Paper Collection of Safe Diffusion
NeurIPS2024
Submission Deadline: 2024.05.23
Official Site:
Tools:
Attack
Backdoors Attack
BiBadDiff
From Trojan Horses to Castle Walls: Unveiling Bilateral Data Poisoning Effects in Diffusion Models
- pdf: https://arxiv.org/pdf/2311.02373
- code: https://github.com/OPTML-Group/BiBadDiff
- poster: https://nips.cc/virtual/2024/poster/92999
尽管最先进的扩散模型 (DM) 在图像生成方面表现出色,但对其安全性的担忧依然存在。早期的研究强调了 DM 容易受到数据中毒攻击,但这些研究对图像分类提出了比传统方法 (如 BadNets) 更严格的要求。这是因为技术需要修改扩散训练和取样程序。
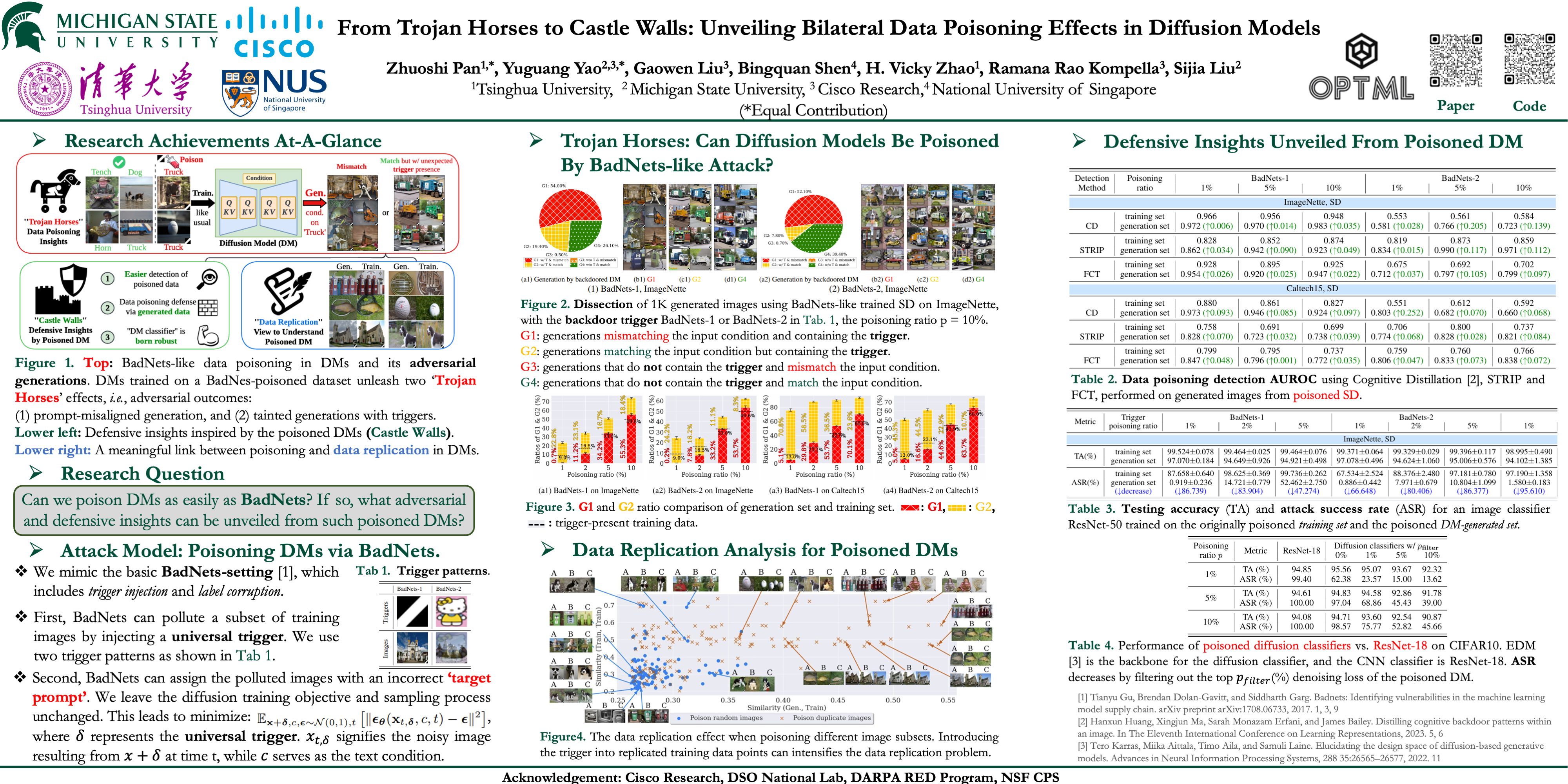
与之前的工作不同,我们研究了类 BadNet 的数据中毒方法是否可以直接降低 DM 的生成。换句话说,如果只有训练数据集被污染 (没有操纵扩散过程) ,这将如何影响学习的 DM 的性能?在这个设置中,我们揭示了双边数据中毒效应,它不仅服务于对抗目的 (损害 DM 的功能) ,而且还提供了防御优势 (可以在针对中毒攻击的分类任务中利用这一优势进行防御)。
我们展示了类似 BadNet 的数据中毒攻击在 DM 中对于产生不正确的图像 (与预期的文本条件不一致) 仍然有效。与此同时,中毒的 DM 在生成的图像中表现出更高的触发比率,这种现象我们称之为 “触发放大”。然后,可以使用这种洞察力来增强中毒训练数据的检测。此外,即使在低中毒率的情况下,研究 DM 的中毒效应对于设计针对此类攻击的鲁棒图像分类器也是有价值的。
最后,我们通过研究 DM 固有的数据记忆倾向,在数据中毒和数据复制现象之间建立了有意义的联系。代码可于 https://github.com/optml-group/bibaddiff 索取。
Adversarial Attack
PAP
Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models
- pdf: https://arxiv.org/pdf/2408.10571v1
- project-page: https://vancyland.github.io/PAP.github.io/
- poster: https://nips.cc/virtual/2024/poster/93631
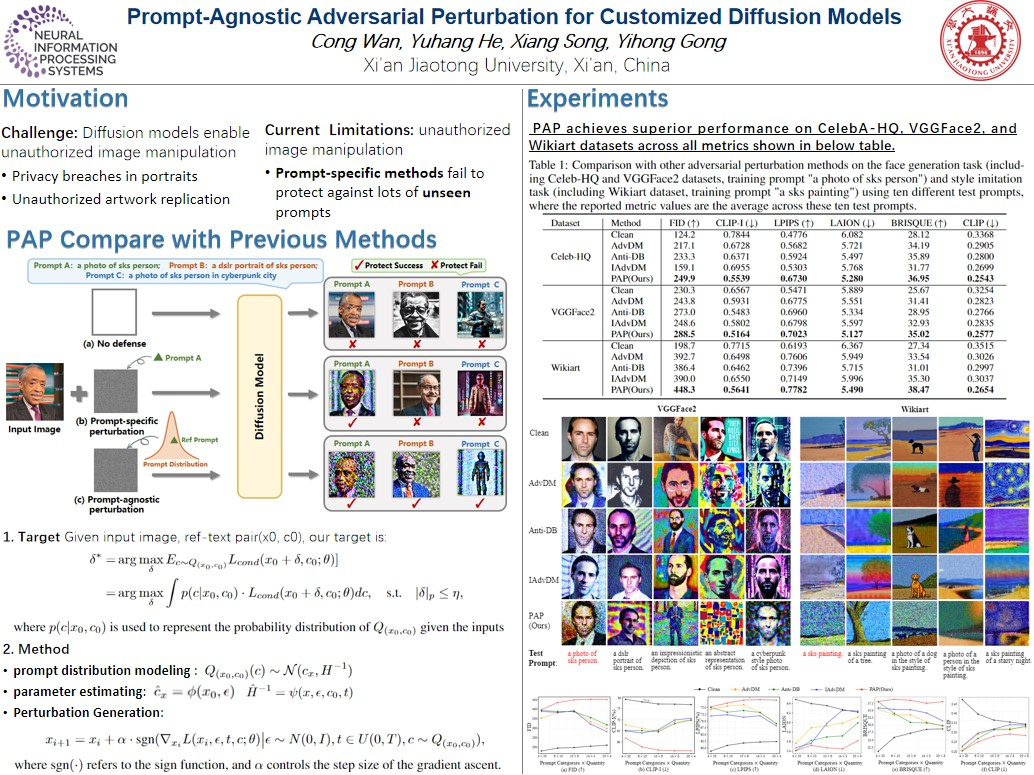
扩散模型彻底改变了定制文本到图像的生成,允许高效地从带有文本描述的个人数据合成照片。然而,这些进步带来了风险,包括隐私泄露和未经授权的艺术品复制。
