![[EECS498/598] lecture 15: Object Detection(目标检测)](https://raw.githubusercontent.com/LeoJeshua/PicGo/main/images/20241227205140.png)
[EECS498/598] lecture 15: Object Detection(目标检测)
lecture 15: Object Detection(目标检测)
slide: https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture15.pdf
- Two-stage detectors
- Single-stage detectors
Recap:
计算机视觉三大任务:
图像分类 Image Classfication(7,8讲)目标检测 Object Detection(15讲)图像分割 Image Segmentation(16讲)
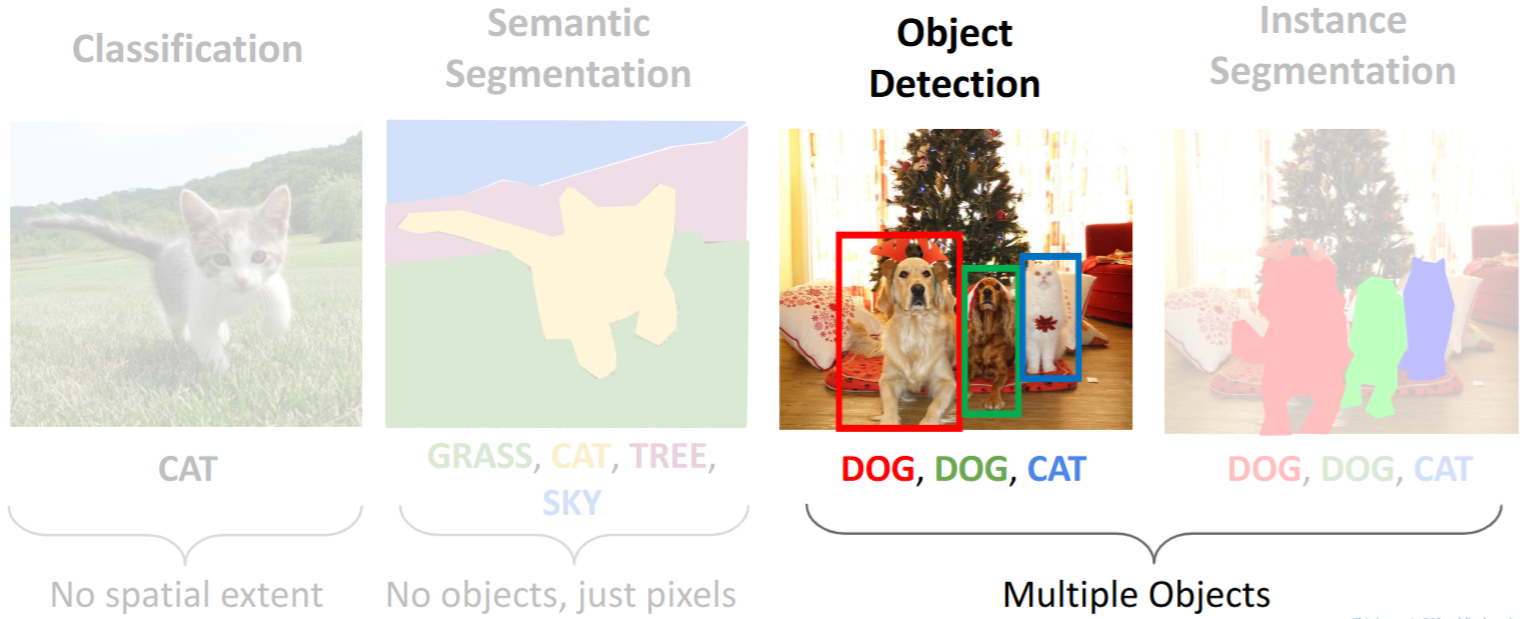
目标检测
- 任务定义
- Input: 一张RGB图像
- Output: 检测到的Objects的集合。每个Object包含:
Category label从已知的【固定类别集合】里选择的一个【类别标签】Bounding box (x,y,width,height)【边界框】的位置和大小
- 挑战:
- 多个输出数量(每张图像objects个数不同)
- 多种输出类型(category label + bounding box)
- 更大的输入图像(相比分类任务)


15.0 早期探索
(直观思路)
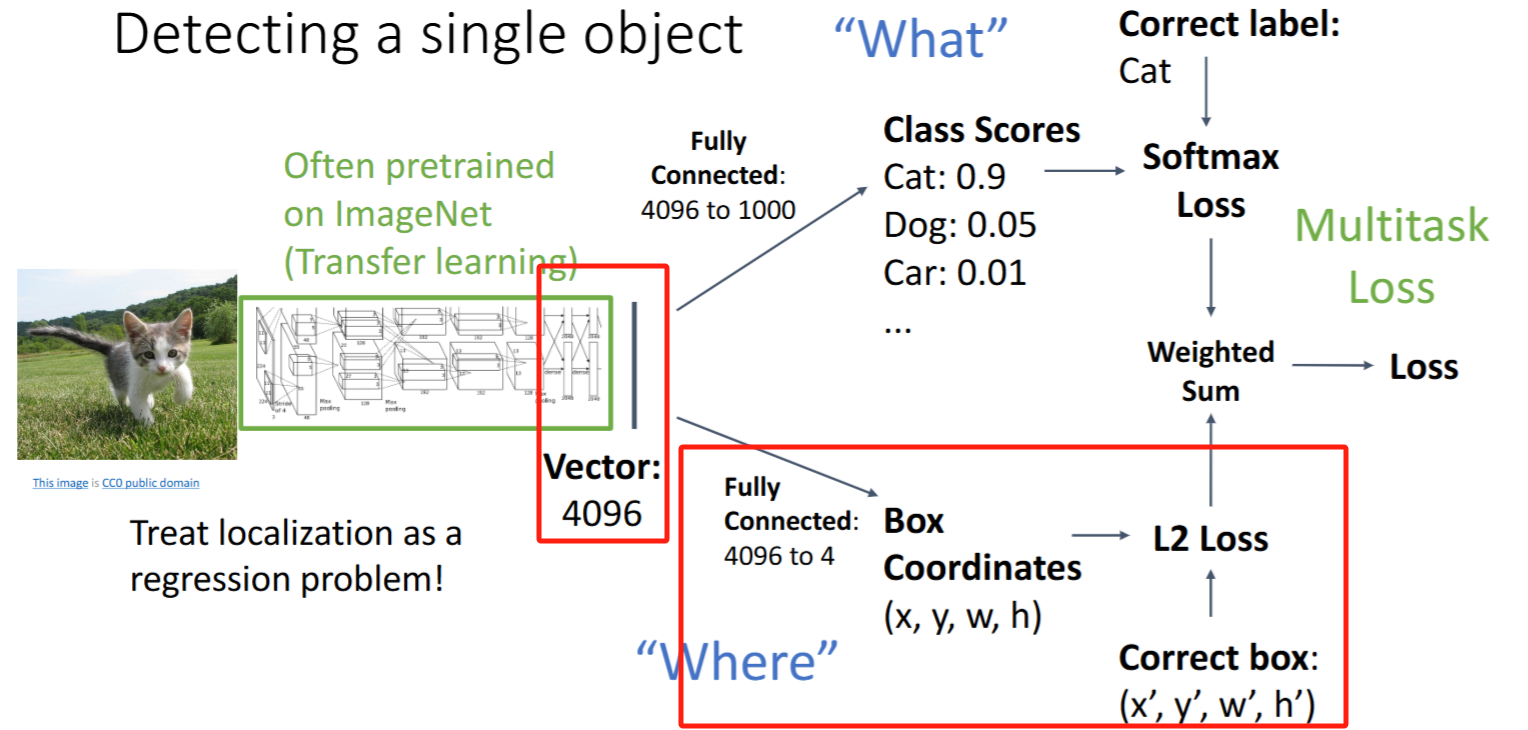
- 检测单个目标:加一个output head
