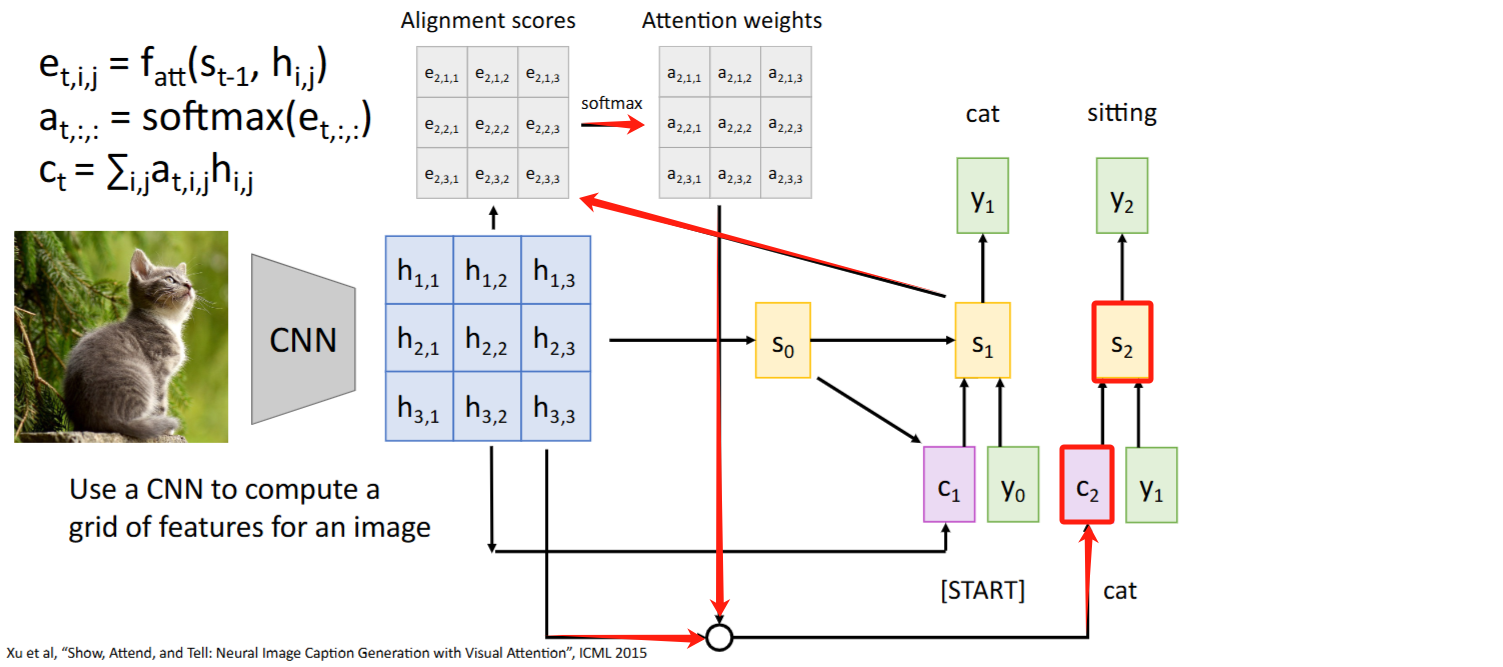
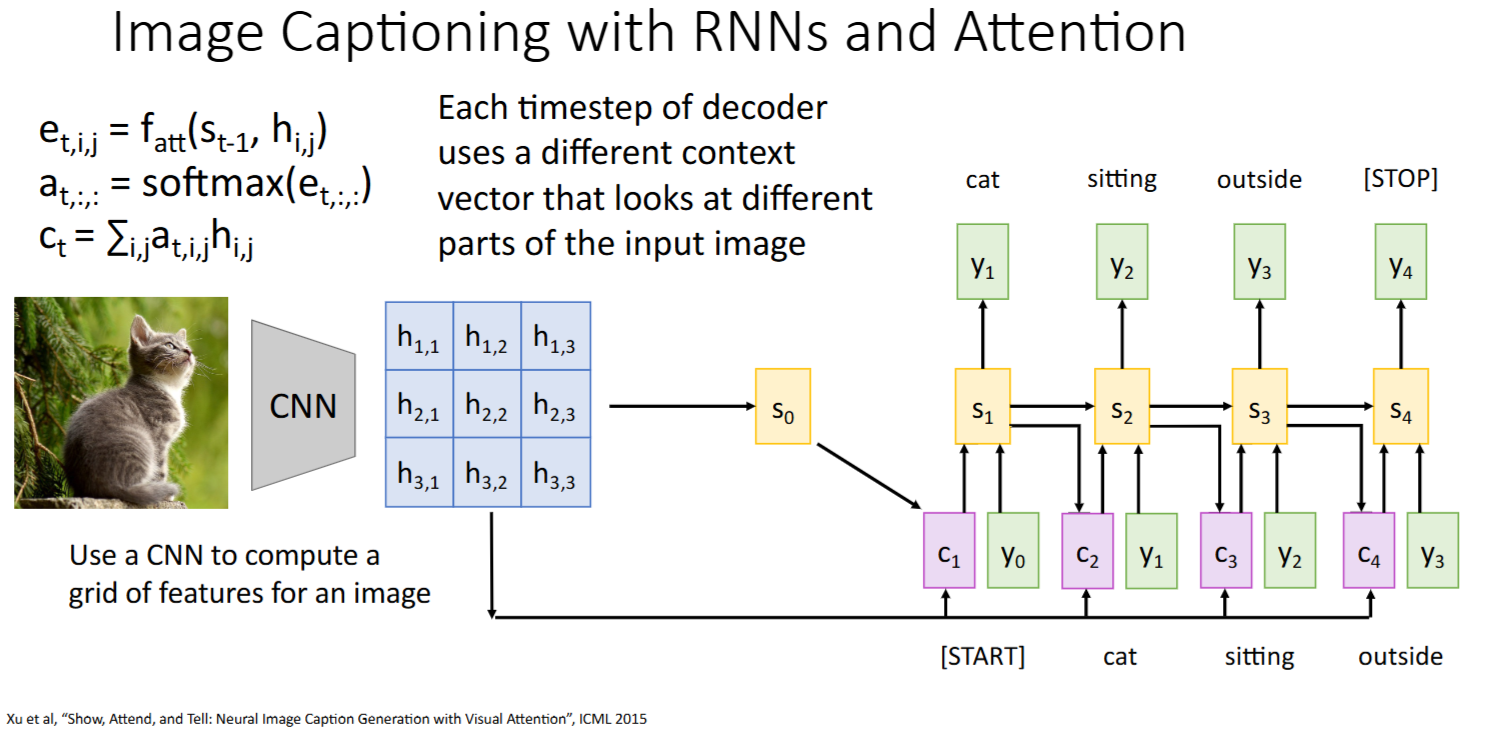
其他模态:CNN + Attention
paper: “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.” pdf
Intuition: 计算
alignment scores和attention weights时,没有把当成【有序sequence】使用,而仅仅作为一个【集合】来处理。因此Attention是否也能迁移到文本外的架构比如图像? Steps:
- 将feature vector
与原始图像的每个grid对比,得到每个grid的 alignment scores和attention weights(细节待阅读paper后修正) - 按
attention weights对grids加权求和得到context vector context vector告诉模型应该关注哪些grid,得到 - 重复该过程:
-> , ->
- 将feature vector
注意力权重(
attention weights)可视化:颜色越浅表示注意力权重越大


生物学联系:Saccade(眼跳动/扫视)