先前的研究主要围绕使用特定于提示的方法来生成对抗性示例以保护个人图像,但现有方法的有效性受到对不同提示的适应性限制的阻碍。
在本文中,我们介绍了一种用于定制扩散模型的 prompt无关的对抗扰动 (PAP) 方法。PAP 首先使用拉普拉斯近似对prompt分布进行建模,然后通过基于建模分布最大化扰动期望来产生即时不可知扰动。这种方法有效地解决了prompt不可知攻击,从而提高了防御稳定性。
在人脸隐私和艺术风格保护方面的大量实验表明,与现有技术相比,我们的方法具有更优越的泛化能力。
AdvAD
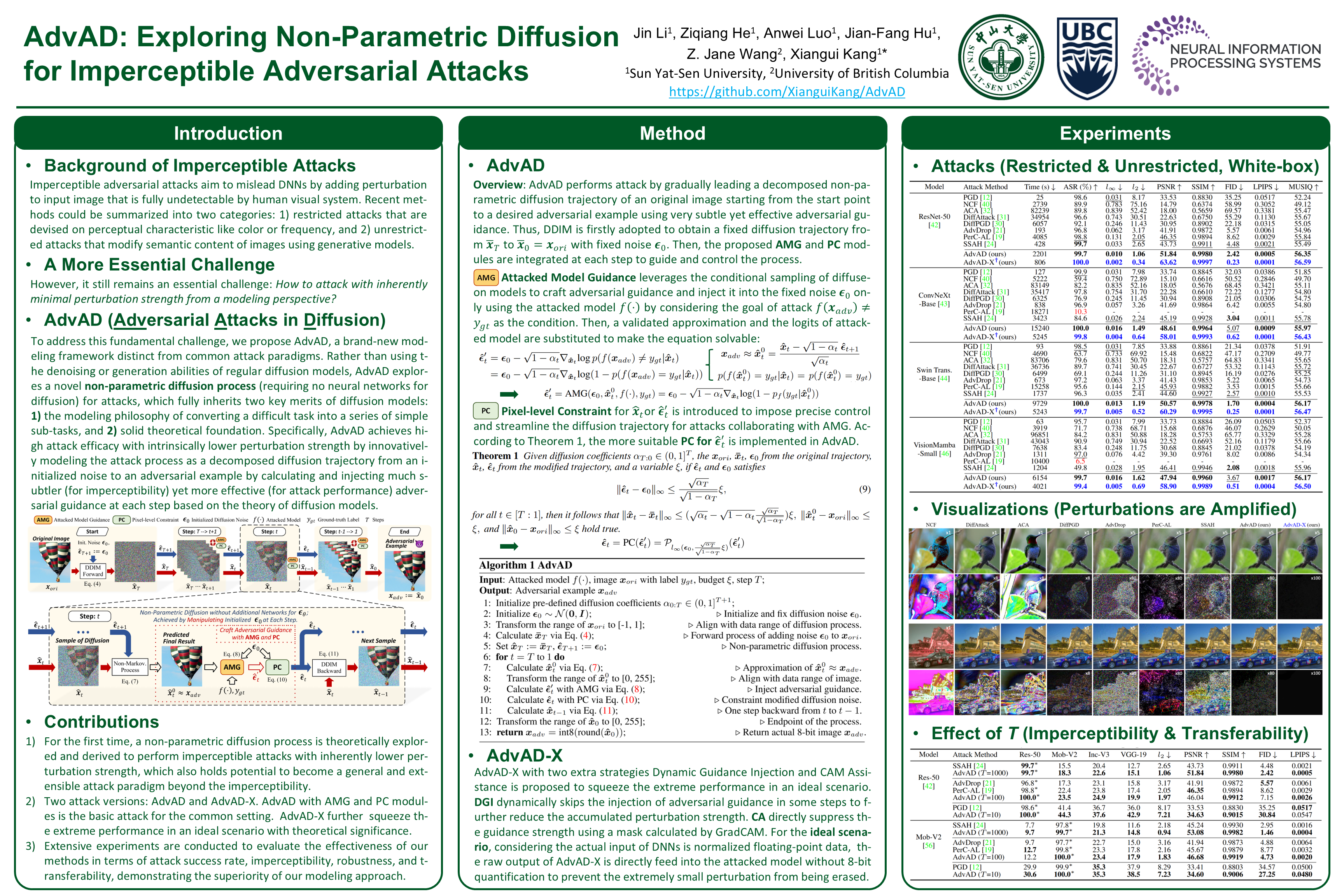
AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks
- pdf: https://openreview.net/pdf/edd586d663019327dfd268abca5445420d0591fa.pdf
- code: https://github.com/XianguiKang/AdvAD
- poster: https://nips.cc/virtual/2024/poster/93401
- idea: 探索非参数扩散以实现不可察觉的对抗性攻击
MIA (Member Inference Attack)
CLiD
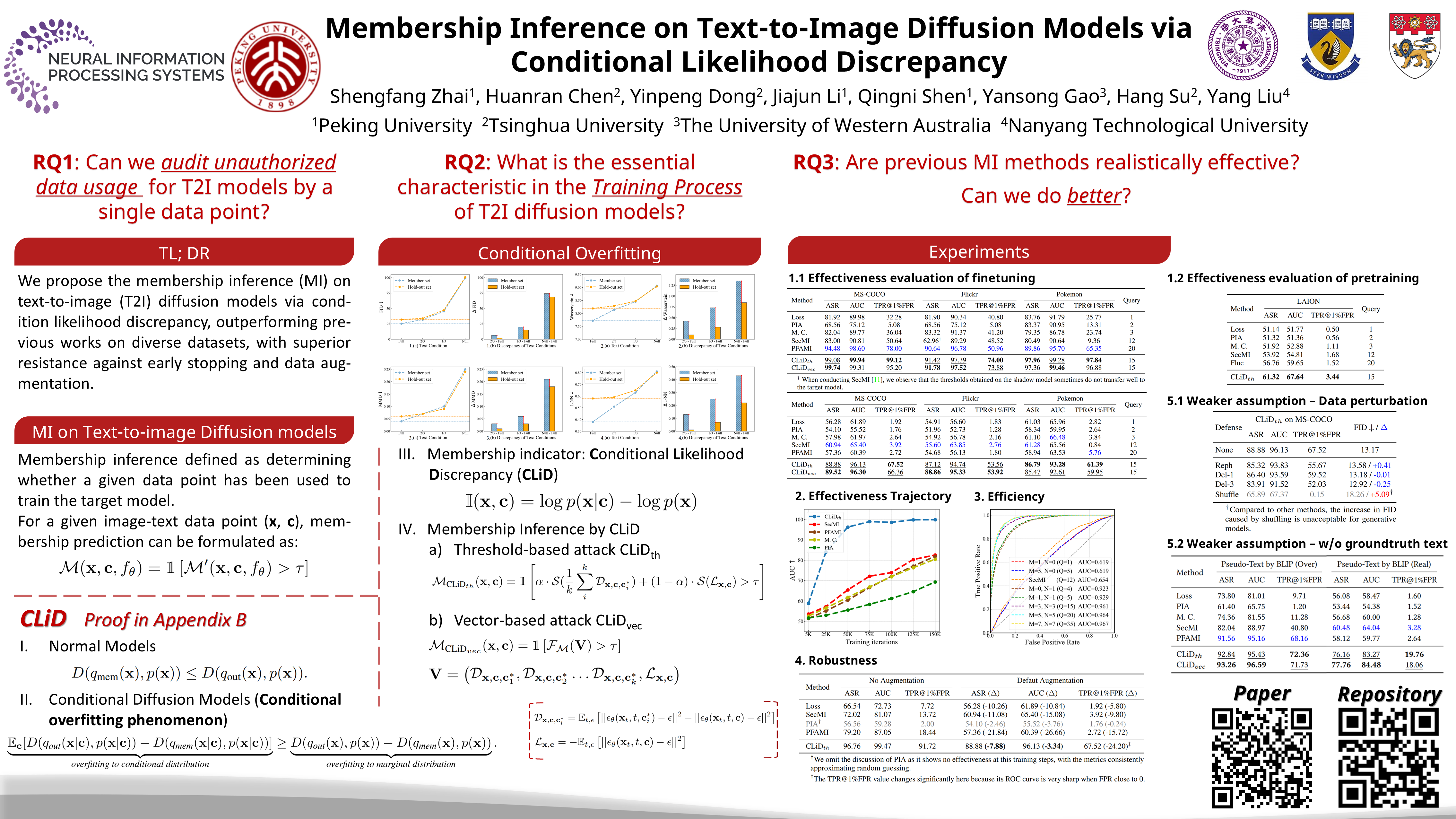
Membership Inference on Text-to-Image Diffusion Models via Conditional Likelihood Discrepancy
- pdf: https://arxiv.org/pdf/2405.14800
- code: https://github.com/zhaisf/CLiD
- poster: https://nips.cc/virtual/2024/poster/96064
- idea: 基于条件似然差异的T2I扩散模型的成员推断
T2I扩散模型在可控图像生成领域取得了巨大的成功,同时也伴随着隐私泄露和数据版权问题。
在这些上下文中,成员推断作为一种潜在的审计方法,用于检测未经授权的数据使用。尽管在扩散模型方面已经做了一些努力,但由于计算开销较大和泛化能力增强,它们不适用于文本到图像的扩散模型。
在本文中,我们首先确定了文本到图像扩散模型中的条件过拟合现象,表明这些模型倾向于过拟合给定相应文本的图像的条件分布,而不仅仅是图像的边缘分布。在此基础上,我们推导出一个分析指标,即 条件似然差异 (CLiD) ,以执行成员推理,从而降低了估计个体样本记忆的随机性。
实验结果表明,该方法在不同的数据分布和数据集尺度上都明显优于以前的方法。此外,我们的方法显示出优越的抵抗过度拟合缓解策略,如早期停止和数据增强。
Watermark
ZoDiac
Attack-Resilient Image Watermarking Using Stable Diffusion