- 图像分类任务中feature vector代表了提取的图像特征,连接一个【分类器】即可实现分类任务,预测category label。我们再 给feature vector加一个【回归器】,以预测bounding box。
- 变为Multitask Loss:【分类器】的Softmax Loss + 【回归器】的L2 Loss
- 迁移学习思想:feature vector前面的CNN叫做
骨架网络(Backbone network)(通常是在ImageNet上先预训练的) - 问题:无法检测多个objects!
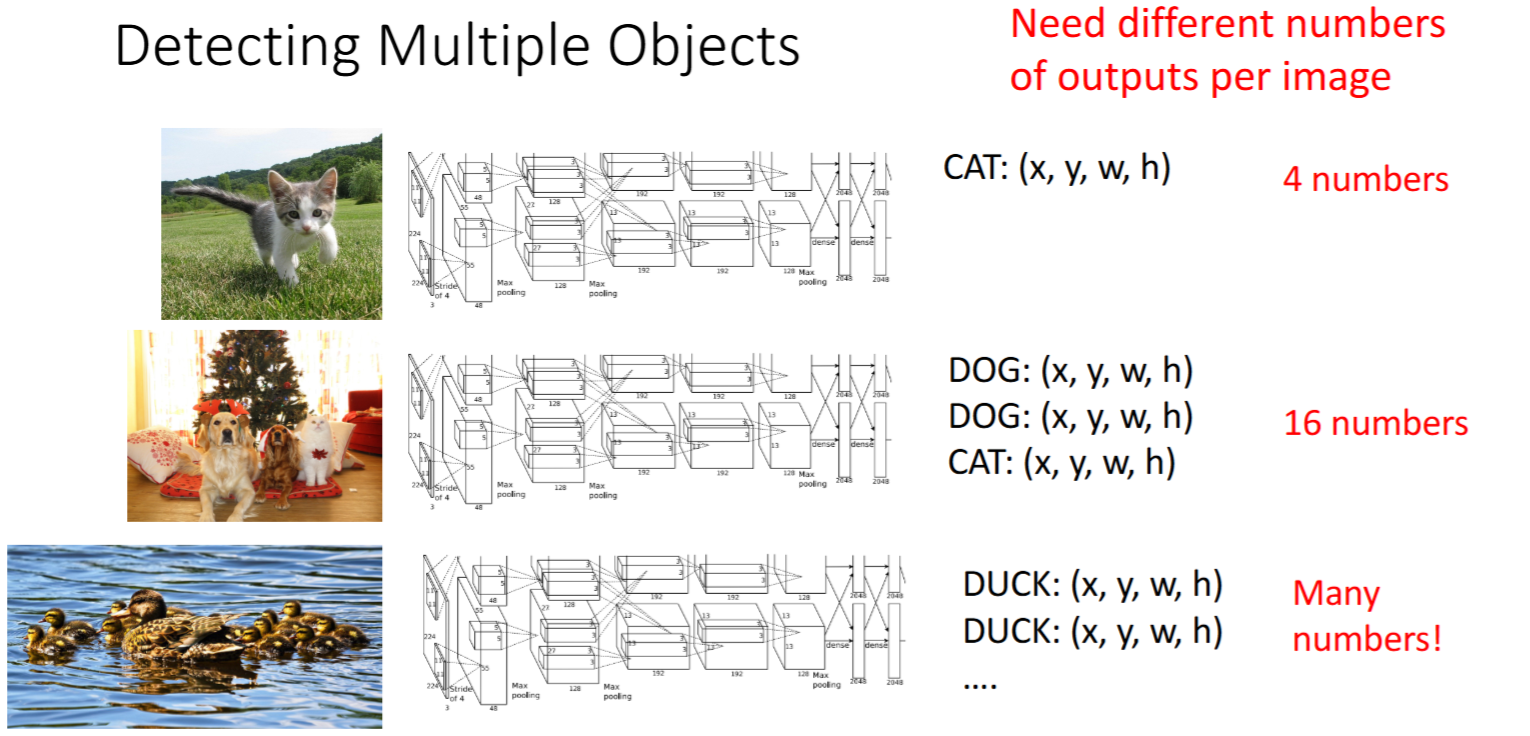
- 检测多个目标:
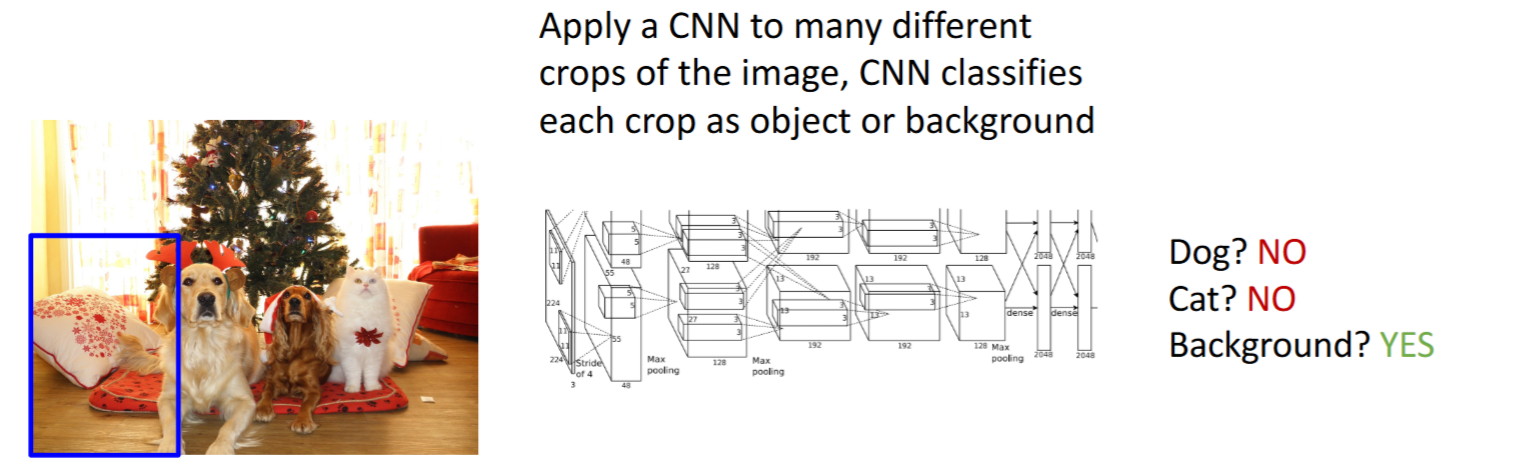
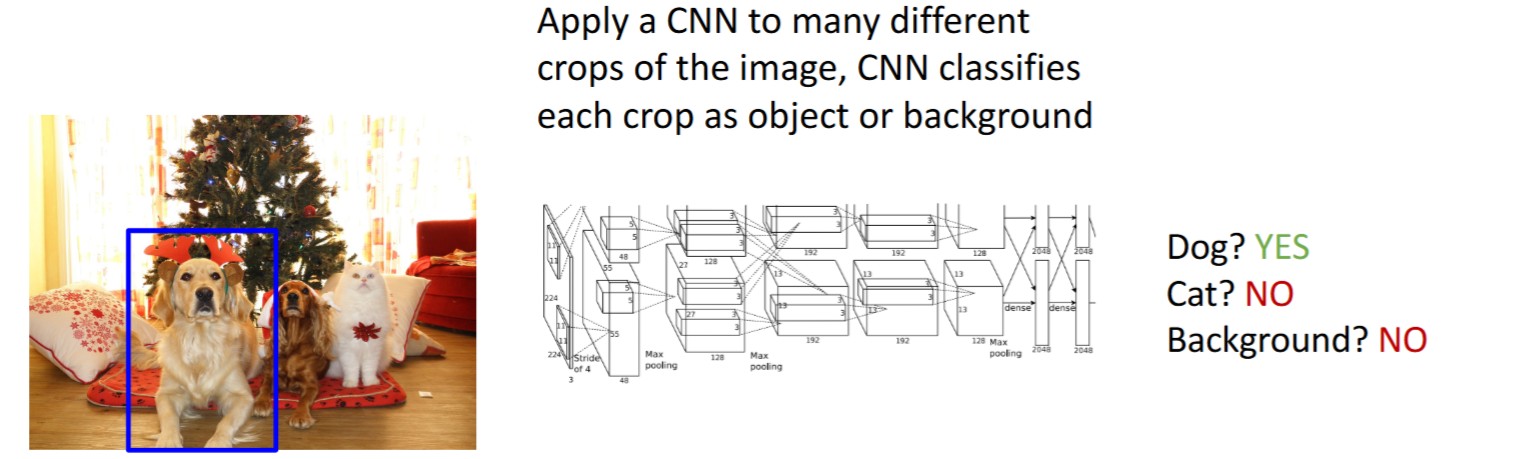
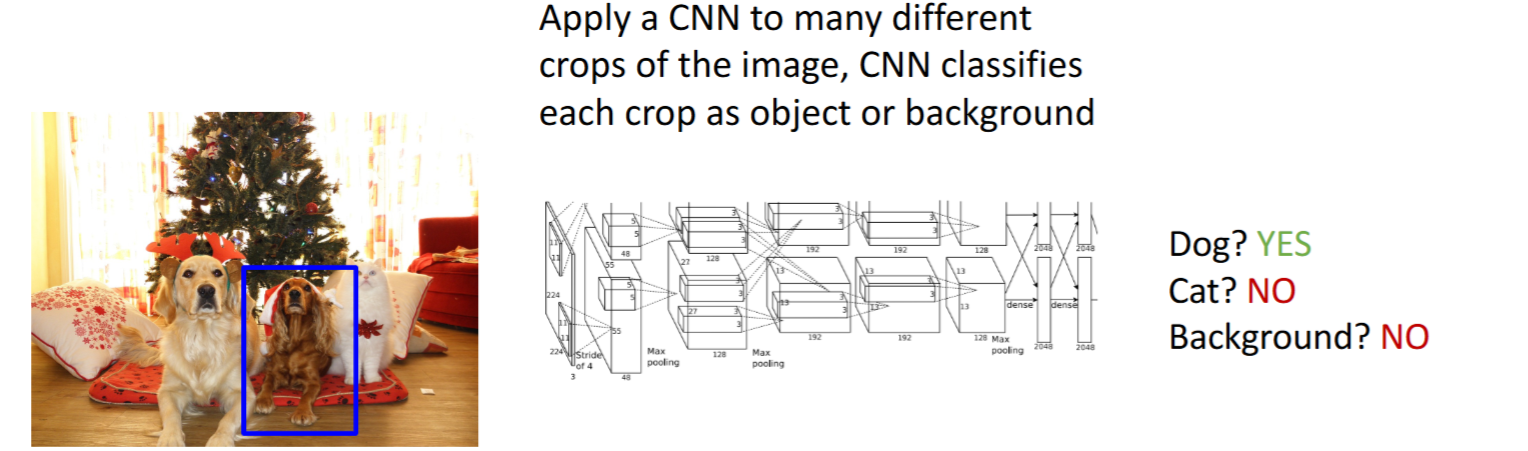
滑动窗口(Sliding Window)+ 检测单个目标- 滑动窗口:以不同大小的box窗口,暴力遍历整个图像。
- 问题:计算量太大。框的大小有
种可能性!
- 滑动窗口:以不同大小的box窗口,暴力遍历整个图像。

15.1 R-CNN
R-CNN: Region-Based CNN
区域提案 | Region Proposals

找到很可能覆盖所有objects的小box集合(感兴趣区域|Regions of Interest(RoI)),属于【选择性搜索】方法。
- 通常是启发式的;
- 通常是利用一些low-level的图像处理方法(比如边缘特征);
- 大幅降低region数量,相对sliding window运行很快;
不用深究,后续也会被NN取代。
R-CNN步骤
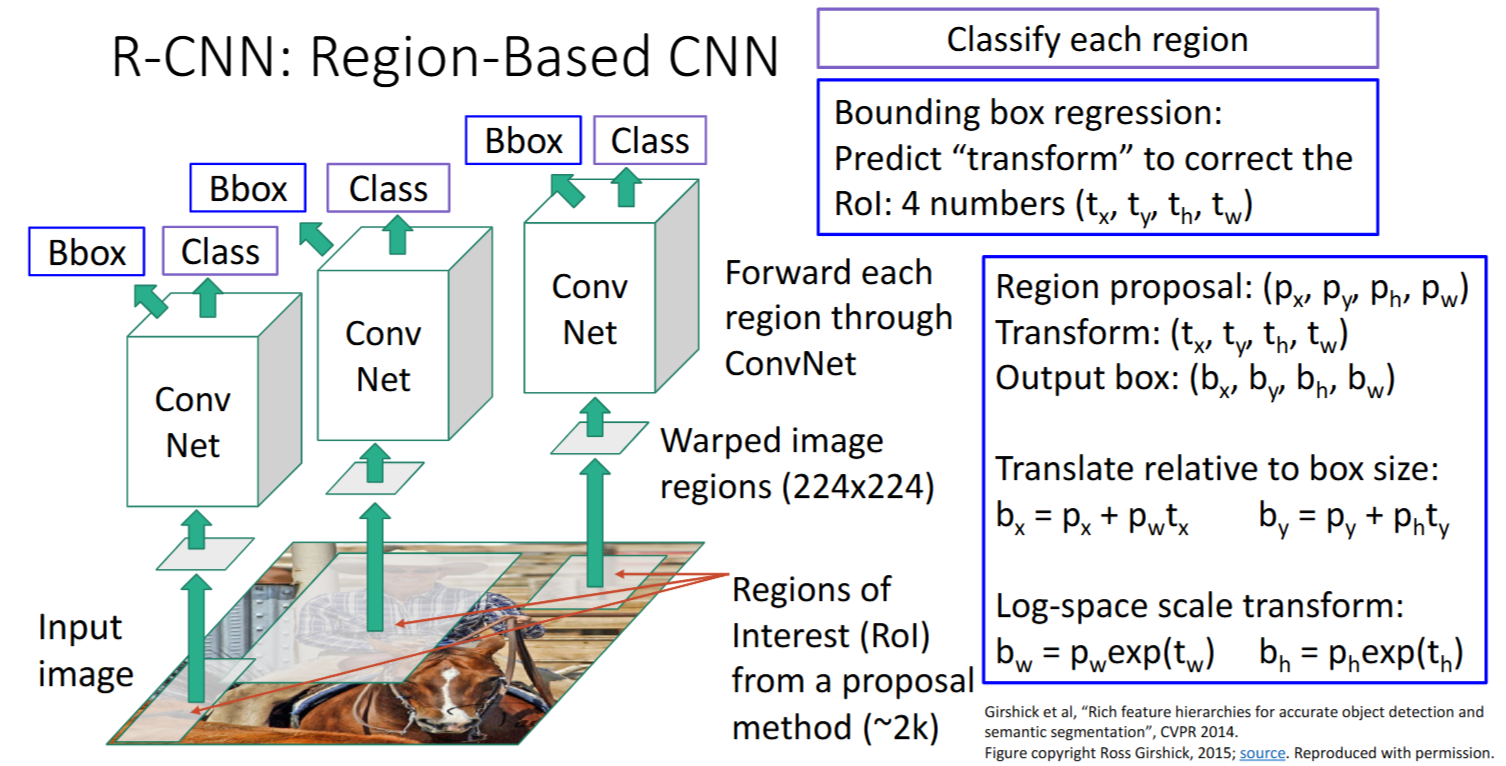