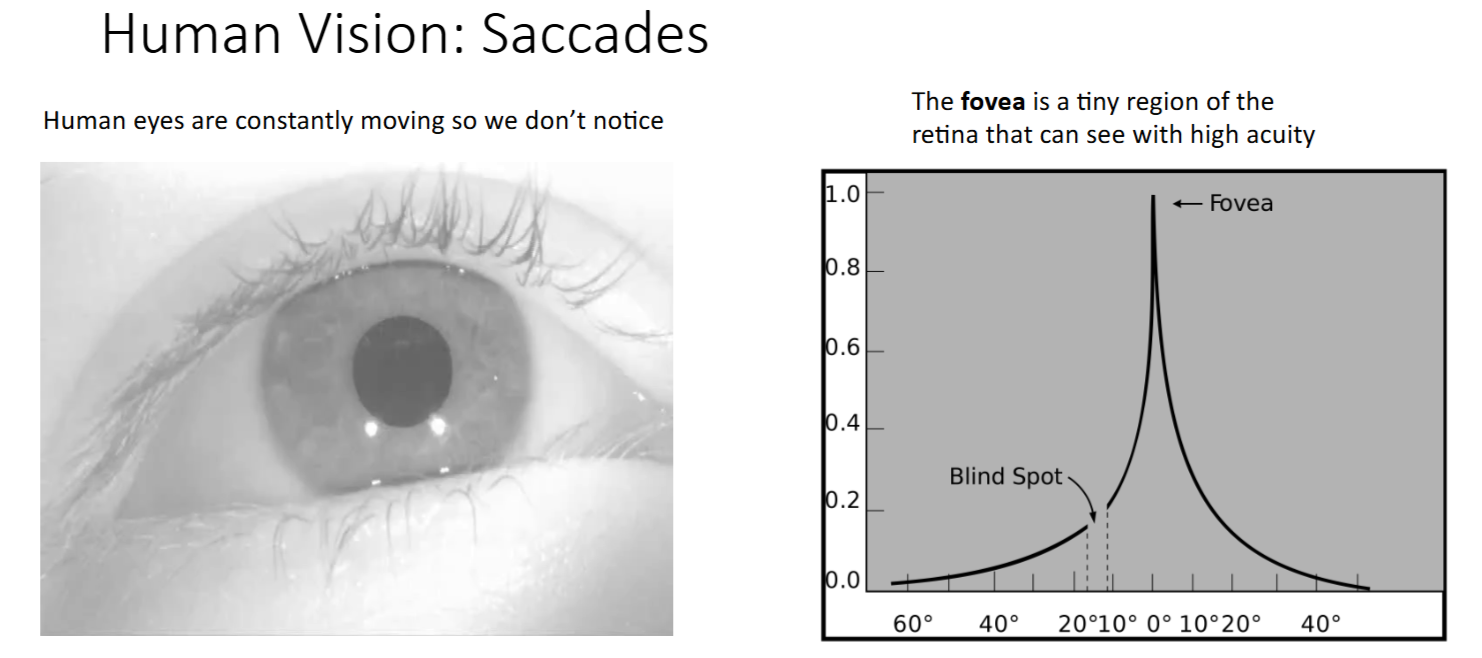
- 人类视网膜正中央部分的视力最好,越往外视力越差
- 高清视野只有中央一小部分
- 例如:当把手掌移动到视野边缘时,我们只能大概感知有一个手掌,而无法感知到具体由多少根手指。
- Saccade(眼跳动/扫视) 是大脑的一种机制,用于快速移动眼球以捕捉视觉信息
- 即使我们尝试专注于看某一点,人眼也会不受控制的持续快速移动
- Attention也是类似,在不同timestep,模型会关注不同的区域/特征
成为趋势:X, Attend, and Y
attend 成为了当年一种流行趋势
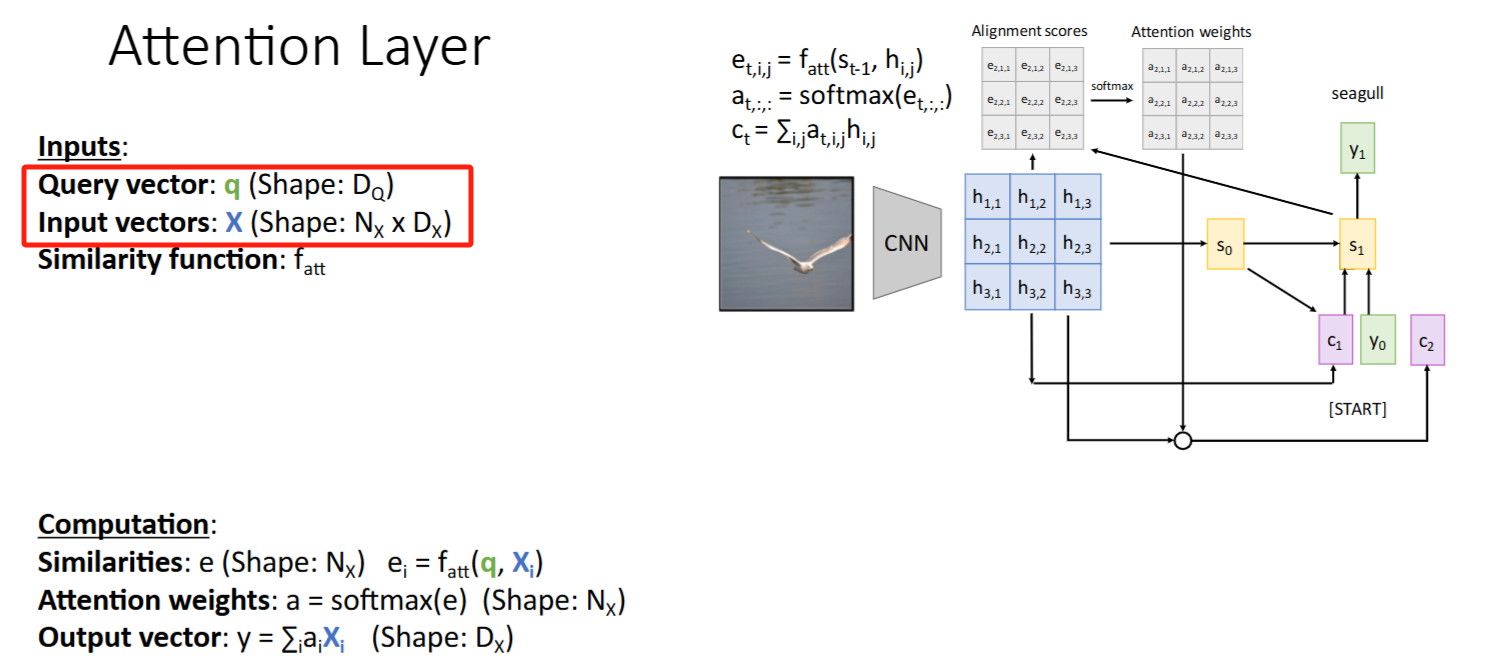
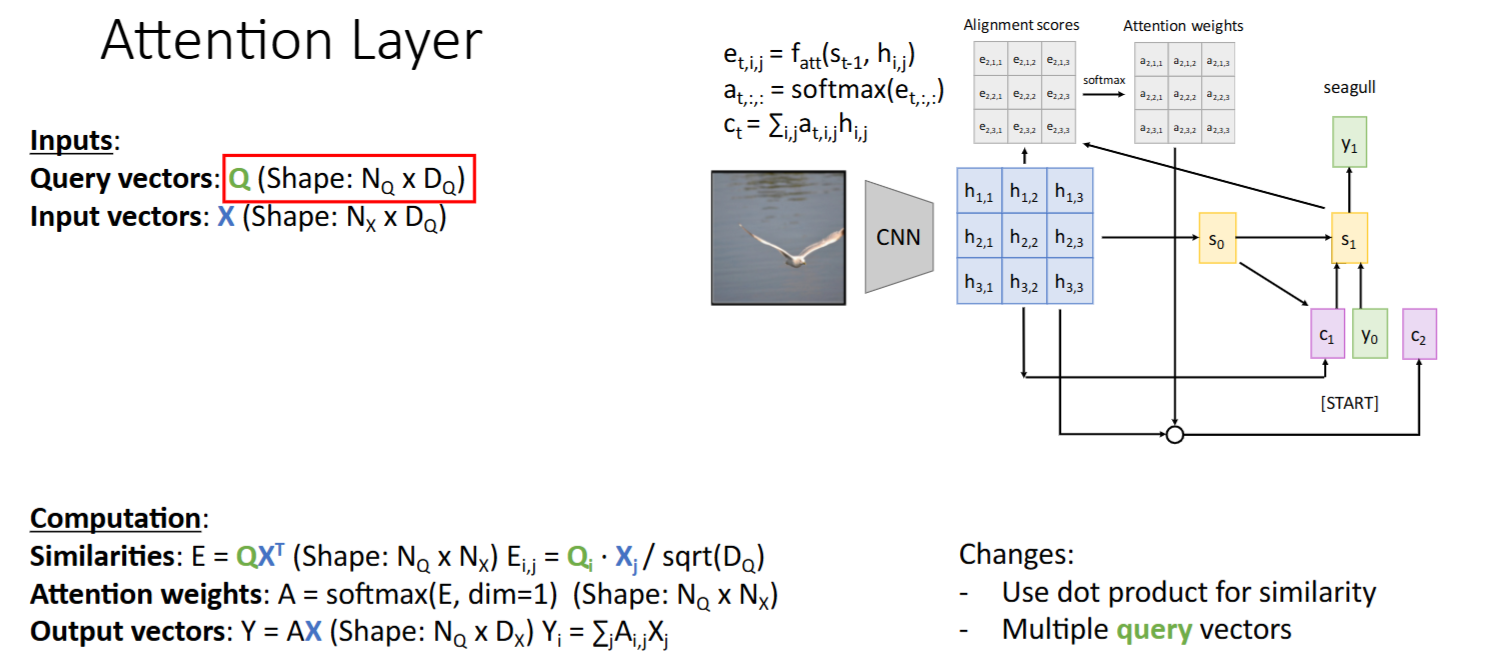
Attention Layer
术语变迁
- 输入:
- decoder state(上一时间步解码器隐状态)
-> Query vector(查询向量) - encoder hidden states(之前需要被attent to的hidden states集合)
-> Input vectors
- decoder state(上一时间步解码器隐状态)
- alignment score ->
attention score