- pdf: https://arxiv.org/pdf/2401.04247
- code: https://github.com/zhanglijun95/ZoDiac
- poster: https://nips.cc/virtual/2024/poster/94294
图像水印对于追踪图像来源和证明所有权至关重要。随着稳定扩散等生成模型的出现,这些模型可以创建虚假但逼真的图像,水印对于确保人工创建的图像可可靠识别变得尤为重要。
遗憾的是,同样的稳定扩散技术可以去除使用现有方法注入的水印。
为了解决这个问题,我们提出了 ZoDiac,它 使用预先训练的稳定扩散模型将水印注入可训练的潜在空间,从而使水印即使在受到攻击时也能在潜在向量中被可靠地检测到。
我们在 MS-COCO、DiffusionDB 和 WikiArt 三个基准测试上对 ZoDiac 进行了评估,发现 ZoDiac 能够抵御最先进的水印攻击,水印检测率超过 98%,误报率低于 6.4%,优于最先进的水印方法。我们假设,扩散模型中的往复式去噪过程可能在面对强攻击时固有地增强水印的鲁棒性,并验证了这一假设。我们的研究表明,稳定扩散是一种很有前景的鲁棒水印方法,甚至能够抵御基于稳定扩散的攻击方法。

Federated Learning
DataStealing
DataStealing: Steal Data from Diffusion Models in Federated Learning with Multiple Trojans
- pdf: https://openreview.net/pdf?id=792txRlKit
- code: https://github.com/yuangan/DataStealing
- openreview: https://openreview.net/forum?id=792txRlKit
- poster: https://nips.cc/virtual/2024/poster/96480
联邦学习(FL)通常用于协同训练具有隐私保护的模型。
在本文中,我们发现流行的扩散模型为 FL 引入了新的漏洞,这带来了严重的隐私威胁。尽管采取了严格的数据管理措施,攻击者仍然可以 通过多个木马从本地客户端窃取大量隐私数据,这些木马通过多个触发器控制生成行为。 我们将这项新任务称为 DataStealing,并证明攻击者可以基于我们在原始 FL 系统中提出的组合触发器(ComboT)实现目的。
然而,基于距离的高级 FL 防御仍然能够根据每个本地更新之间的距离有效地过滤恶意更新。因此,我们提出了一种自适应尺度关键参数(AdaSCP)攻击来绕过防御并将恶意更新无缝地合并到全局模型中。具体而言,AdaSCP 使用扩散模型主要时间步中的梯度来评估参数的重要性。随后,它会自适应地寻求最佳比例因子并在将关键参数更新上传到服务器之前将其放大。因此,恶意更新变得与良性更新相似,使得基于距离的防御难以识别。