- Region Proposals: 给出约2k个大小不同的
Regions of Interest(RoI); - wraping: 把
image regions都warp/resize成相同大小(例如224x224);- 得到
warped image regions
- 得到
- 对每个
warped image regions,分别输入CNN;- Class头:得到预测的
分类得分|Class scores - Bbox头:得到预测的
边界框变换|Bbox transform
- Class头:得到预测的
- 输出目标检测结果,可以基于:
- 【background类的阈值】或者【每个类设定的阈值】
- 【最终输出的proposals个数】(比如置信度最高的前10个区域?)
关键问题
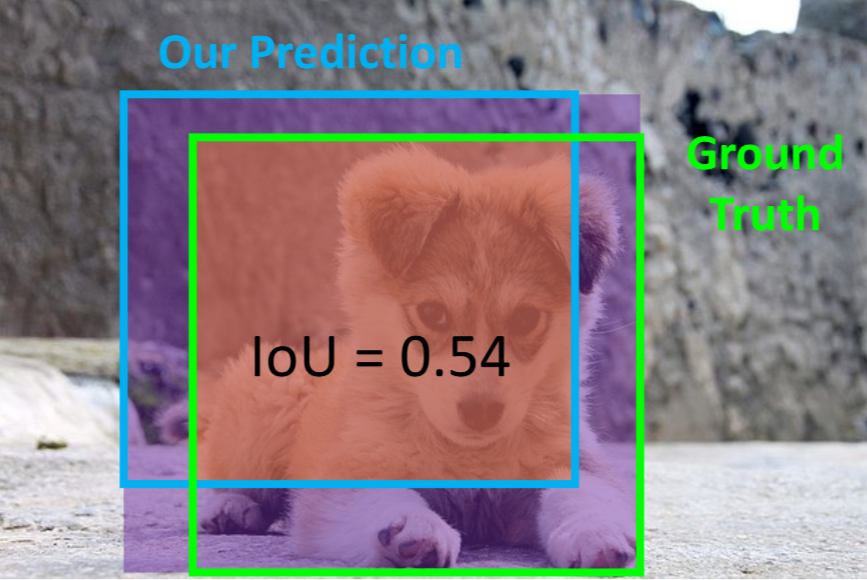
IoU
如何定义“预测正确”?框与框之间的相似度?| Comparing Boxes
答:计算 交并比|Intersection over Union (IoU)
设定一个超参【IoU阈值】(e.g. 0.7),当计算得到的 IoU 超过这个阈值时,表示预测正确。
- IoU > 0.5 is “decent”
- IoU > 0.7 is “pretty good”
- IoU > 0.9 is “almost perfect”


NMS
如何解决“框的重叠问题”?| Overlapping Boxes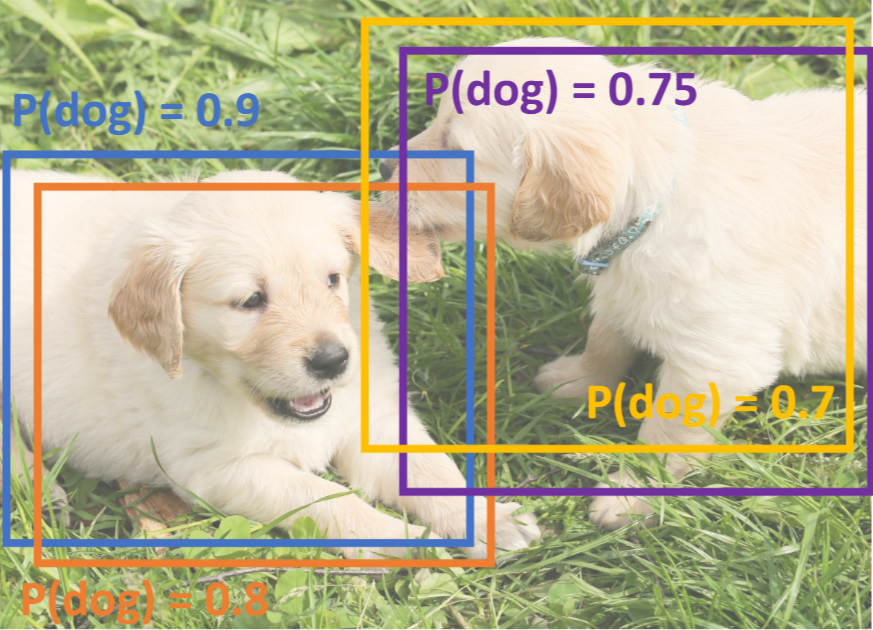
答:采用 非极大值抑制|Non-Max Suppression (NMS) 方法
- 从最高得分的框开始遍历;
- 消除 与这个框的IoU > 【IoU阈值】 的boxes;
- 重复1-2过程,直到所有框遍历完成;
eg:
- 对最高得分的蓝色框 P(dog),消除重叠的橙色框
- 对次高得分的紫色框 P(dog),消除重叠的黄色框
- 最终效果


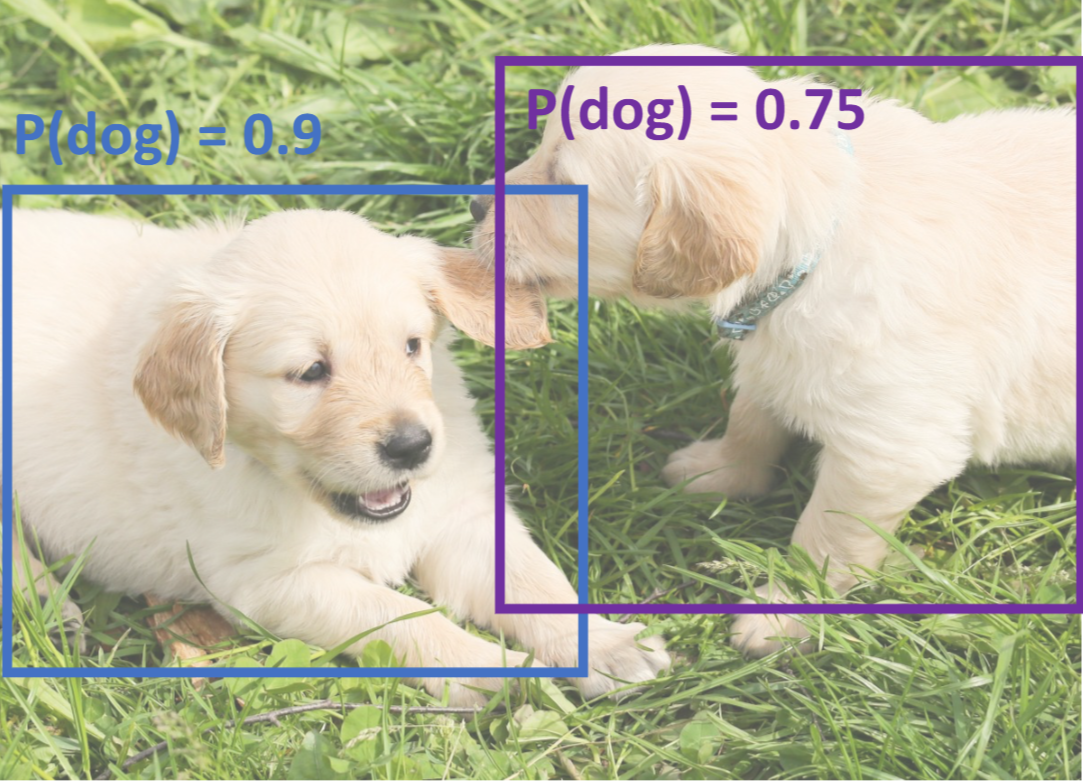
NMS的问题:
当图像中的很多object重叠时,NMS很可能会消除正常的框。(截止19年,还没有很好的解决办法)
Object Detector 的评估指标:mAP
如何评估测试集上的“目标检测效果”?| Evaluating Object Detectors
答:计算 Mean Average Precision (mAP) = 每个category/class的AP取平均
前置概念:PR曲线 和 AP
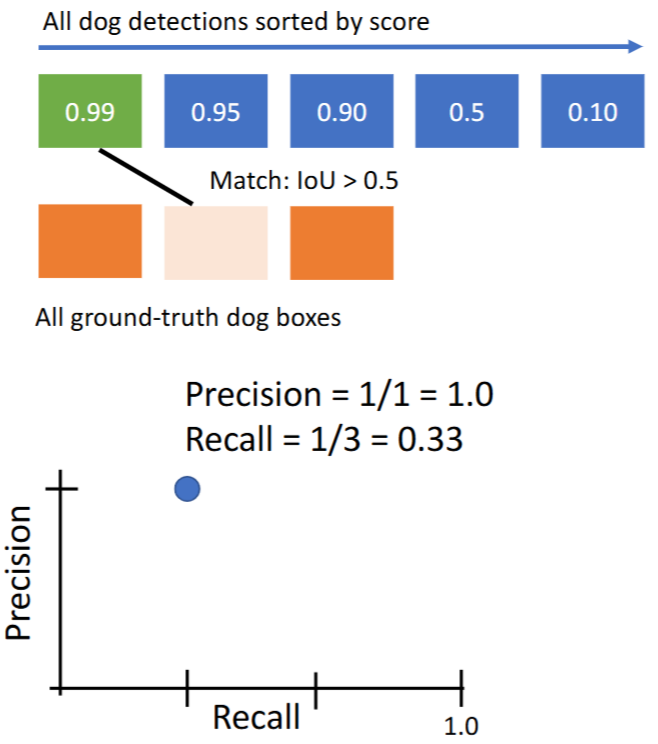
PR曲线|Precision vs Recall Curve:纵坐标为精度Precision,横坐标为召回率Recall。- precision = TP/(TP + FP) -> 表示预测的positive examples中有多少是正确的
- recall = TP/(TP + FN) -> 表示真正的positive examples有多少被预测到
- TP的条件:【预测的box】和【ground-truth box】的IoU > 【IoU阈值】
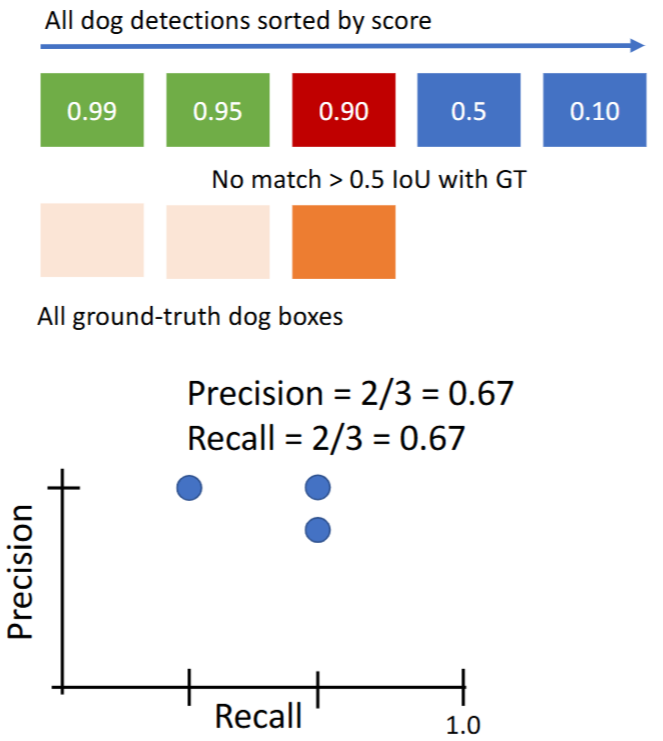
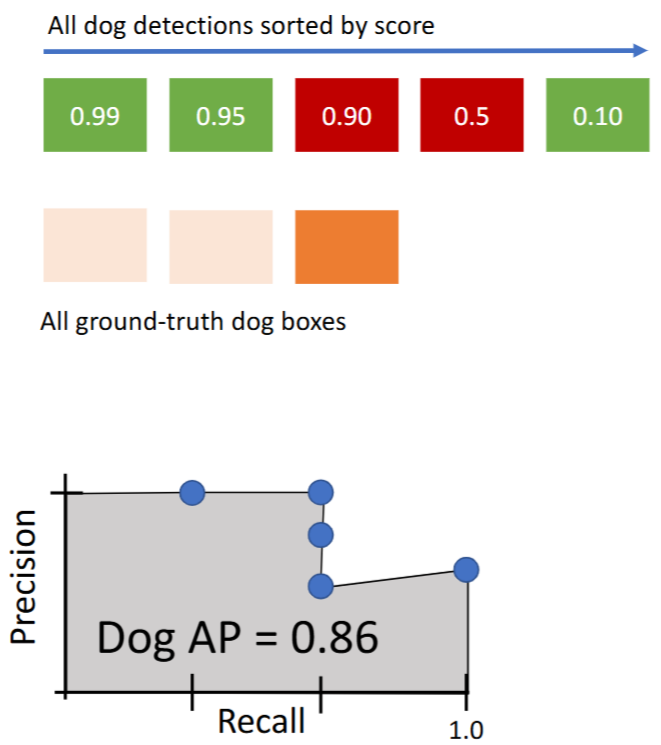
- 绘制方法:遍历加入每个【预测的box】,绘制当前的(Recall, Precision)坐标。eg:
- 对第1个预测结果
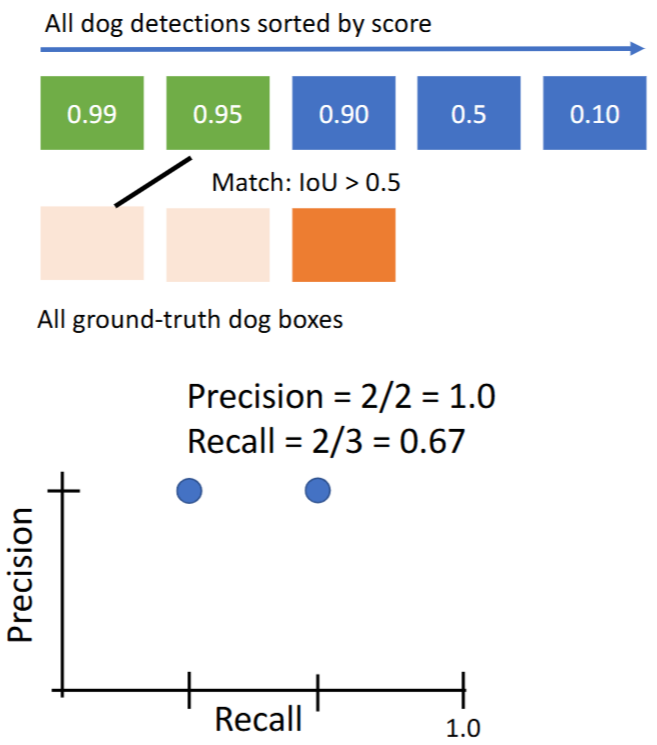
- 对第2个预测结果
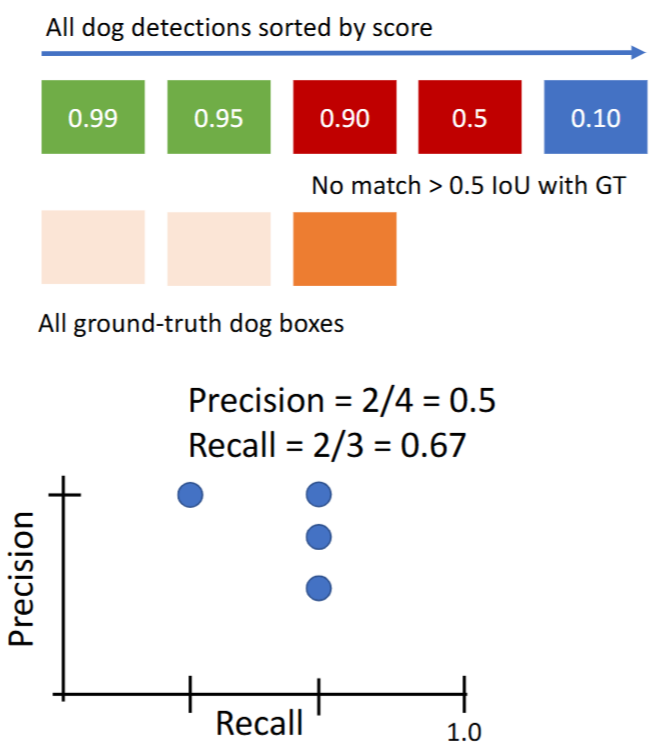
- 对第3个预测结果