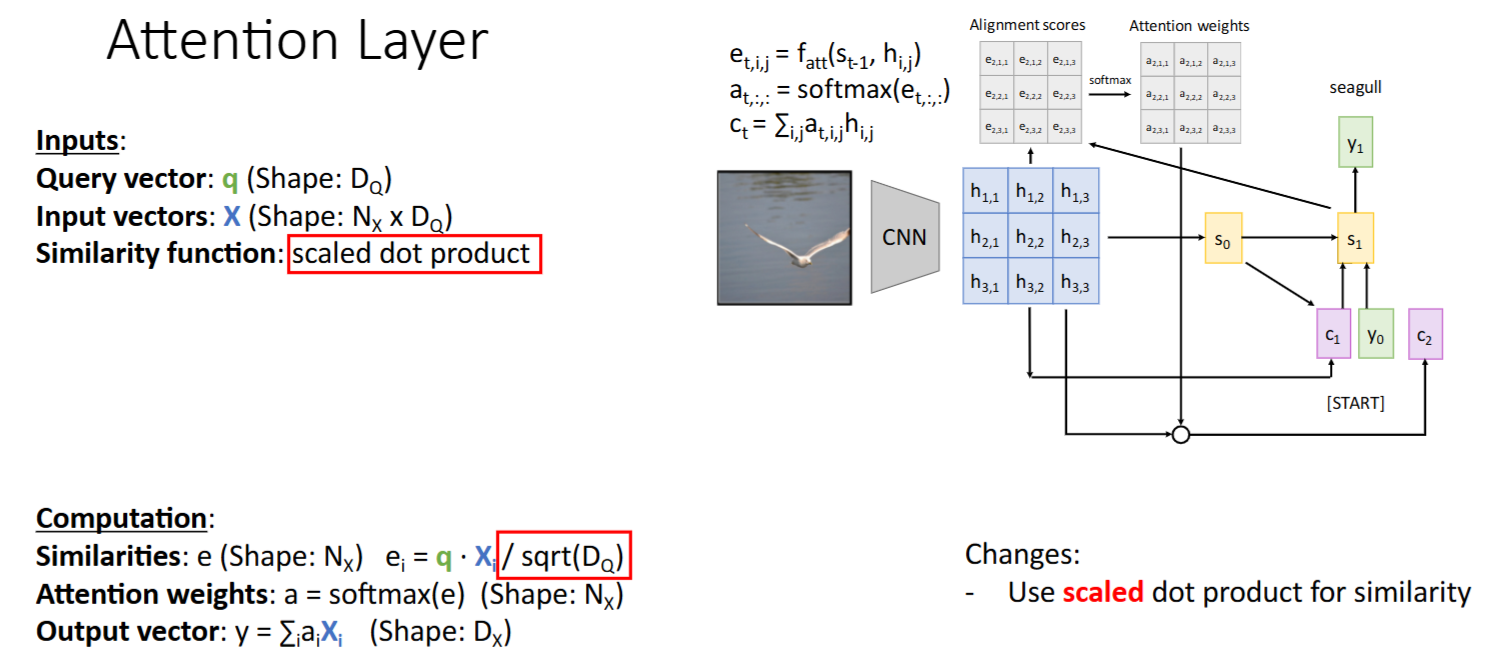
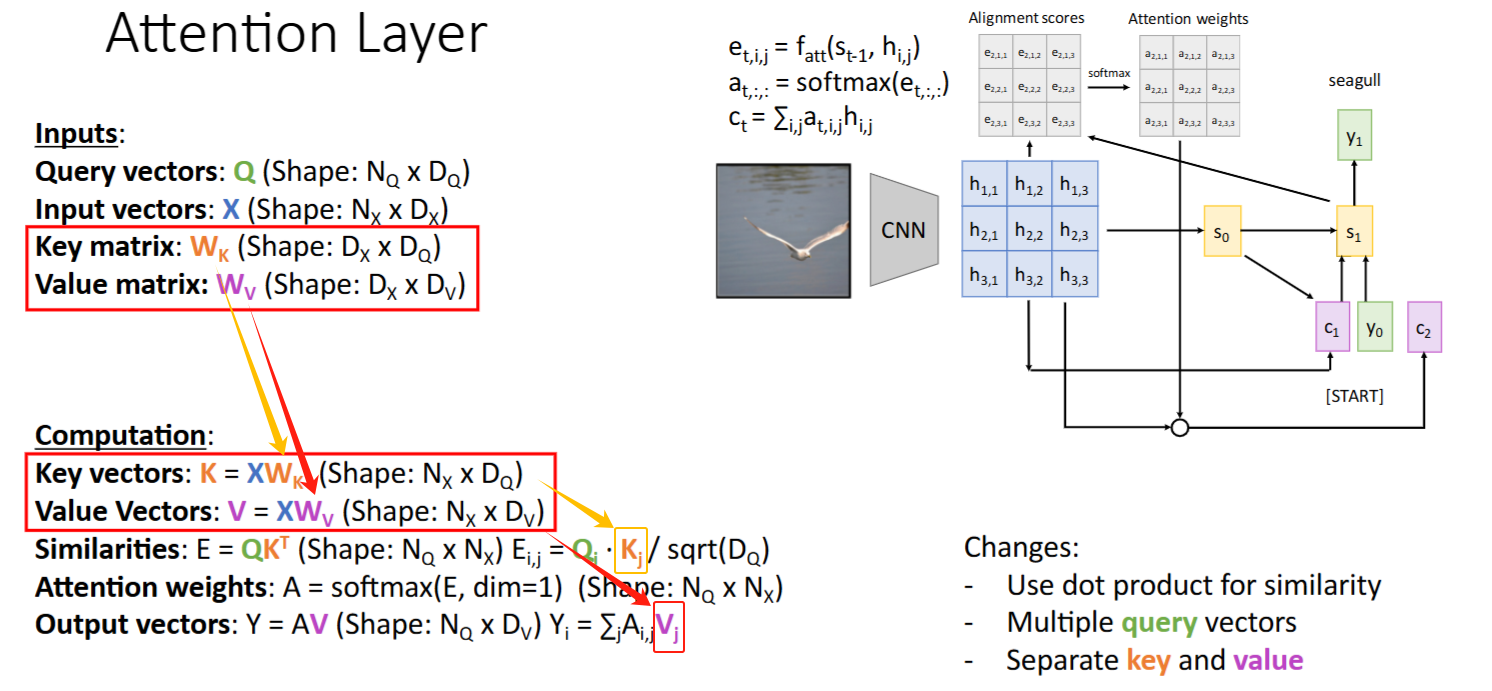
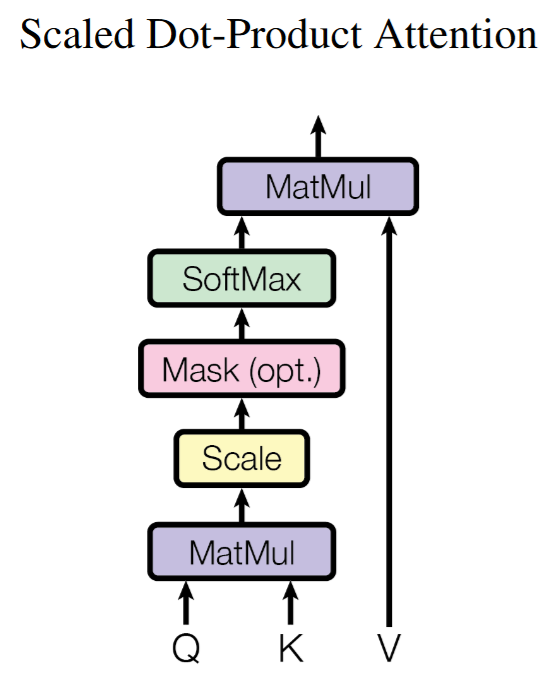
演进过程(缩放点积; Q/K/V)
scaled dot-product(缩放点积):代替 MLP 进行 相似度计算- 为什么用
dot-product? -> 发现 dot-product 的效果和 MLP 的效果一样好,且计算效率更高- 从
additive attention到dot-product attention (multiplicative attention)
- 从
- 为什么要
scaled? -> 特征向量的维数太大时,dot product结果会很大- softmax的梯度敏感
- softmax输出趋近one-hot分布(概率差距指数级放大)
- 导致梯度变得非常小(饱和区的梯度消失现象)
- 数学本质:方差传播定律。例如当q和k的元素是独立均值为0、方差为1时
- 每个元素乘积的期望值:E[qᵢkⱼ] = 0
- 每个元素乘积的方差:Var(qᵢkⱼ) = E[q²]E[k²] = 1
- dₖ维点积的方差:Var(q·k) =
- 标准差:σ =
→ 数值范围随维度膨胀!