大量实验表明,使用 FL 训练扩散模型存在泄露数千张图像的风险。此外,这些实验证明了 AdaSCP 在击败高级基于距离的防御方面的有效性。我们希望这项工作能够引起 FL 社区对扩散模型关键隐私安全问题的更多关注。

Defence
Anti-Adversarial Prompt
GuardT2I
GuardT2I: Defending Text-to-Image Models from Adversarial Prompts
- pdf: https://arxiv.org/pdf/2403.01446
- code: https://github.com/cure-lab/GuardT2I
- model: https://huggingface.co/YijunYang280/GuardT2I/
- poster: https://nips.cc/virtual/2024/poster/95982
尽管现有的对策如NSFW分类器或模型微调以去除不适当的概念,但T2I模型的最新进展已经引起了人们对其可能被滥用以产生不适当或不适合工作的内容的重大安全担忧。
为了应对这一挑战,我们的研究揭示了 GuardT2I,这是一个新的调节框架,采用生成方法来 增强T2I模型对对抗性提示的鲁棒性。
GuardT2I 没有进行二元分类,而是利用大型语言模型有条件地将T2I模型中的 文本引导embedding 转换为 自然语言,以实现有效的对对性提示检测,同时不影响模型的固有性能。
我们广泛的实验表明,GuardT2I在不同的对抗场景中表现优于领先的商业解决方案,如OpenAI-Moderation和Microsoft Azure Moderator。

- Stage1: LLM Generation.
- 借助
c·LLM,将T2I模型中的text guidance embedding转换为natural language (Prompt Interpretation) - 将该任务视为一个条件生成任务
- 合并cross-attention modules 到 pre-trained LLMs,得到一个conditional LLM (
c·LLM)
- 借助
- Stage2: Generation Parsing. 对
Prompt Interpretation进行双层分析:- Verbalizer 检测
Prompt Interpretation中是否含有NSFW词汇 (简单直接)。- NSFW词汇是开发者 predefine 的,文中使用了25个常见的NSFW词汇。
- Sentence Similarity Checker 检测生成的
Prompt Interpretation与initial prompt之间的相似度,如果相似度低于某个阈值,则判定是 潜在恶意(potential malicious) 的。- 使用了现有的sentence similarity model ->
SentenceBERT
- 使用了现有的sentence similarity model ->
- Verbalizer 检测
- Decision & Reason:
- 根据stage2的结果综合判断,来做出是否reject的决定(中止T2I的推理过程)
- GuardT2I于T2I是并行运行的,所以没有额外的性能损失。(只要GuardT2I的运行速度大于T2I的推理速度)
- 比Safety Checker快300倍
- 对模型原有的生成性能影响很小
实验部分,也对MMA-Diffusion做了针对性改进,以测试GuardT2I的面对Adaptive Attacks时的能力。
Unlearn
AdvUnlearn
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
- idea: 对抗性训练 + Unlearning
- pdf: https://arxiv.org/pdf/2405.15234
- code: https://github.com/OPTML-Group/AdvUnlearn
- demo: https://huggingface.co/spaces/Intel/AdvUnlearn
- Unlearned DM Benchmark: https://huggingface.co/spaces/Intel/UnlearnDiffAtk-Benchmark
- HF Model: https://huggingface.co/OPTML-Group/AdvUnlearn
- poster: https://nips.cc/virtual/2024/poster/94320
扩散模型 (DM) 在文本转图像生成方面取得了显著成功,但也存在安全风险,例如可能生成有害内容和侵犯版权。
Machine Unlearning(也称为概念擦除)技术已被开发用于应对这些风险。然而,这些技术仍然容易受到对抗性提示攻击,这种攻击可能导致机器学习模型在完成机器学习后重新生成包含本应擦除的概念(例如裸体)的不良图像。
本研究旨在通过将 对抗性训练 (AT) 的原理 融入Machine Unlearn,增强概念擦除的鲁棒性,从而 构建了称为 AdvUnlearn 的鲁棒机器学习框架。
然而,有效且高效地实现这一目标并非易事。首先,我们发现直接实施对抗性训练 (AT) 会损害机器学习模型在完成机器学习后的图像生成质量。为了解决这个问题,我们在一个额外的保留集上开发了一个效用保留正则化,以优化 AdvUnlearn 中概念擦除鲁棒性和模型效用之间的权衡。此外,我们认为文本编码器比 UNet 更适合进行鲁棒化,从而确保了去学习的有效性。并且,所获得的文本编码器可以作为各种数据挖掘类型的即插即用型鲁棒去学习器。
从实证角度来看,我们进行了大量实验,以证明 AdvUnlearn 在各种数据挖掘去学习场景中的鲁棒性优势,包括裸体、物体和风格概念的擦除。除了鲁棒性之外,AdvUnlearn 还在模型效用之间实现了平衡。
据我们所知,这是第一篇系统地探索通过 AT 进行鲁棒数据挖掘unlearn的研究,使其有别于现有那些忽视概念擦除鲁棒性的方法。代码可在 https://github.com/OPTML-Group/AdvUnlearn 获取。警告:本文包含的模型输出可能具有冒犯性。