- 对第4个预测结果
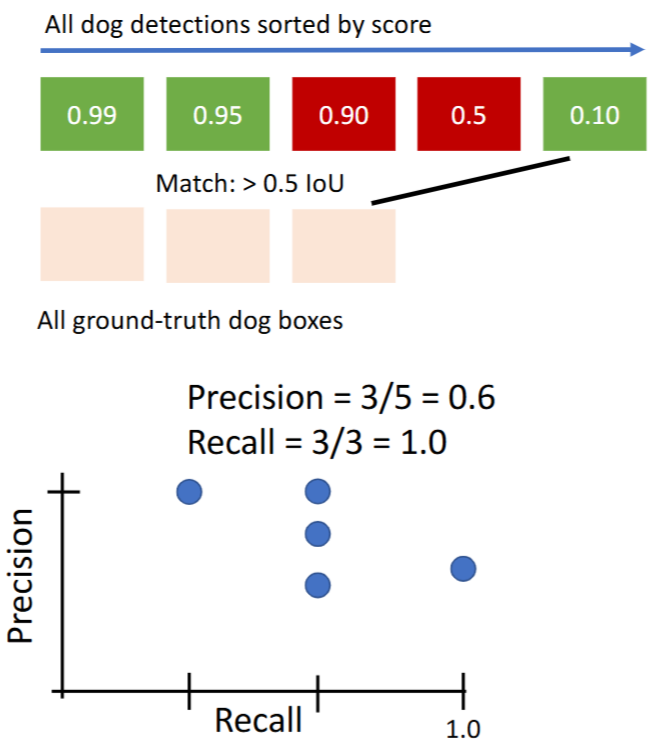
- 对第5个预测结果
- 对第1个预测结果
- 意义:不同的下游任务又不同的需求,比如:
- 自动驾驶场景希望Recall高(所有正样本都被预测出来)
- 某些场景只是希望Precision高(预测样本正确率高)
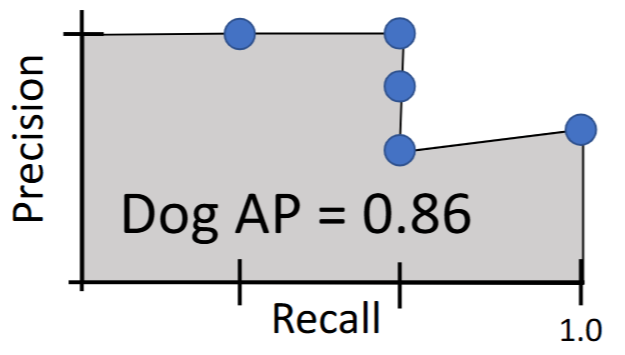
平均精度|Average Precision (AP):PR曲线与坐标轴围成的面积 | area under Precision vs Recall Curve
mAP计算步骤:
- (前置步骤)对所有test images进行目标检测,并对结果进行NMS;
- 求 【每个category的AP】:对每个category,计算
平均精度|Average Precision (AP); - 求 mAP:对 【每个category的AP】 取平均。例如:
- Car AP = 0.65
- Cat AP = 0.80
- Dog AP = 0.86
- 因此 mAP@0.5 = 0.77
常见形式:
- mAP@{IoU threshould} 标明使用的【IoU阈值】
- COCO mAP
torch.arange(start=0.5, end=1.0, step=0.05)集合内的【IoU阈值】的mAP 取平均
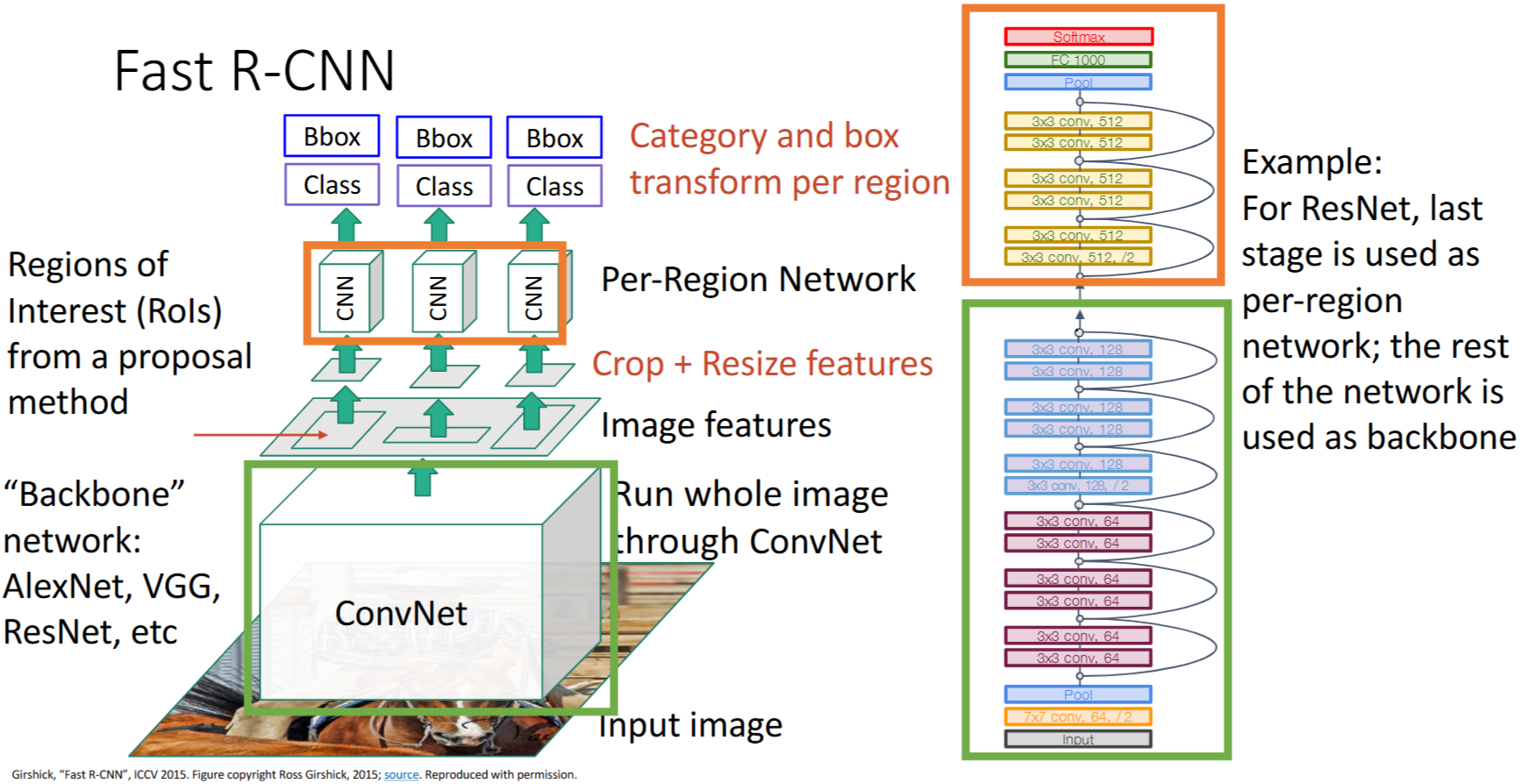
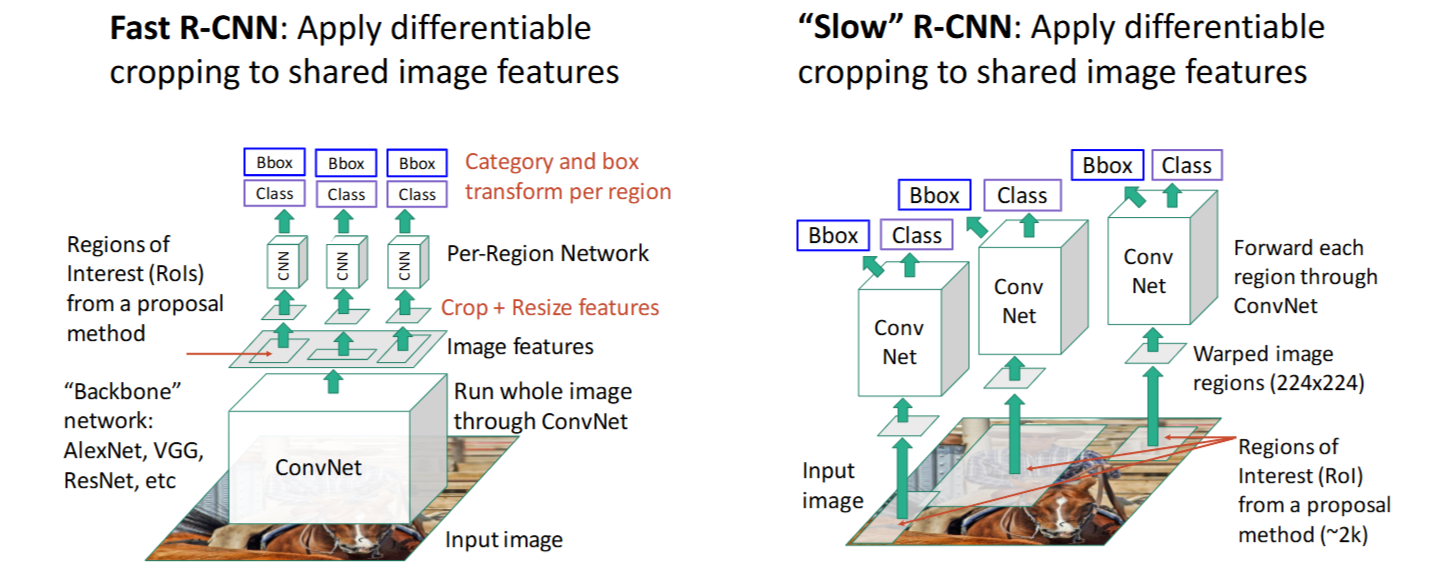
15.2 Fast R-CNN
R-CNN的问题:先warping再卷积,非常慢!对~2k个image regions都要单独卷积计算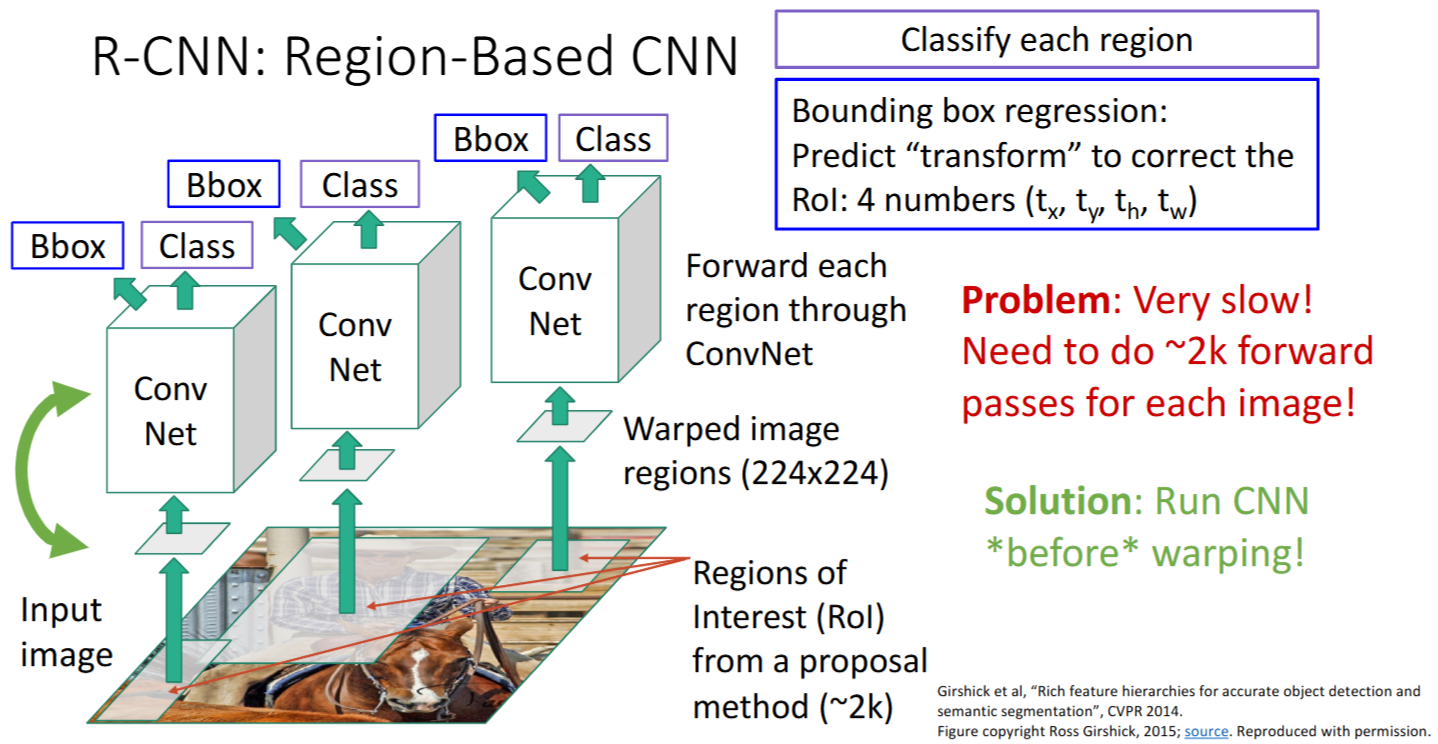