- softmax的梯度敏感
- 为什么
scaled的值是? -> 使得点积结果的方差为1,梯度更加稳定 - 使softmax输入值保持适中范围,梯度传播更稳定
- 保证不同维度模型训练的一致性
- 为什么用
Query:把多个query拼接成一个Query矩阵,进行并行运算Key和Value:input vectorsX参与了【两个过程的运算】,可以分离成两个变量Key() 和 Value()。备注: 和 是学出来的。 - Q和
X计算相似度得到 alignment score -> Q 和Key点积得到 attention socre - attention weights 和
X矩阵相乘得到 context vector -> attention weights 和Value矩阵相乘得到 context vector
- Q和
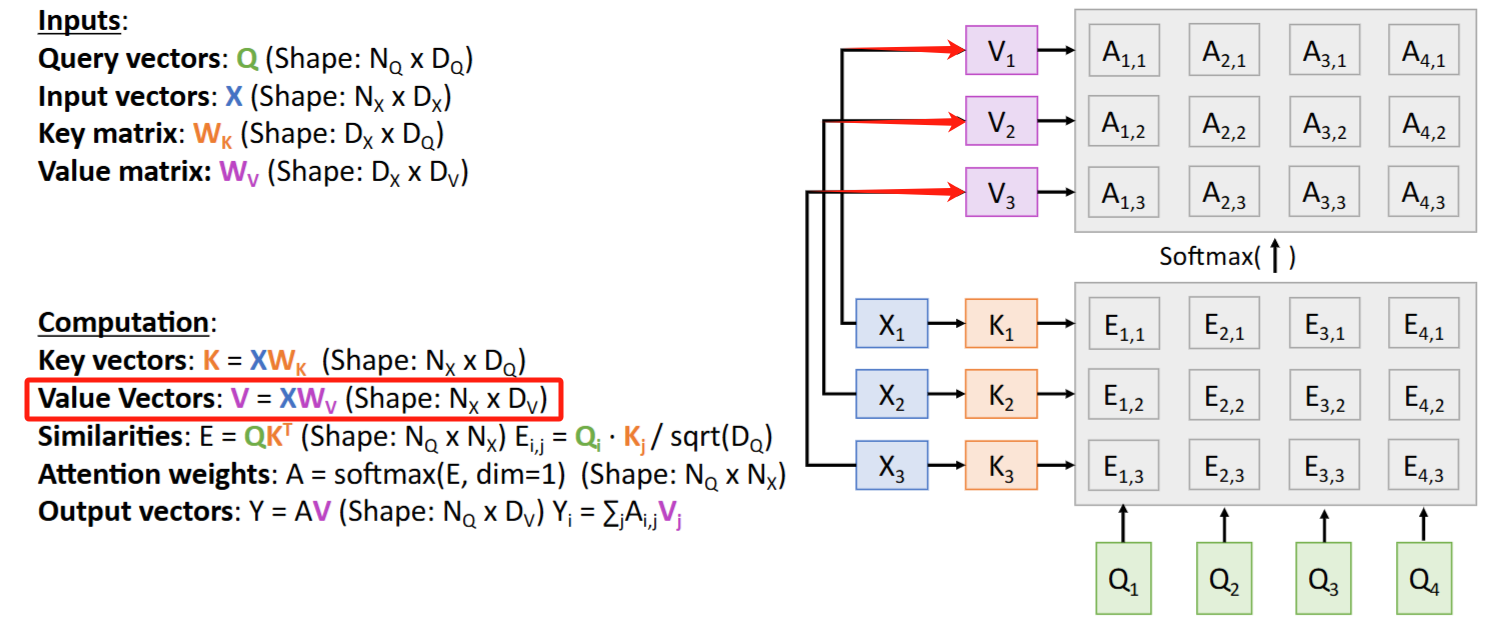
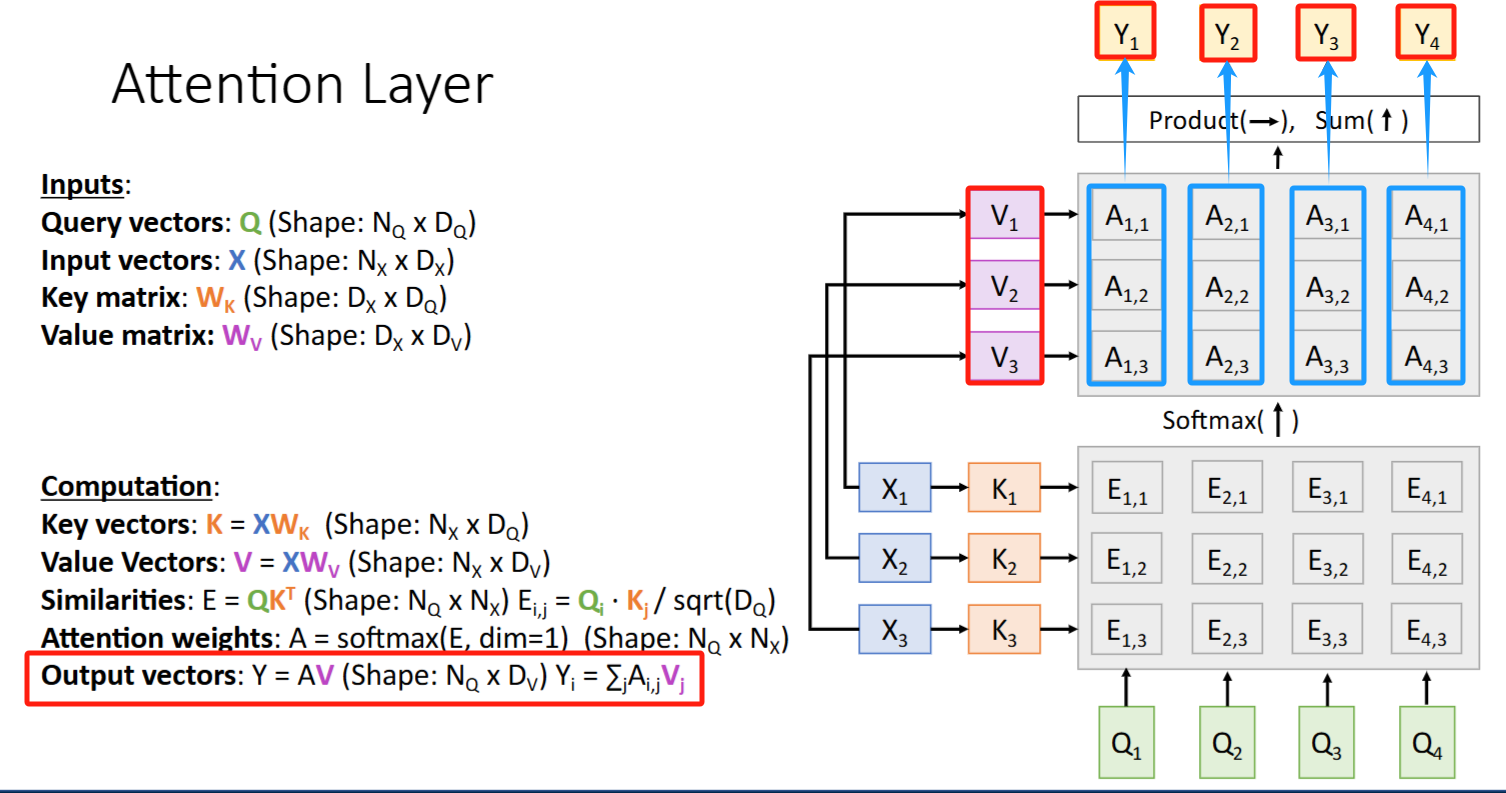
计算流图
- X ->
K - (K, Q) ->
Attention scores-> (softmax) ->Attention weights - X ->