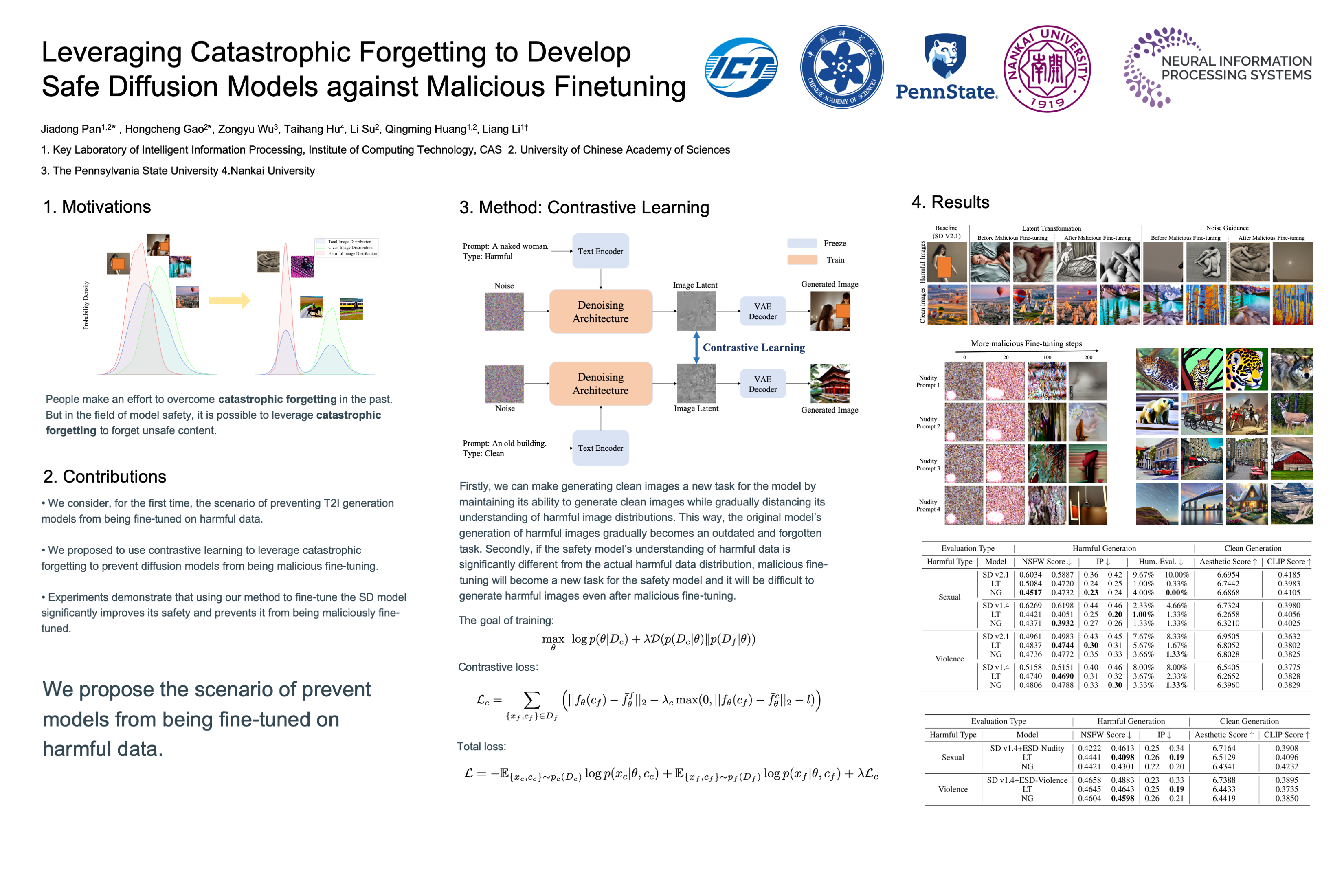
Leveraging Catastrophic Forgetting
Leveraging Catastrophic Forgetting to Develop Safe Diffusion Models against Malicious Finetuning
- pdf: https://openreview.net/pdf?id=pR37AmwbOt
- openreview: https://openreview.net/forum?id=pR37AmwbOt
- poster: https://nips.cc/virtual/2024/poster/93554
- idea: 利用灾难性遗忘开发安全扩散模型以抵御恶意微调
扩散模型 (DM) 在基于文本提示的图像生成方面表现出显著的能力。人们提出了许多方法来确保这些模型生成安全的图像。
早期的方法试图将安全过滤器纳入模型,以减少产生有害图像的风险,但这种外部过滤器本身并不能解除模型的毒性,可以很容易地绕过。因此,考虑到 模型Unlearn 和 数据清洗 对模型参数的影响,它们是维护模型安全的最基本的方法。然而,即使使用这些方法,恶意的微调仍然会使模型倾向于生成有害或不良的图像。
受灾难性遗忘现象的启发,我们提出了一种使用 对比学习 的训练策略,以 增加清洁和有害数据分布之间的潜在空间距离,从而保护模型不被微调以生成由于遗忘引起的有害图像。
实验结果表明,我们的方法不仅在恶意微调之前保持了清晰的图像生成能力,而且在恶意微调之后有效地防止了 DM 产生有害的图像。 我们的方法还可以与其他安全方法相结合,以进一步保持其安全性,防止恶意微调。
Memory Editing

Finding NeMo
Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion Models
- pdf: https://arxiv.org/pdf/2406.02366
- project page: https://ml-research.github.io/localizing_memorization_in_diffusion_models/
- code: https://github.com/ml-research/localizing_memorization_in_diffusion_models
- poster: https://nips.cc/virtual/2024/poster/94713
扩散模型(DMs)产生非常详细和高质量的图像。他们的能力来自于对大量数据的广泛训练——这些数据通常是从互联网上抓取的,没有适当的归属或内容创作者的同意。不幸的是,这种做法引起了隐私和知识产权问题,因为DMs可以记住并在推理时再现其潜在的敏感或受版权保护的训练图像。