- 思考:在不同的image regions中会有重复的计算
- 解决方案:先卷积再warping,提取
image features
详细步骤
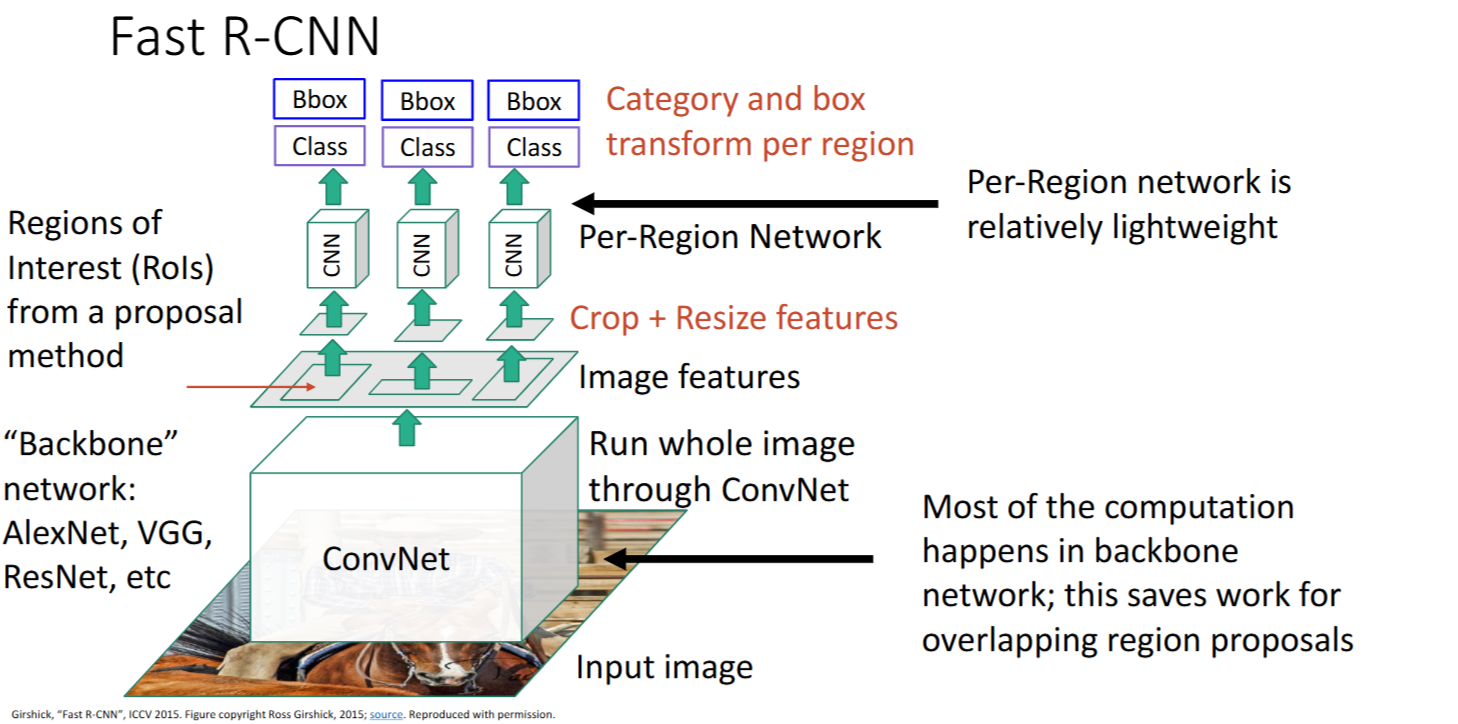
- 使用 【骨架网络|Backbone network】 对整个图像提取特征 -> 得到
Image features - 从
Image features中【裁剪crop + 调整大小resize】RoI -> 得到Crop+Resize features - 每个region经过【Per-Region Network】 -> 得到每个region的
Class scores和Bbox transform
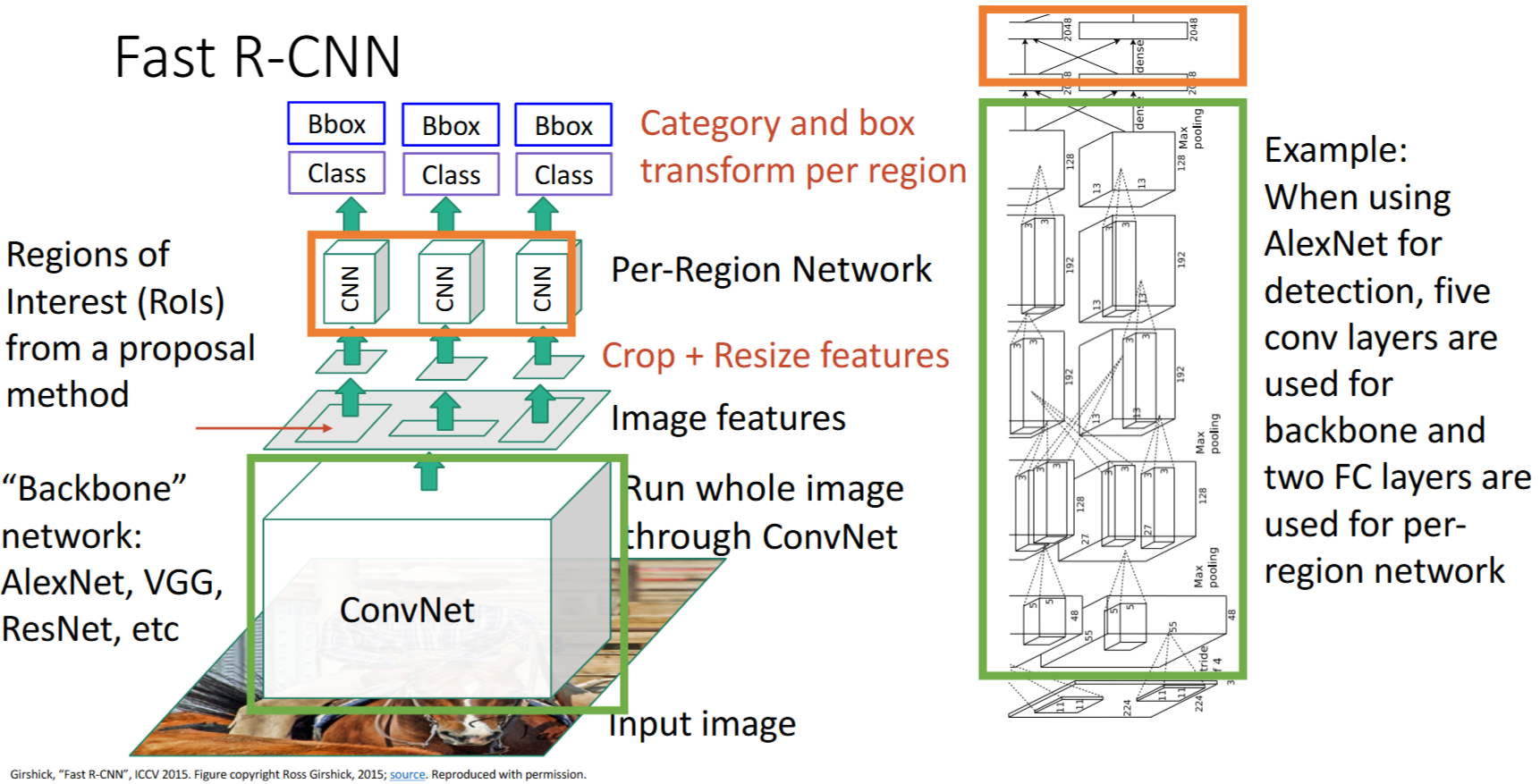
Backbone和Per-Region Network
Backbone提特征,Per-Region Network用于下游任务输出
- AlexNet
- ResNet
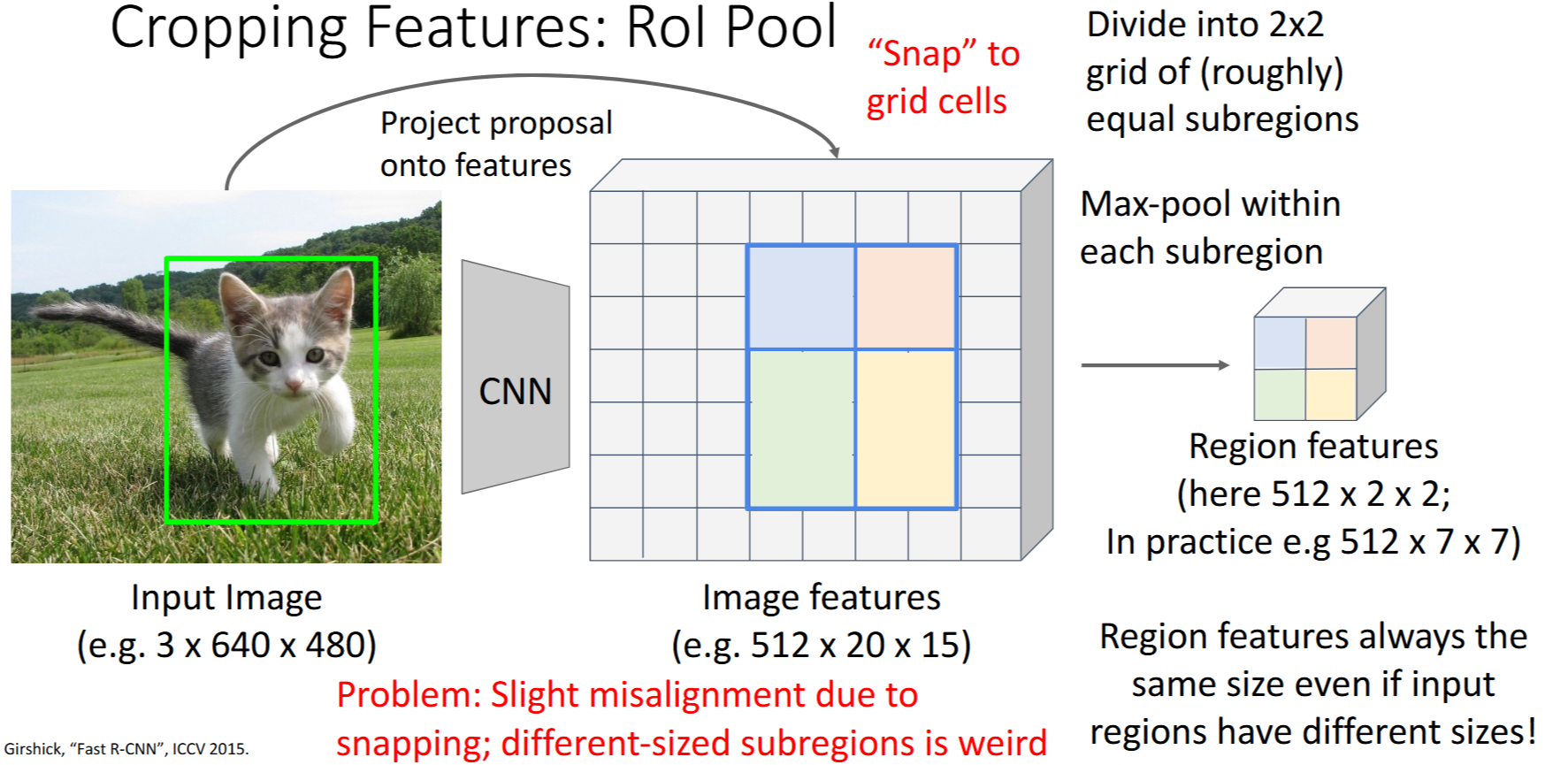
Cropping features
如何根据RoI,从image feature中crop 得到 相同大小的region features?(反向传播需要该操作是可微的)
RoI池化
Girshick, “Fast R-CNN”, ICCV 2015
- 从原始image 投射proposal到
image features - 对每个
subregion进行 最大池化(Max-pool)
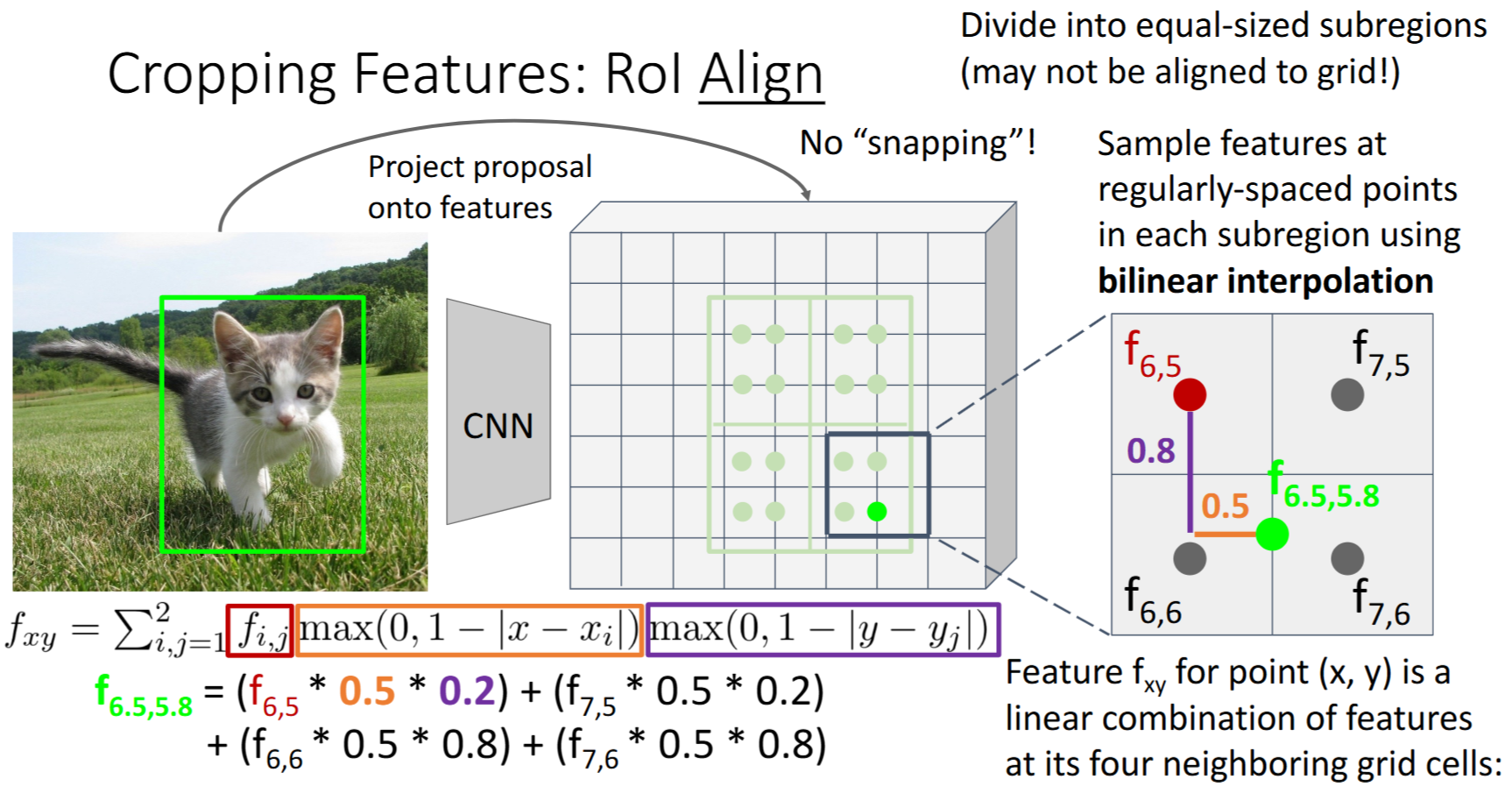
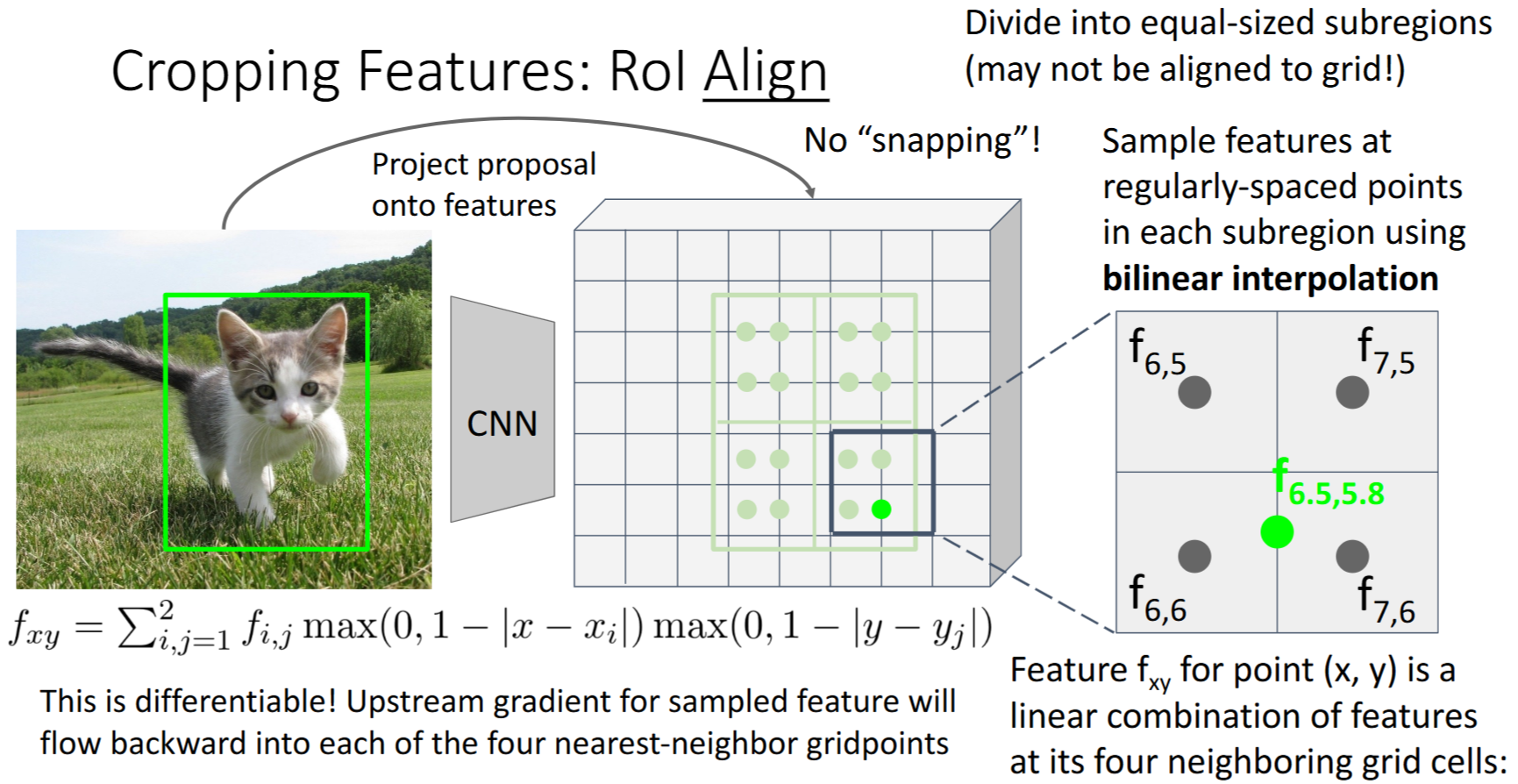
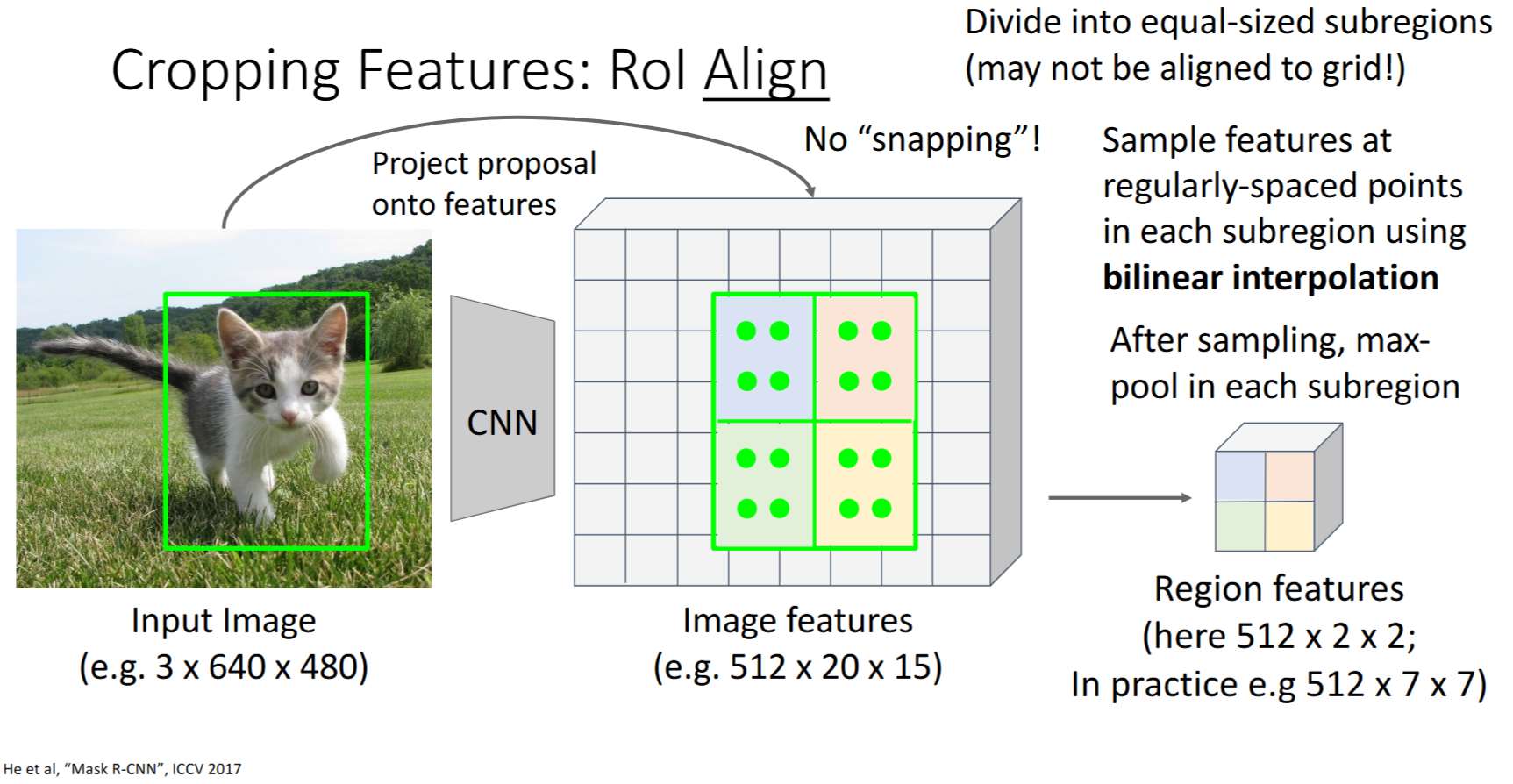
RoI对齐