V - (V, Attenton weights) -> outputs
Y


代码示例
1 | def scaled_dot_product_attention(Q, K, V, mask=None): |
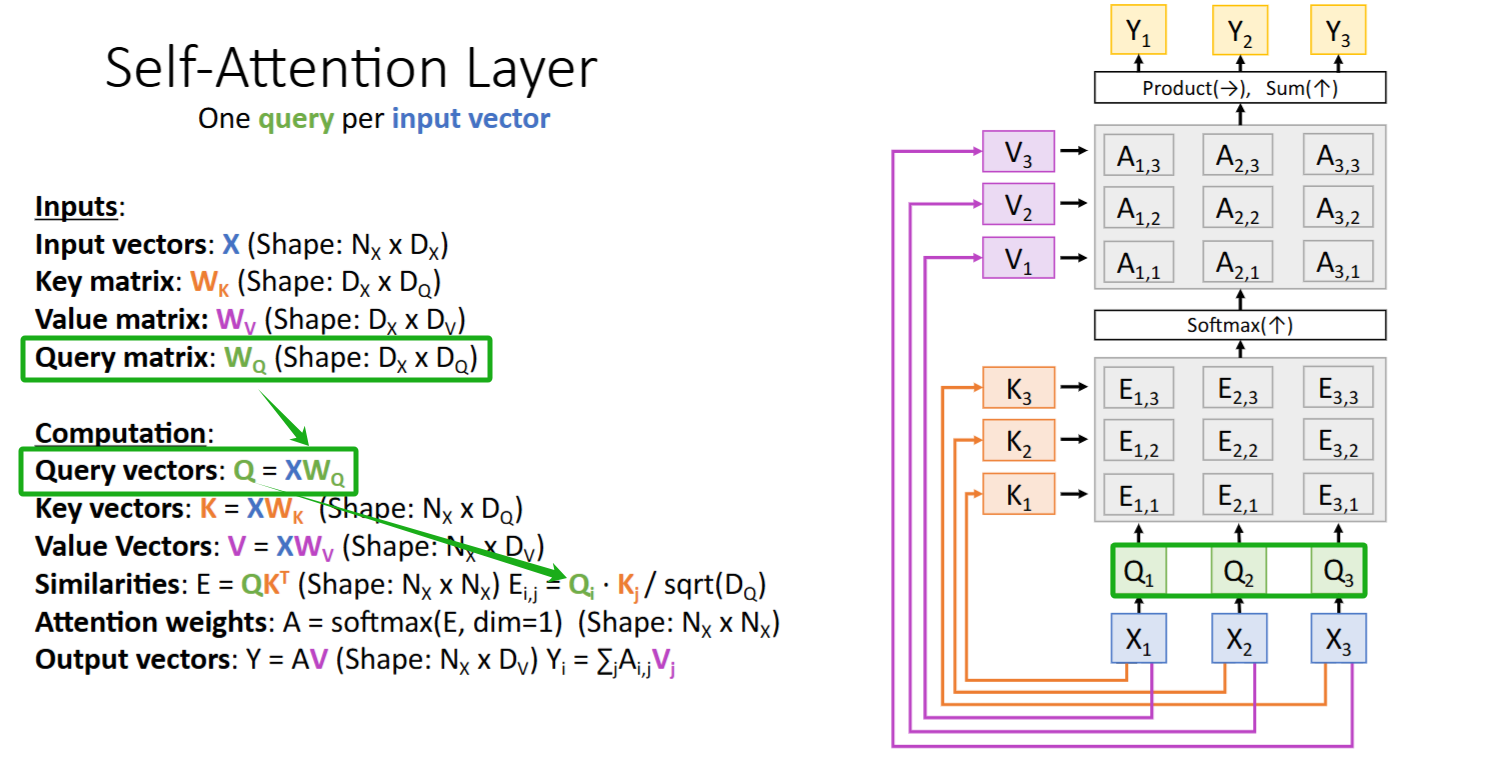
Self-Attention Layer
Attention Layer的一种特殊形式,查询向量Q 也是由 输入X 得到的
- 引入Query matrix:
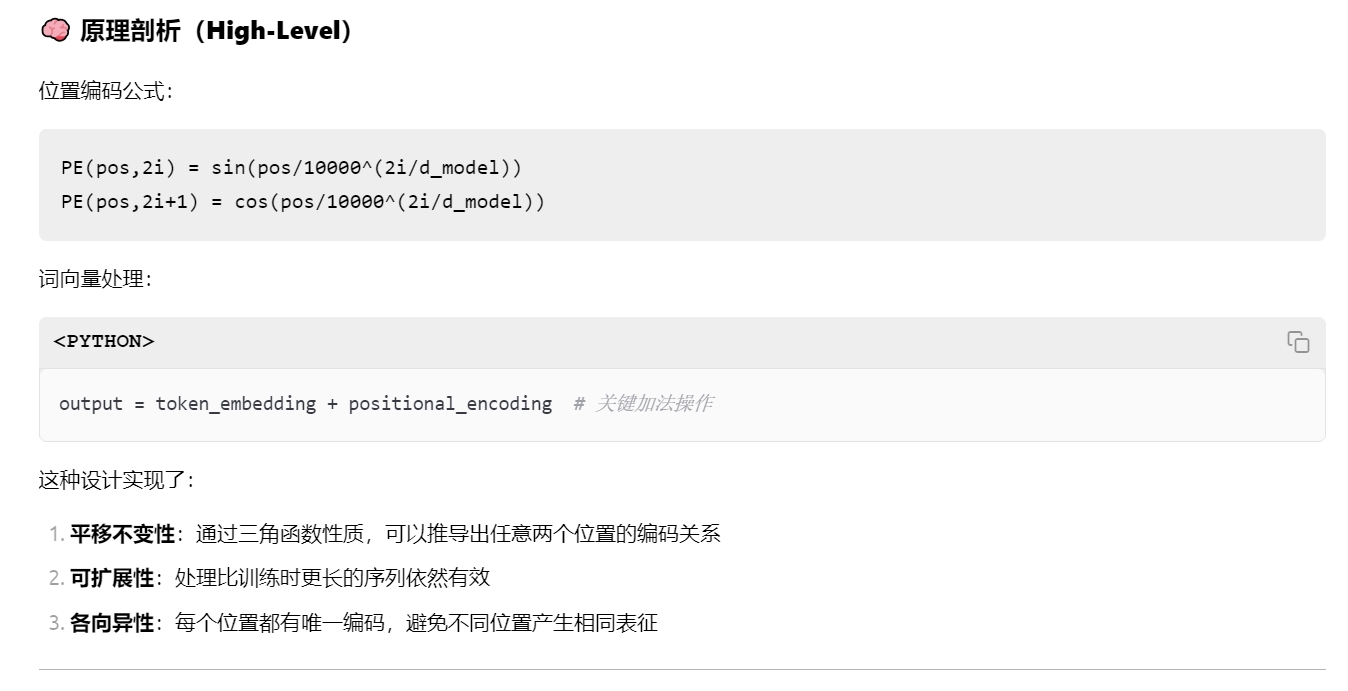
Positional Encoding 位置编码
Self-Attention Layer特性:不关注Order
(当 输入向量x 的顺序改变时,输出y 的顺序也随之改变)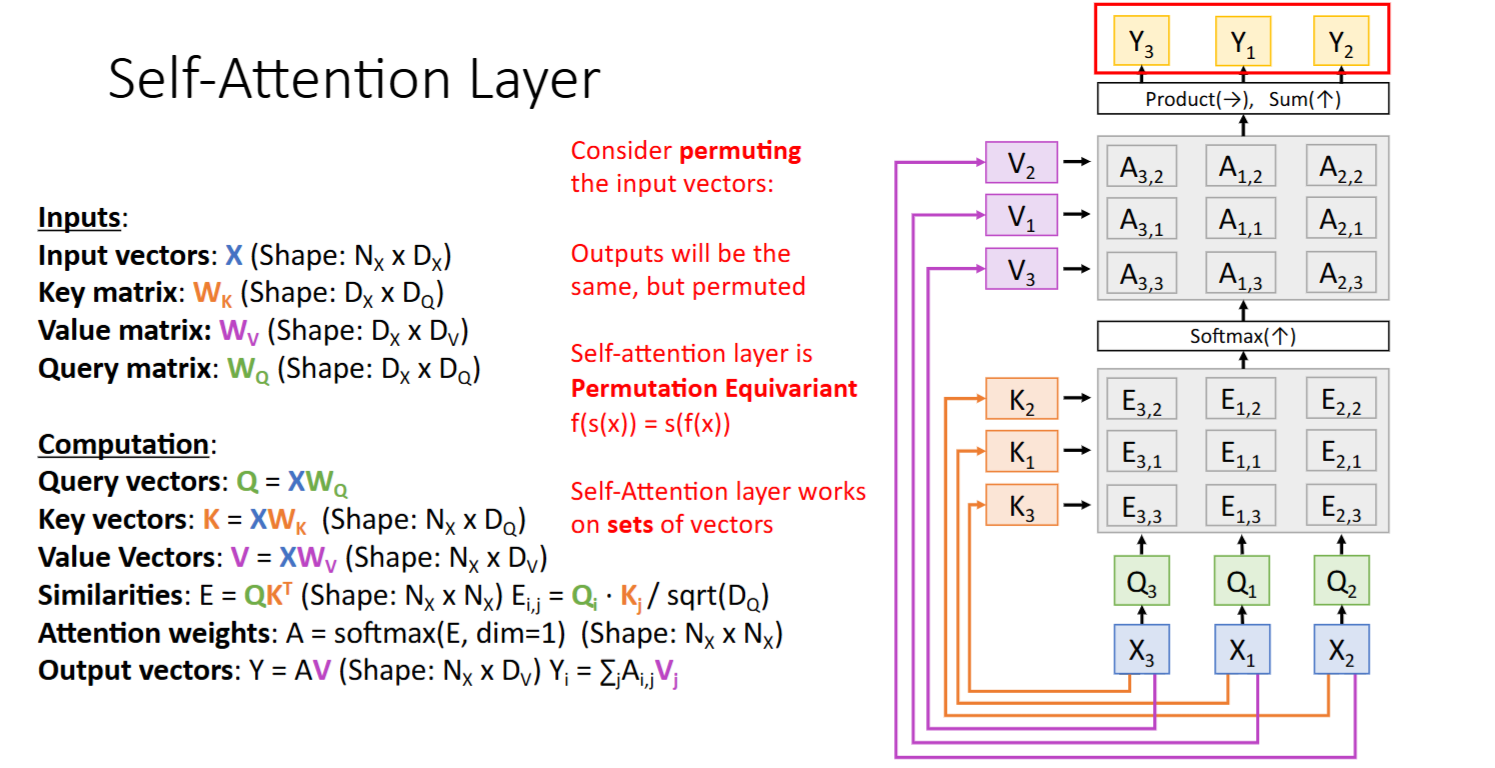
如果希望Self-Attention Layer能够关注Order,需要为输入加入 Positional Encoding(位置编码)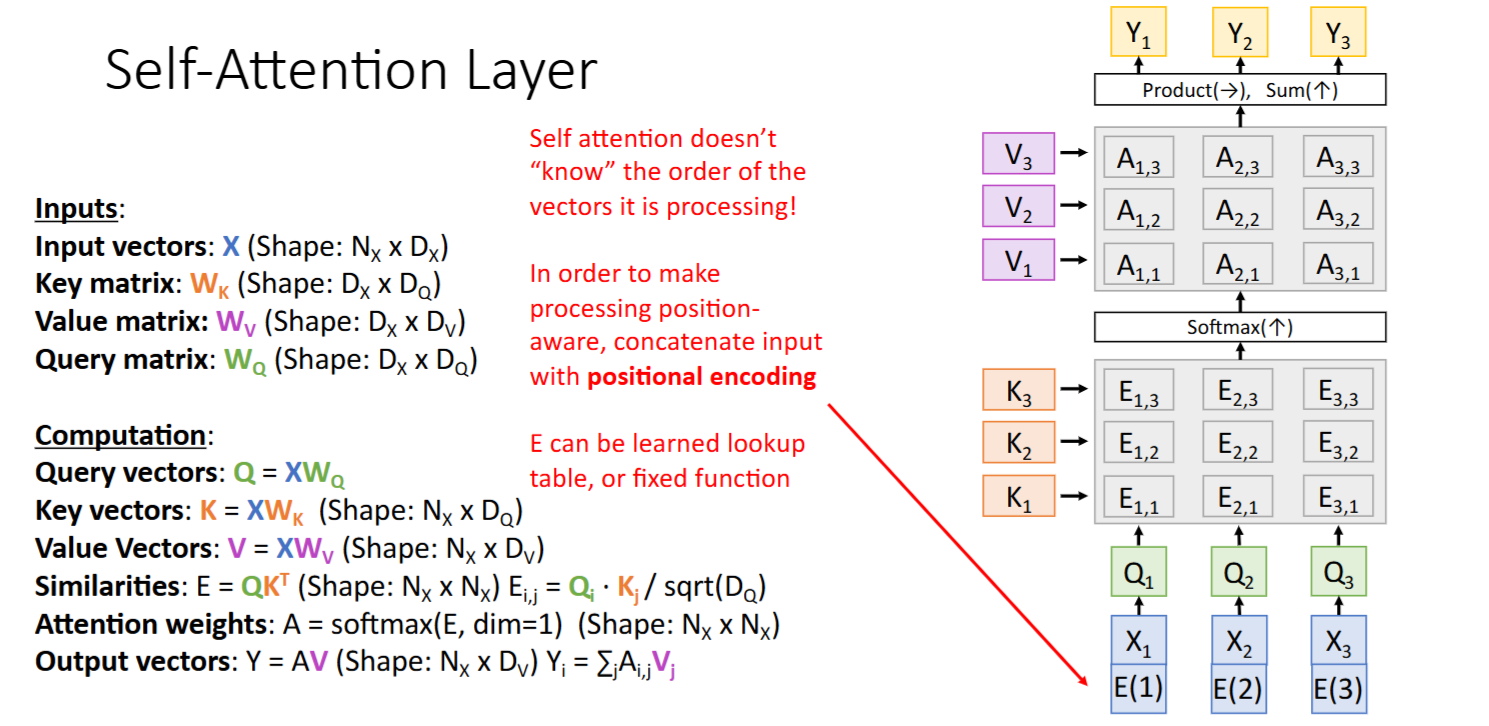