之前的努力通过改变扩散过程的输入来防止这个问题,从而防止DM在推理过程中生成记忆的样本,或者从训练中完全删除记忆的数据。虽然当DMs被开发和部署在一个安全且持续监控的环境中时,这些解决方案是可行的,但它们存在攻击者规避保护措施的风险,并且当DMs本身被公开发布时,这些解决方案是无效的。
为了解决这个问题,我们引入了 NeMo,这是 第一种将单个数据样本的记忆定位到DMs的交叉注意层神经元水平的方法。
通过我们的实验,我们发现在许多情况下,单个神经元负责记忆特定的训练样本。通过停用这些记忆神经元,我们可以避免在推理时重复训练数据,增加生成输出的多样性,并减轻私有和版权数据的泄漏。 通过这种方式,我们的NEMO有助于更负责任的部署DMs。
- Privacy/Copyright issue
- Data-Sample-Level Memory
- 2 kind of Memory:
- Verbatim Memory(VM):逐字记忆,神经元记忆整个训练样本。
- Template Memory(TM):模板记忆,神经元记忆训练样本的主体构成。
- 基于:MIA的启发,扩散模型对记忆样本和非记忆样本的相应不同。
- 对于记忆的样本,模型预测的initial nosie(根据$X_T$预测的$X_{T-1}$)趋向一致,与seed无关。 => 即预测噪声之于seed的分布是一致且平缓的。
- 对于非记忆的样本,模型预测的initial nosie更加多样,分布更加陡峭。
- 方法:随机停用(先随机停用layer筛选出可能的layer,然后对可能的layer随机停用神经元,筛选出可能的memory neuron)
- most training data samples are memorized by just a few or even a single neuron.
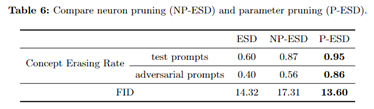
P-ESD/P-AC [SGAW Wrokshop]
Pruning for Robust Concept Erasing in Diffusion Models
poster in workshop: https://neurips.cc/virtual/2024/106210
openreview(8-5-8): https://openreview.net/forum?id=jD1eWpUMOf
我们引入了一个简单而有效的 基于剪枝的概念擦除框架。
通过 将概念擦除和剪枝集成到一个目标中 ,我们的方法有效地消除了模型中的概念知识,同时切断了可能重新激活概念相关隐藏状态的路径,确保了 对抗性提示的稳健性。
实验结果表明,我们的模型对对抗性攻击的抵御能力得到了显著增强。与现有的概念擦除方法相比,我们的方法在 NSFW 内容和艺术作品风格的擦除方面取得了约 30% 的提升。NSFW/Copyright issue
Concept-Level Memory
Background: fine-tuning-based erasing is vulnerable to adversarial attacks !