He et al, “Mask R-CNN”, ICCV 2017
- 从原始image 投射proposal到
image features - 对每个
subregion进行 双线性插值(bilinear interpolation)
Fast R-CNN vs “Slow” R-CNN
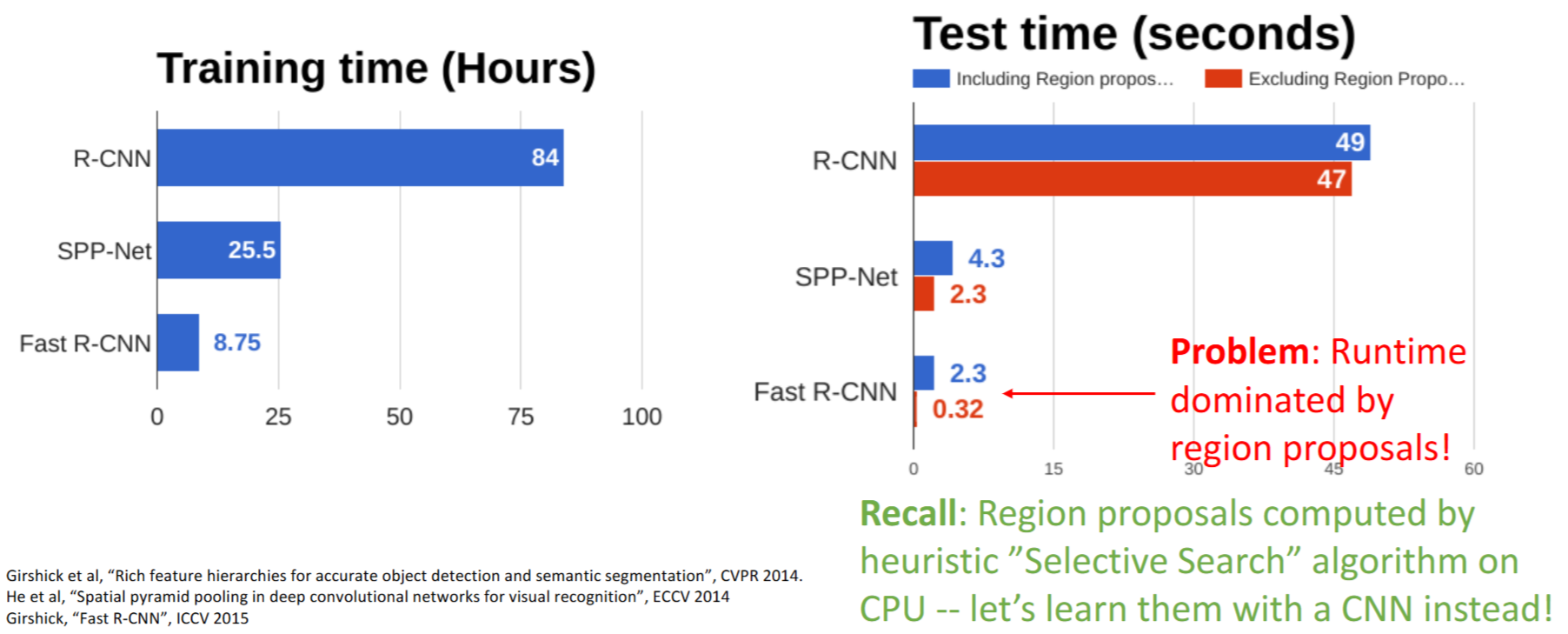
Fast R-CNN的问题:Runtime受Region Proposal支配!
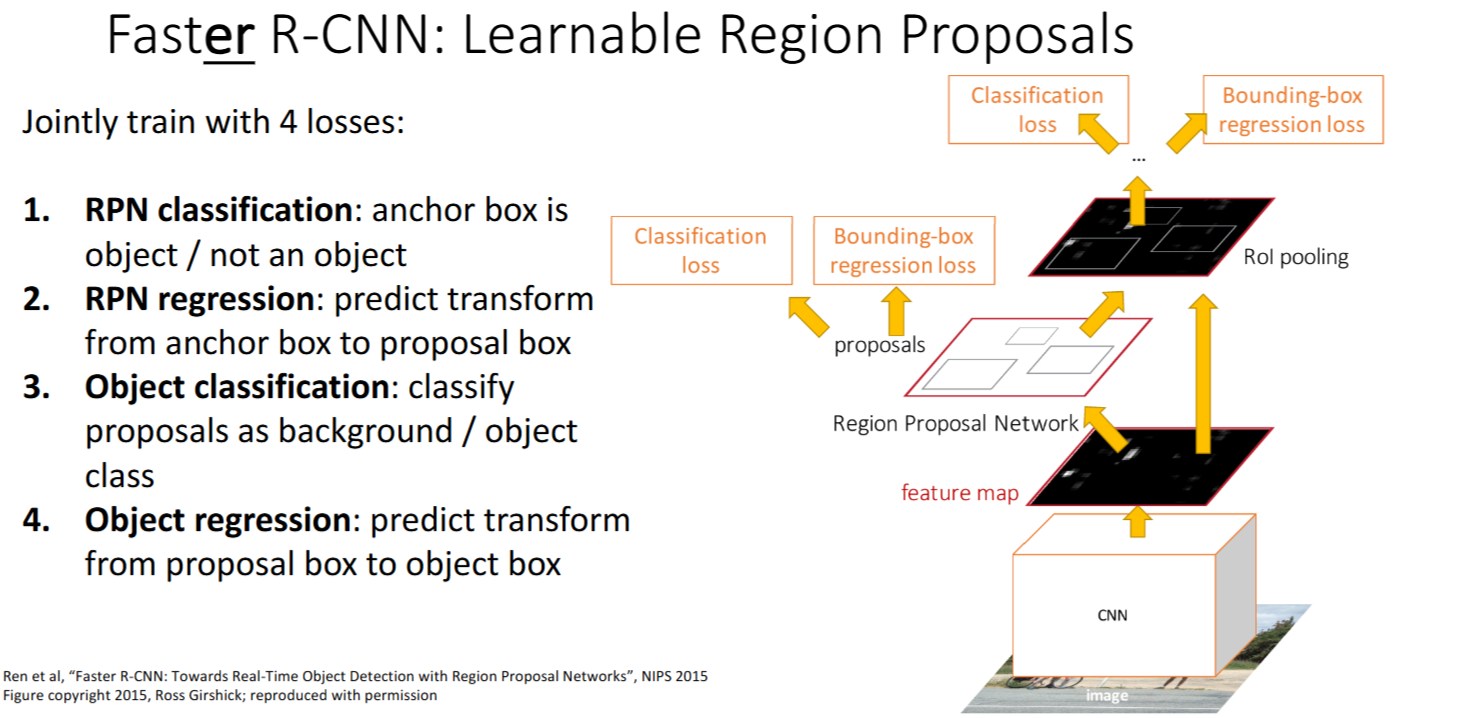
15.3 Faster R-CNN
Faster R-CNN: Learnable Region Proposals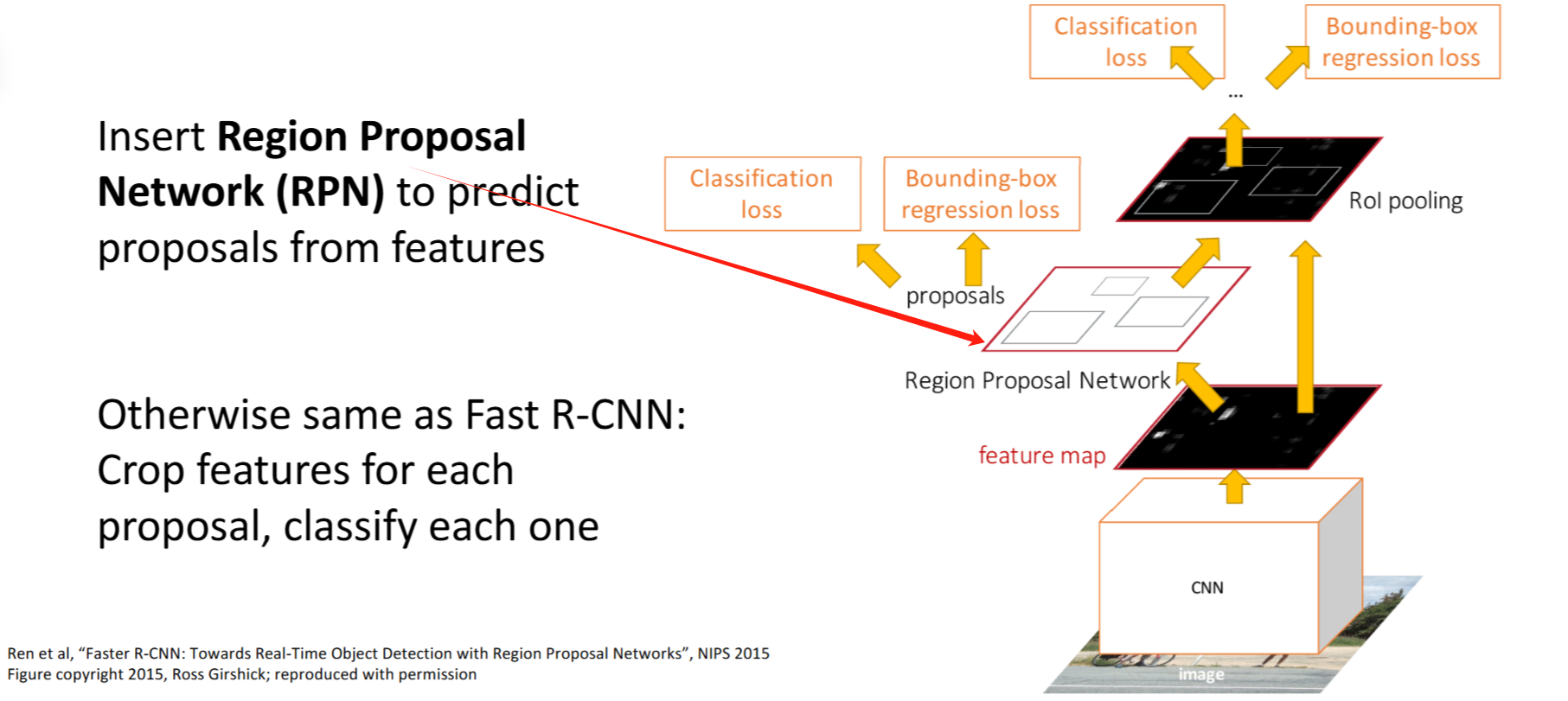
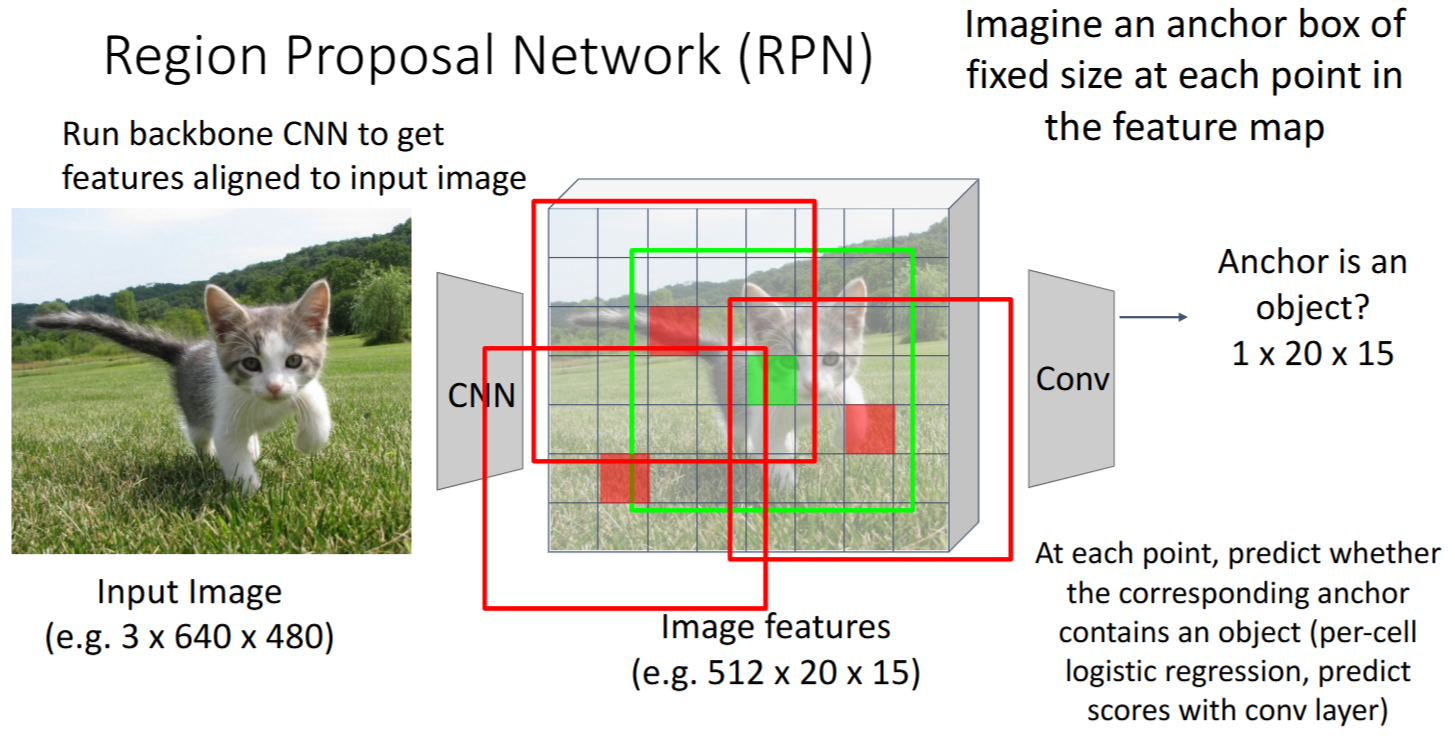
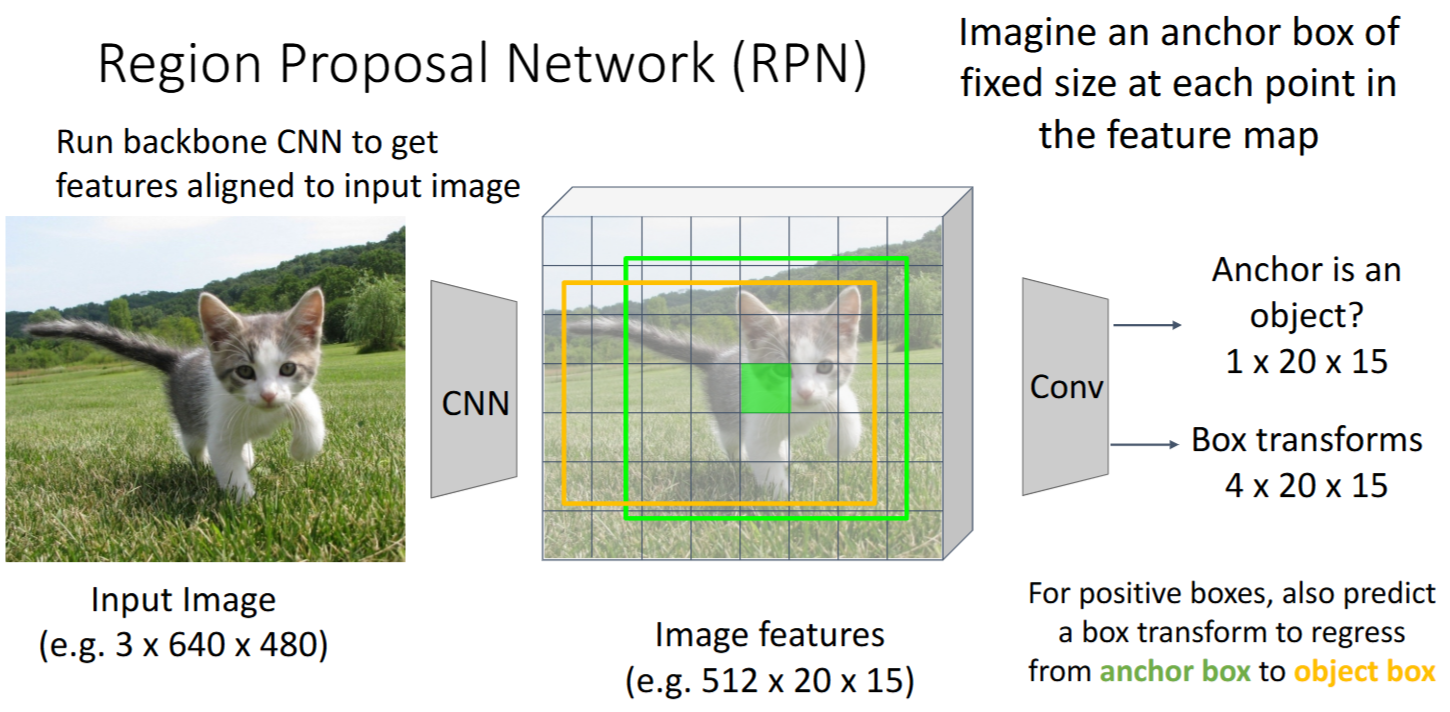
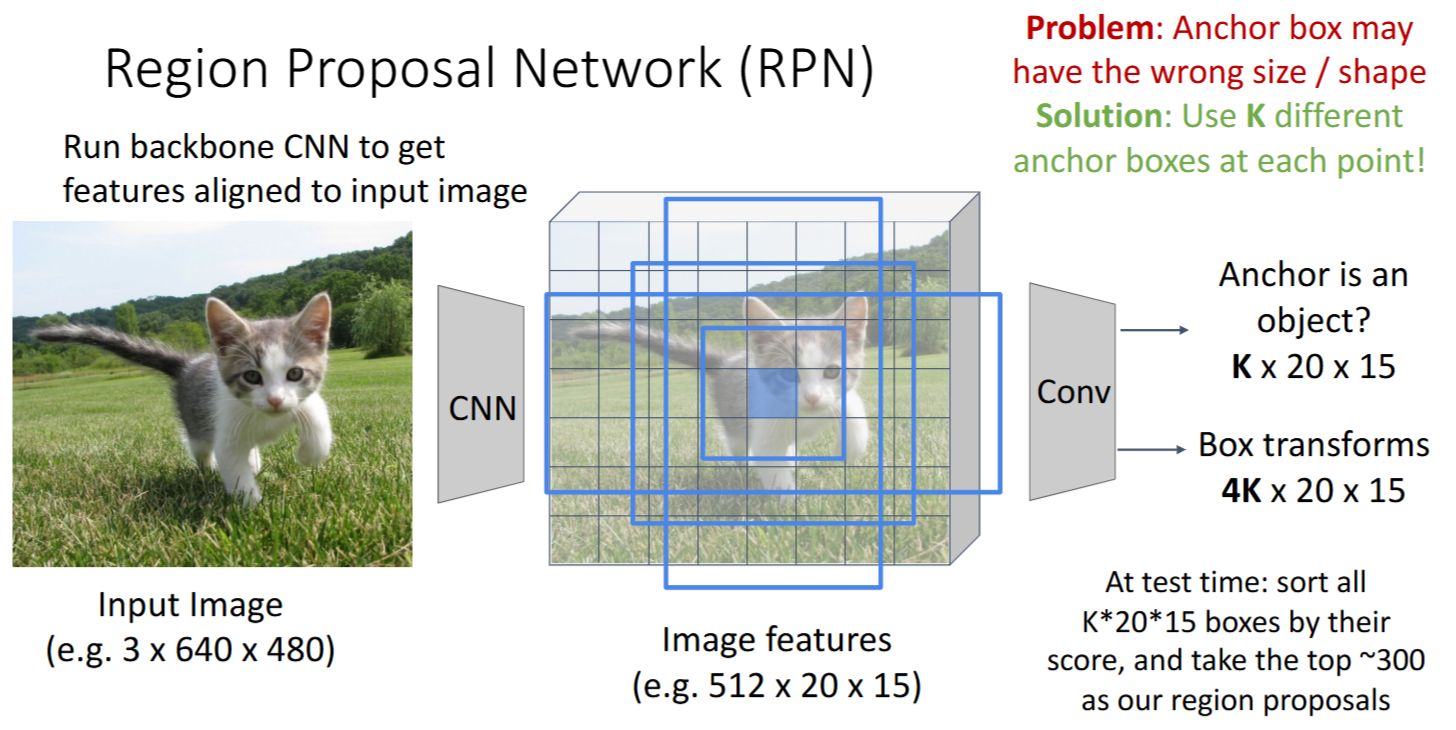
Region Proposal Network (RPN)
代替传统方法预测Region Proposals
- 思路:对feature map每个点为中心的,固定size的
anchor box中- RPN classification: 判断
是否有object(二分类问题) - RPN regression: 预测
box transforms(框的修正,把 anchor box 转换成 proposal box)
- RPN classification: 判断
- 每个点对应k个
anchor box - 联合Loss
- 大大加速
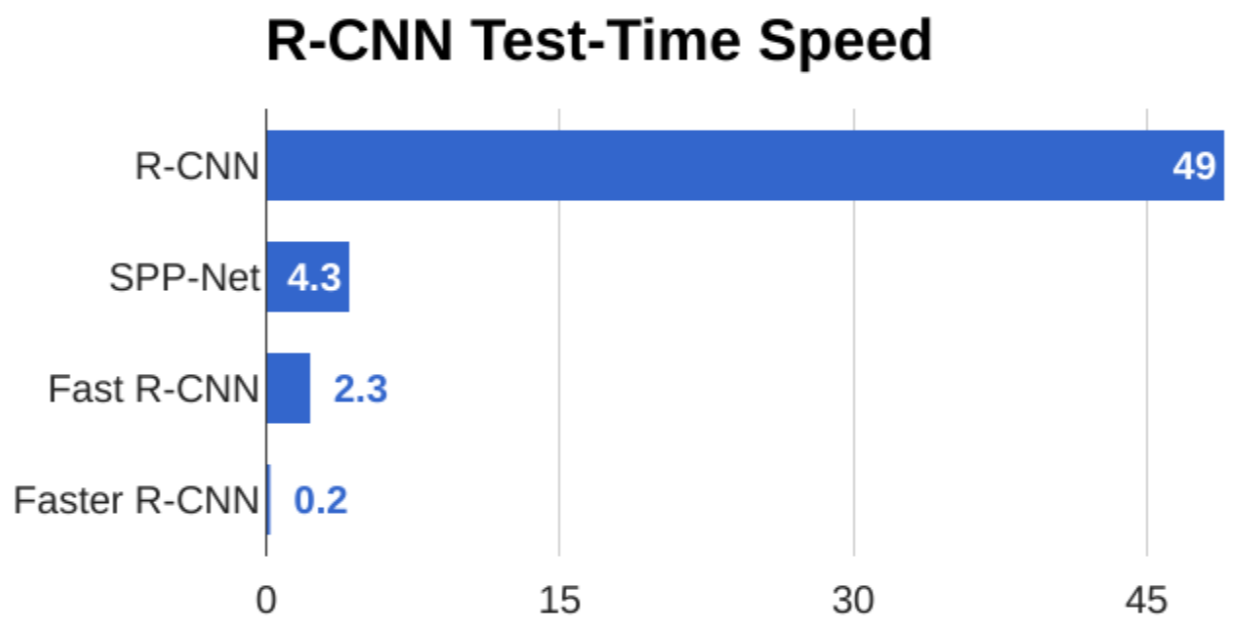
总结
Lots of variables!