- 加入方式为 ‘concat’(拼接) or ‘add’(与原始向量同维度,加到原始向量上)
- Transformer论文中采用的是 ‘add’ 方式

Masked Self-Attention Layer
对于文本生成,我们只希望模型注意到前面的token
- 后面token的attention weights为0
- 后面token的attention scores为-∞

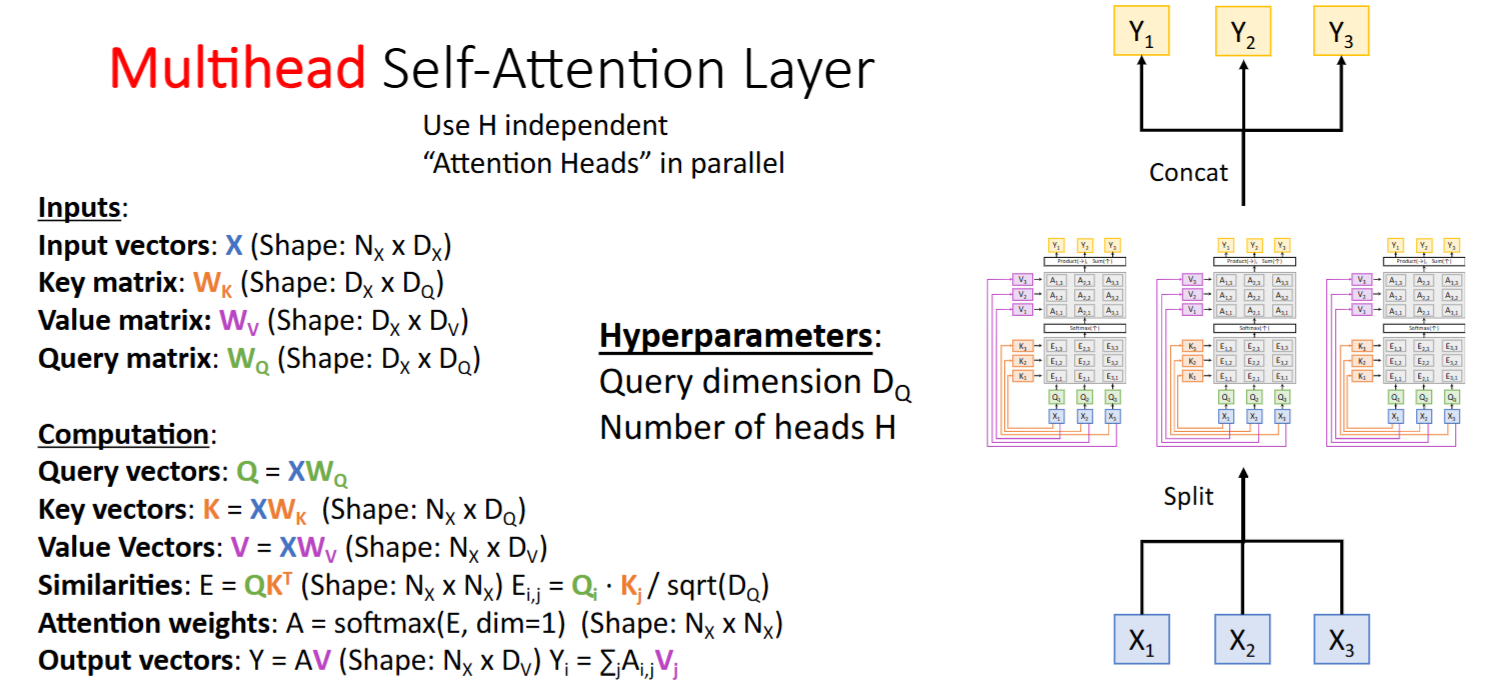
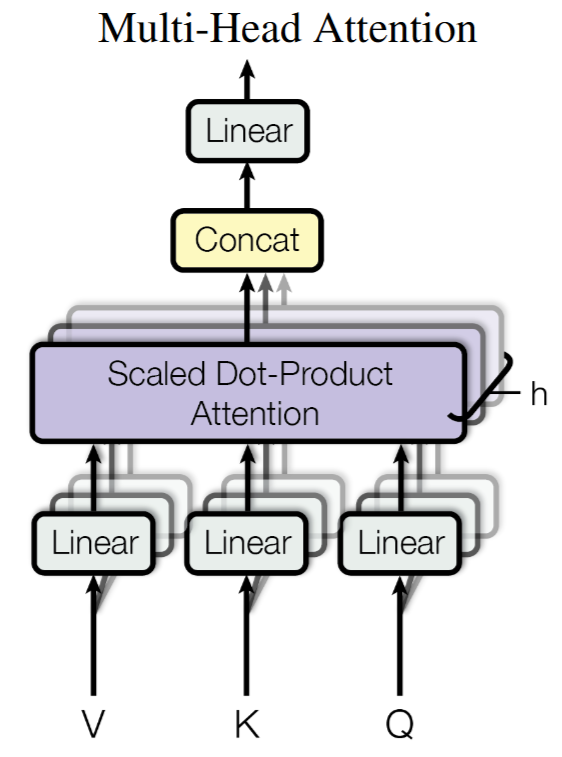
Multihead Self-Attention Layer
代码示例:
1 | # 假设原始输入 x: [batch_size, seq_len, d_model=512] |
⚡ 关键设计亮点:
- 并行独立计算:每个头拥有独立的
/ / 参数(参数量h倍单个头) - 维度利用率:总参数量保持O(d_model²)(拆分不影响参数量级)
- 梯度流动:通过view和transpose操作保持梯度可回传
💡 神经科学启发
这种设计的精妙之处类似人类的分布式认知:
- 每个head就像独立的专家 👩🔬👨💻👩🎨
- Head 1可能捕捉局部语法模式
- Head 2可能关注长程指代关系
- Head 3可能聚焦情感极性词汇
与RNN/CNN架构的比较
eg: CNN + Self-Attention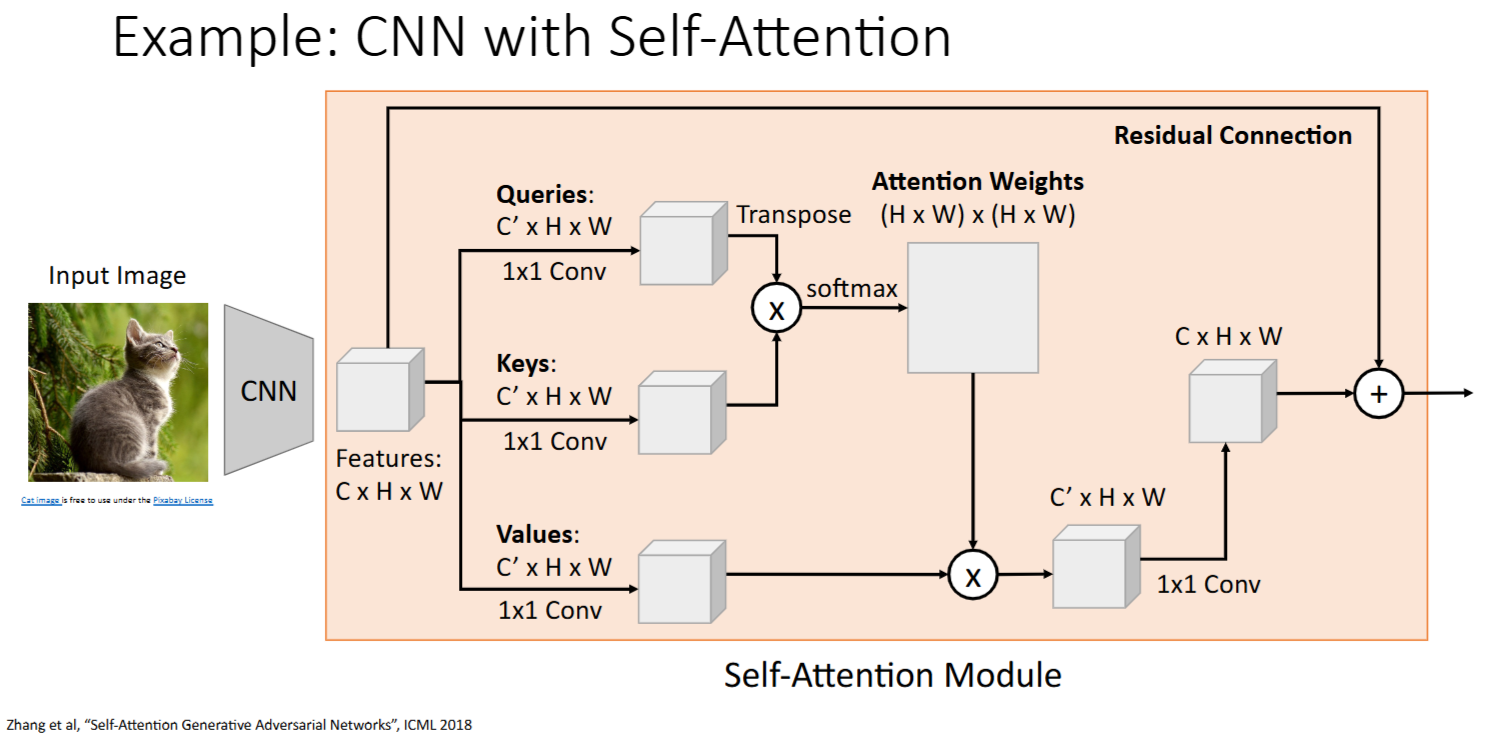
Self-Attention 克服了 RNN/CNN 的不足
RNN可以一定程度上捕获长序列,但无法并行CNN可以并行,但是在长序列上表现不佳Self-Attention既能捕获长序列,又能并行 -> 唯一缺点是 计算/内存密集
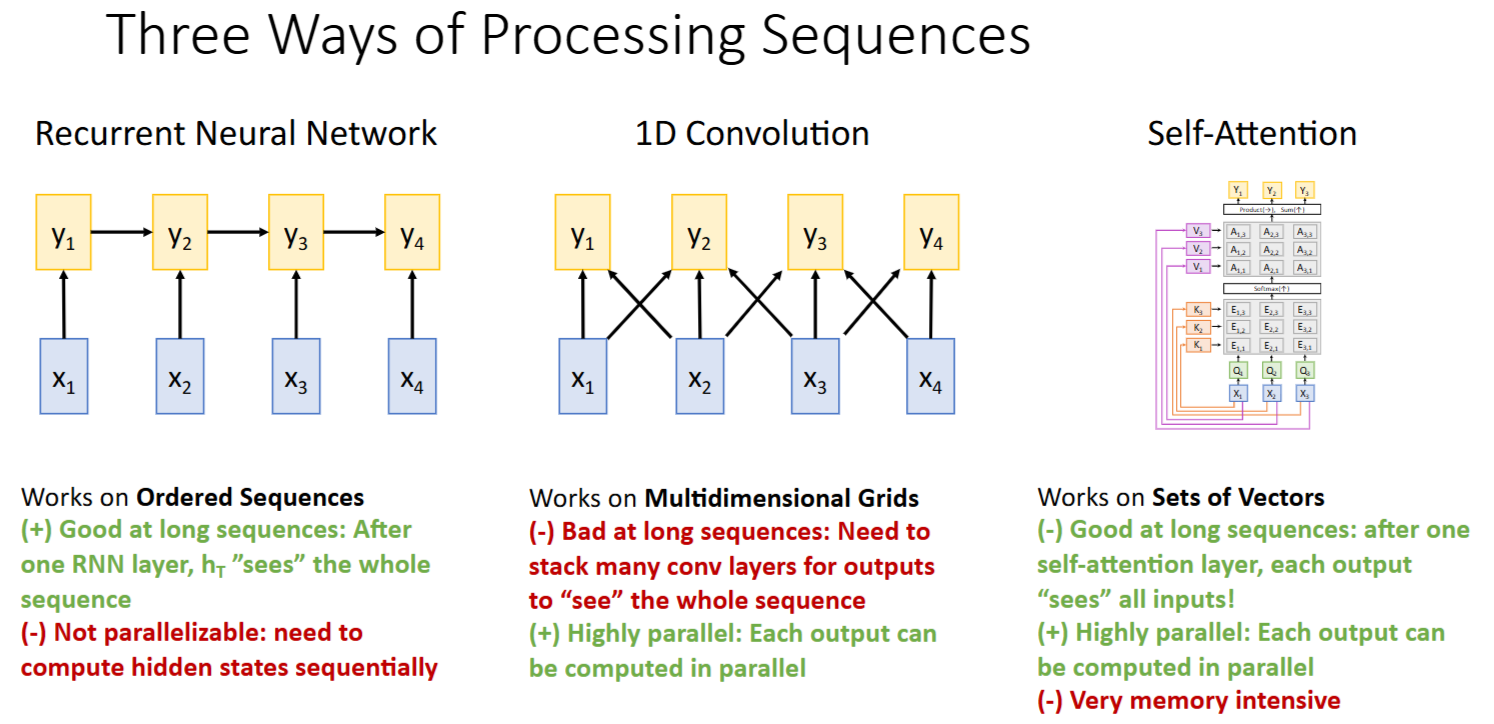
Transformer
- paper: [NIPS’17]”Attention Is All You Need” pdf
- Transformer架构是一个
tranformer block的序列 - “ImageNet Moment for NLP”



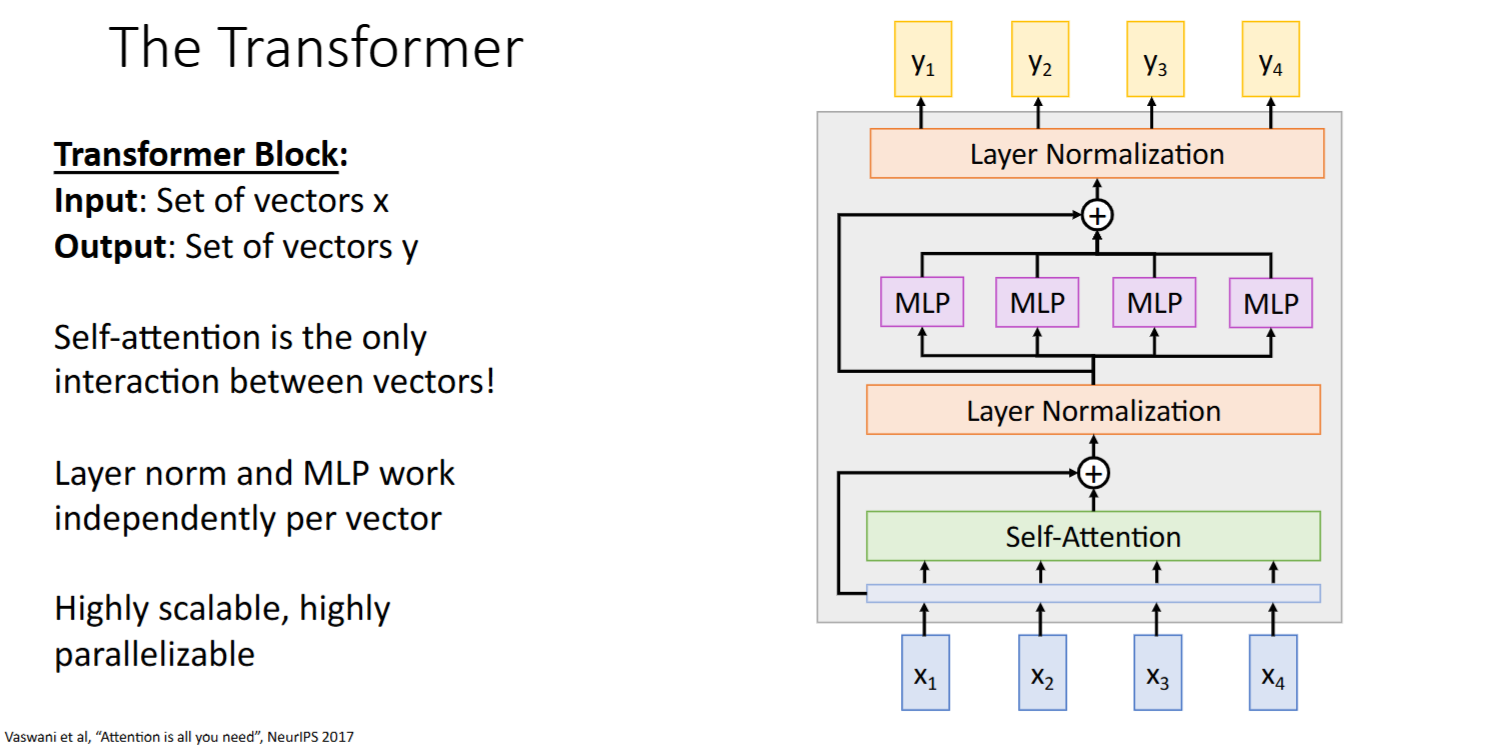
transformer block
结构:
Multi-Head Self-Attention- Add & LayerNorm
Feed Forward- Add & LayerNorm
特性:
- 只有Self-Attention中发生了向量间的交互,其他模块的向量处理都是独立的
- 高扩展高并行
Transformer的迁移学习
- 先在大量互联网文本上做无监督预训练
- 再在特定任务上做Finetuning

eg: 文本续写
Scaling up
模型越大效果越好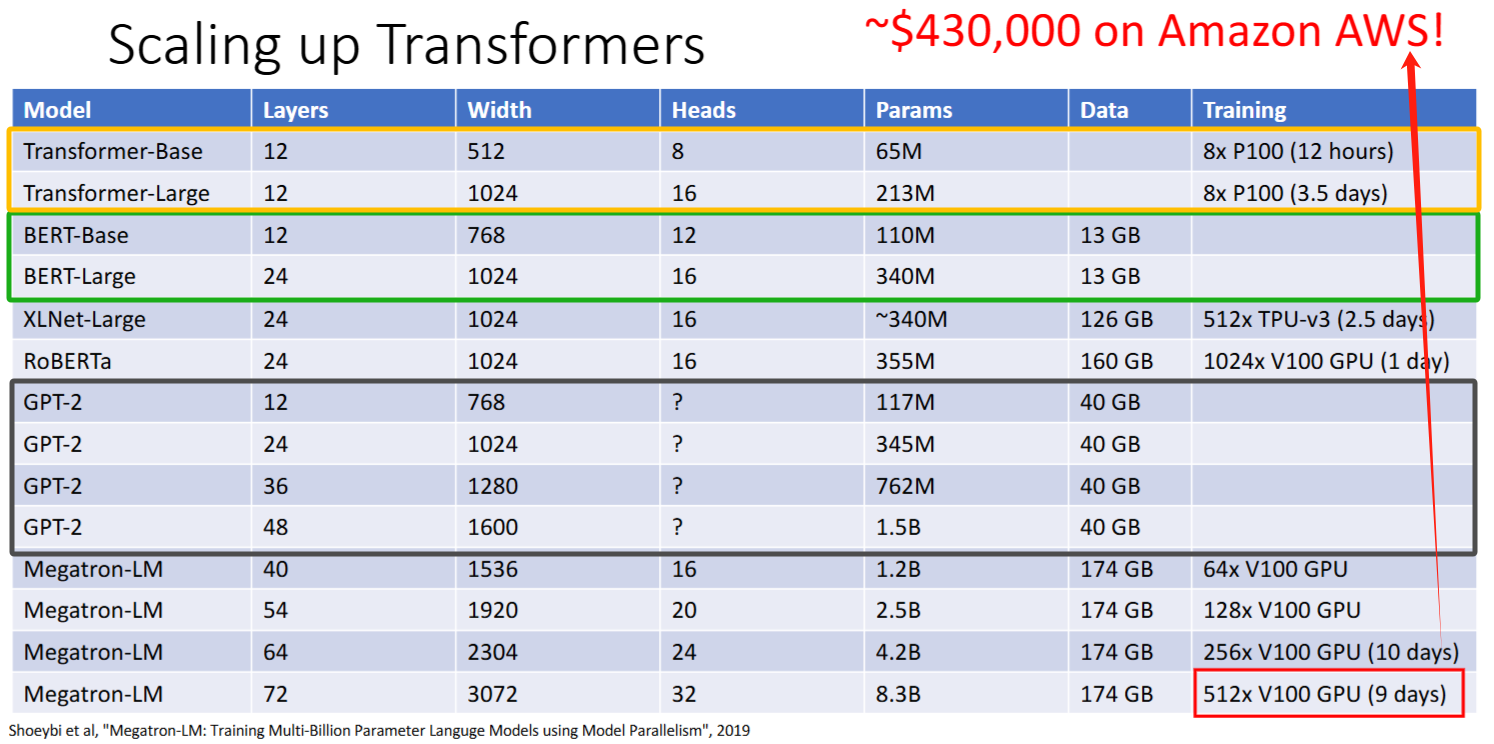
- Title: [EECS498/598] lecture 13: Attention(注意力机制)
- Author: LeoJeshua
- Created at : 2025-01-01 08:13:00
- Updated at : 2025-03-10 20:24:01
- Link: https://leojeshua.github.io/Course/eecs498/eecs498-13/
- License: This work is licensed under CC BY-NC-SA 4.0.