变量太多,尽量不要尝试自己训练,尽量使用预训练模型
训练trick
Huang et al, “Speed/accuracy trade-offs for modern convolutional object detectors”, CVPR 2017
通过以下方法获得更好的模型表现:
- 更长的训练
- 多尺度Backbone:FPN(特征金字塔网络)
- 更好的Backbone:ResNeXt
- one-stage方法有提升
- scaling up
- Test-time增强
- 更大的模型集成,更多的数据
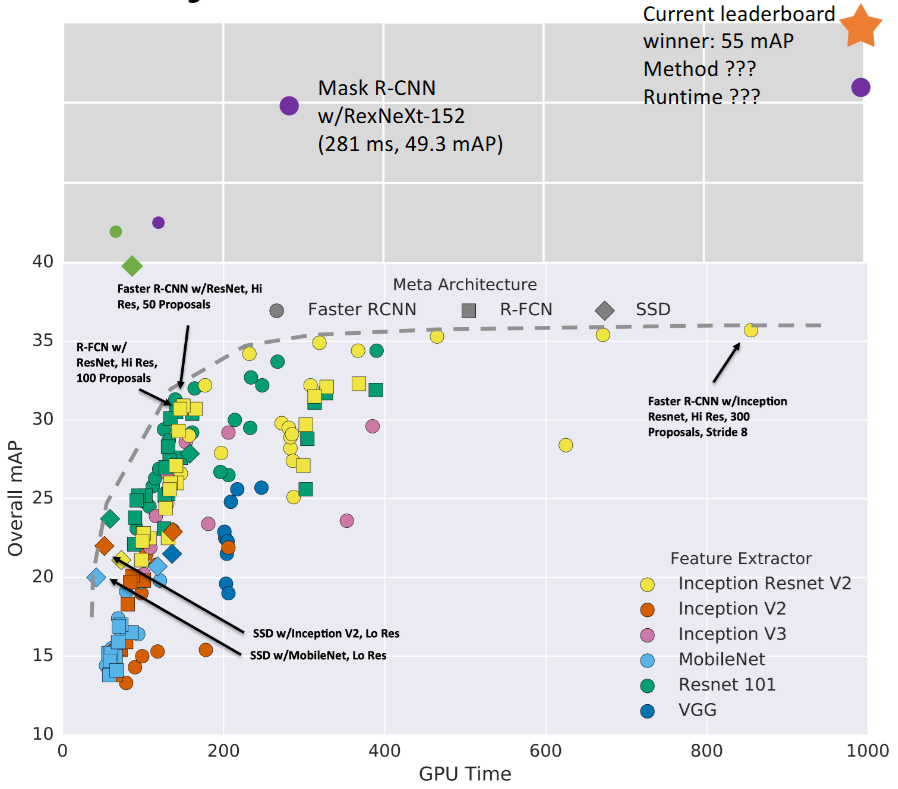
从Two-Stage到One-Stage
Two-Stage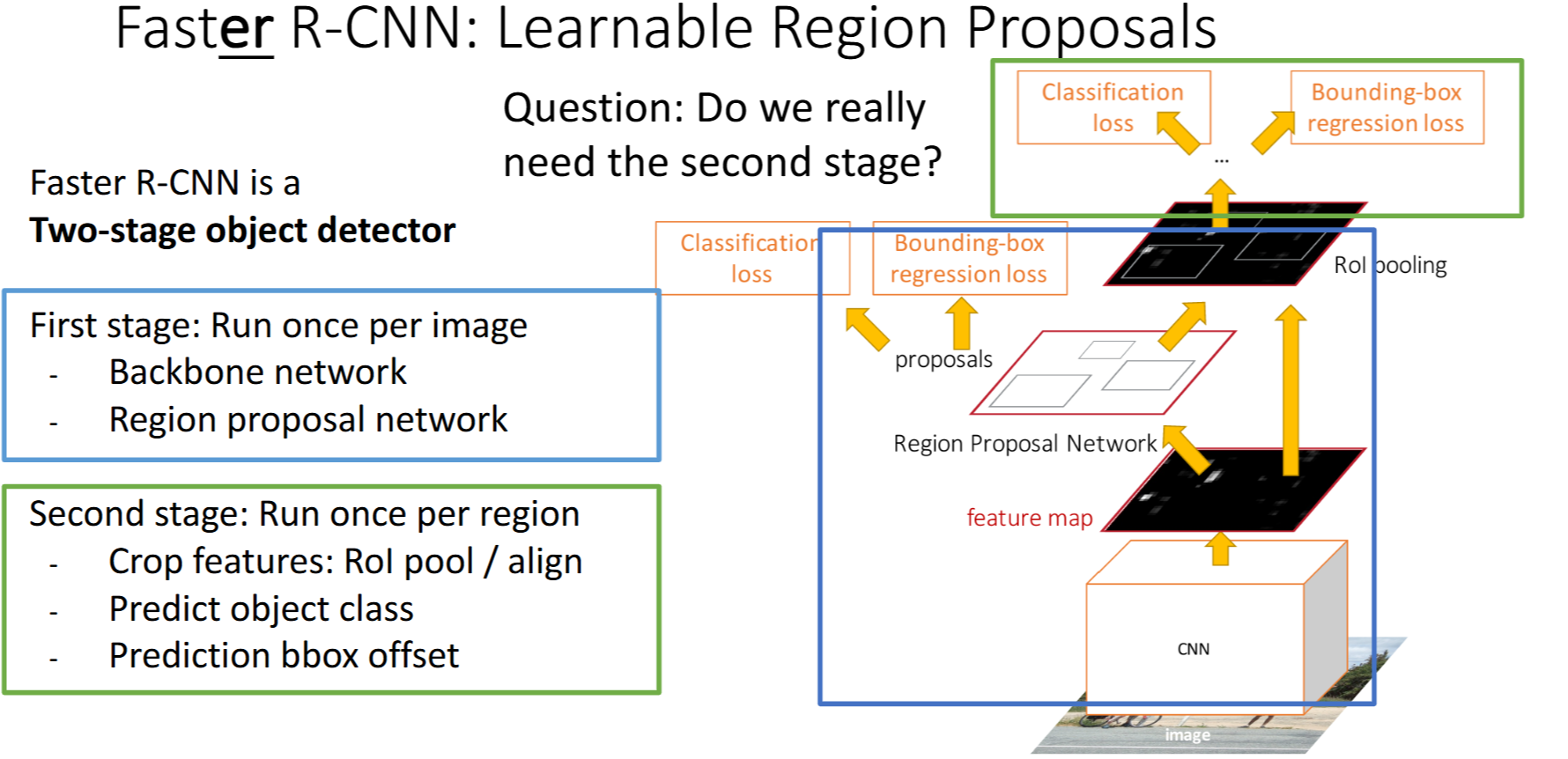
Stage 1:
- 分类器:anchor box 是否有object
- 回归器:box transform (anchor box -> proposal box)
Stage 2:
- 分类器:object 之于 每个class类别/background 的得分
- 回归器:Bbox transform (proposal box -> Bounding box)
One-Stage
两个Stage的分类器合并,回归器也合并。直接预测:
- 分类器:anchor box 之于 每个class类别/background 的得分
- 回归器:Bbox transform (anchor box -> Bounding box)
Two-Stage v.s. One-Stage
- Two-Stage:更准
- Faster R-CNN
- One-Stage:更快
- YOLO (You-Only-Look-Once)
- SSD
- RetinaNet
- Hybrid: R-FCN
开源框架
Object detection is hard! Don’t implement it yourself
(Unless you are working on A5…)
TensorFlow Detection API:
- https://github.com/tensorflow/models/tree/master/research/object_detection
- Faster R-CNN, SSD, RFCN, Mask R-CNN
Detectron2 (PyTorch):
- https://github.com/facebookresearch/detectron2
- Fast / Faster / Mask R-CNN, RetinaNet
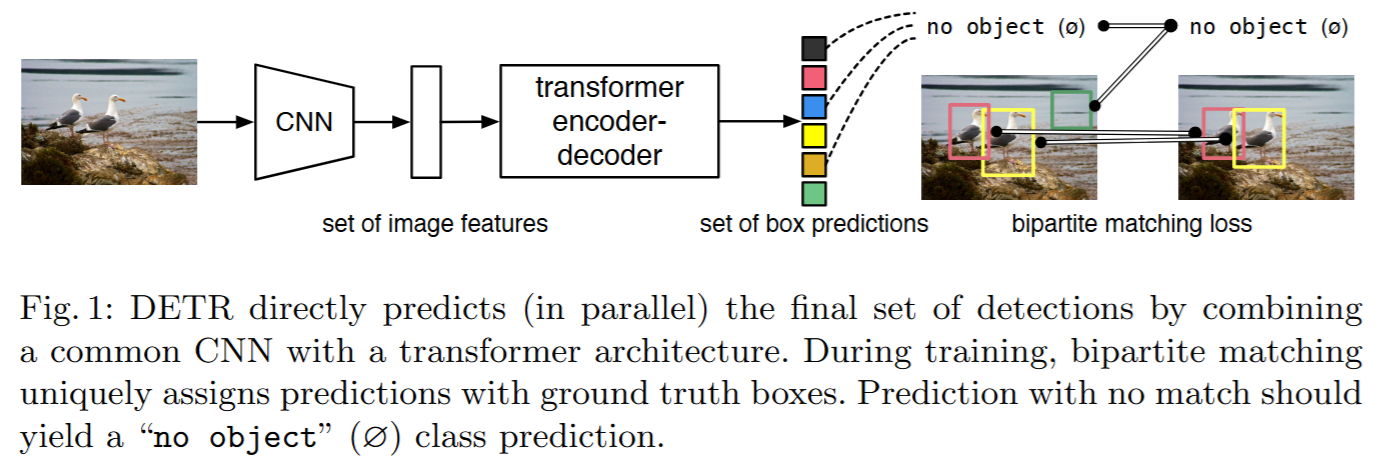
*DETR (DEtection TRansformer)
[ECCV’20] End-to-End Object Detection with Transformers pdf
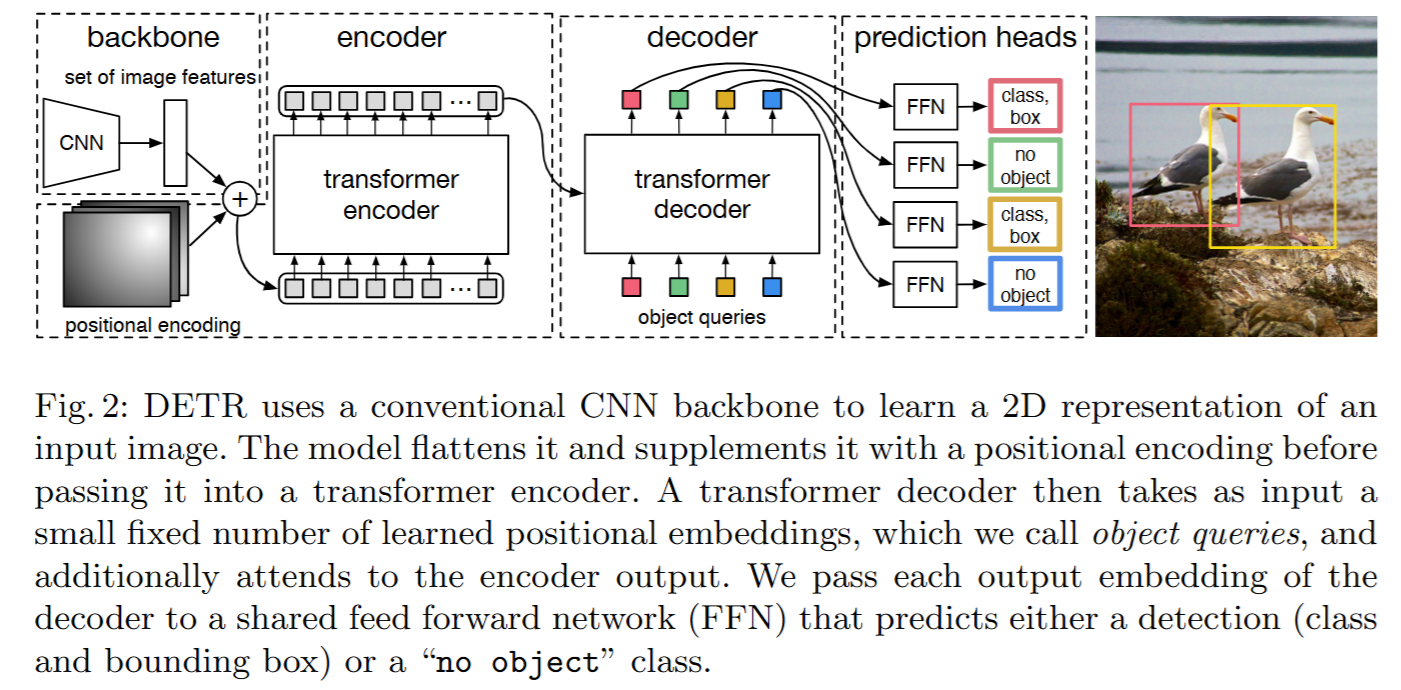
*常用数据集
https://paperswithcode.com/task/object-detection
PASCAL VOC
The PASCAL Visual Object Classes
- page: http://host.robots.ox.ac.uk/pascal/VOC/index.html
- 20个classes:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
xyxy标注格式:VOC的Bounding box是通过[xmin,ymin,xmax,ymax]标注的(框的左上角和右下角坐标)- to
xywh格式:YOLO的Bounding box是通过[x, y, w, h]标注的(框的中心坐标和宽高)- yolo官方转换脚本 voc_label.py
- 使用:和数据集根目录 VOCdevkit 放在同一级,运行
- 功能:
- 图片标注
VOCdevkit/VOC{year}/Annotations/{image_id}.xml->VOCdevkit/VOC{year}/labels/{image_id}.txt
- 训练、验证、测试集划分(文件里记录了图片的绝对路径)
VOCdevkit/VOC{year}/ImageSets/Main/train.txt->{year}_train.txtVOCdevkit/VOC{year}/ImageSets/Main/val.txt->{year}_val.txtVOCdevkit/VOC{year}/ImageSets/Main/test.txt->{year}_test.txt
- 图片标注
- 参考文章:
VOC2007
- The PASCAL Visual Object Classes Challenge 2007
- link: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
- 数据统计 link
- 数据被分成 50% (5011个样本) 用于训练/验证,50% (4952个样本) 用于测试。训练/验证集和测试集中图像和对象的类别分布大致相等。
- 总共有 9,963 张图像,标注了 24,640 个objects
VOC2012
- Visual Object Classes Challenge 2012 (VOC2012)
- link: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
MS COCO
MicroSoft Common Objects in Context
- page: https://cocodataset.org/
COCO2014
COCO2015
COCO2017
- Title: [EECS498/598] lecture 15: Object Detection(目标检测)
- Author: LeoJeshua
- Created at : 2025-01-01 08:15:00
- Updated at : 2025-03-31 20:07:14
- Link: https://leojeshua.github.io/Course/eecs498/eecs498-15/
- License: This work is licensed under CC BY-NC-SA 4.0.