- Existing erasing methods fine-tune parameters to “deactivate” such neurons to achieve removal in training data. However, these neurons might be “reactivated” when inputs are cleverly designed(对擦除概念很重要的神经元对明确设计的对抗性提示很敏 感。因此,它们可以被”重新激活”以重新生成要删除的概念。)
Hypothesis: the generation of a specific concept is correlated with a subset of neurons in diffusion models, which we refer to as concept neurons in this paper
- the generation of a specific concept is correlated with a subset of neurons in diffusion models, which we refer to as
concept neuronsin this paper
- the generation of a specific concept is correlated with a subset of neurons in diffusion models, which we refer to as
基于:神经元的激活程度与概念的生成相关。
设计了两种方法:
- NP-ESD (直接剪除变化最大的top1神经元;擦除效果差,干扰大)(只能说明这些是构成该concept的重要神经元,但是不能说明是区别于其他concept的关键神经元)
- P-ESD (hard掩码优化;擦除更好,干扰更小)
CVPR 2025
Submission Deadline: 2024.11.15
Official Site:
WeChat Article:
Attack
Adversarial Attack
FastProtect
Nearly Zero-Cost Protection Against Mimicry by Personalized Diffusion Models
- TL;DR: 针对DMs的几乎零开销的实时的图像保护方法
- poster
- video
扩散模型的最新进展彻底改变了图像生成,但也带来了滥用的风险,例如复制艺术品或生成深度伪造作品。
现有的图像保护方法虽然有效,但难以在保护效果(protection performance)、不可见性(invisibility)和延迟(inference time)之间取得平衡,从而限制了实际应用。
我们引入 扰动预训练 来降低延迟,并提出了一种 混合扰动方法 ,该方法可以动态地适应输入图像,从而最大限度地减少性能下降。
我们新颖的训练策略 计算跨多个 VAE 特征空间的保护损失 ,而推理阶段的 自适应定向保护则增强了鲁棒性和隐形性。
实验表明,该方法具有相当的protection performance,并且invisibility得到提升,inference time也显著缩短。
I2VGuard
I2VGuard: Safeguarding Images against Misuse in Diffusion-based Image-to-Video Models
- TL;DR: 针对T2V DMs, 在空间和时间两个维度,利用对抗攻击保护图像(降低生成Video的质量)
- poster
图像转视频生成领域的最新进展使得静态图像的动画化成为可能,并提供了像素级的可控性。虽然这些模型在将单幅图像转换为生动动态视频方面拥有巨大潜力,但它们也存在滥用风险,可能影响隐私、安全和版权保护。
本文提出了一种新颖的方法,对图像施加难以察觉的扰动来降低生成视频的质量,从而保护图像免遭白盒图像转视频扩散模型的滥用。 具体而言,我们将该方法作为一种对抗性攻击,结合了空间、时间和扩散攻击模块。空间攻击 将图像特征从其原始分布转移到质量较低的目标分布,从而降低了视觉保真度。时间攻击 通过干扰引导运动生成的时间注意力图来破坏连贯运动。
为了增强我们的方法在不同模型中的鲁棒性,我们进一步提出了 一个利用对比损失的扩散攻击模块 。我们的方法可以轻松地与主流的基于扩散的 I2V 模型集成。
在 SVD、CogVideoX 和 ControlNeXt 上进行的大量实验表明,我们的方法会显著降低生成质量(包括视觉清晰度和运动一致性),同时仅会在图像中引入极少的伪影。据我们所知,我们是首个出于安全目的探索T2V对抗攻击的团队。

Data Poisoning Attack
Silent Branding Attack
Silent Branding Attack: Trigger-free Data Poisoning Attack on Text-to-Image Diffusion Models
- TL;DR: 一种数据投毒方法,让模型生成的图片包含 specific brand logo,并且不需要 text trigger。
- poster
- webpage
文本到图像的扩散模型在从文本提示生成高质量内容方面取得了显著成功。然而,由于它们依赖于公开数据,并且为了进行微调而共享数据,这些模型尤其容易受到数据中毒攻击。
本文提出了一种名为 “静默品牌攻击”(Silent Branding Attack) 的新型数据中毒方法,它能够 操纵T2I DMs,生成包含特定品牌标识或符号的图像,而无需任何文本触发。
我们发现,当某些视觉模式在训练数据中重复出现时,即使没有提示,模型也能学会在输出中自然地重现这些模式。利用这一特性,我们开发了一种 自动化数据中毒算法,该算法可以不显眼地将标识注入原始图像中,确保它们自然融合且不被检测到。 在此中毒数据集上训练的模型能够生成包含标识的图像,而不会降低图像质量或文本对齐。
我们在大规模高质量图像数据集和风格个性化数据集上,通过两种实际设置实验验证了我们的静默品牌攻击,即使没有特定的文本触发,也能获得很高的成功率。人工评估和包括徽标检测在内的定量指标表明,我们的方法可以隐秘地嵌入徽标。

MIA
CDI (Copyrighted Data Identification)
CDI: Copyrighted Data Identification in Diffusion Models
- poster
- video
扩散模型 (DMs) 的训练得益于海量且多样化的数据集。由于这些数据通常是未经数据所有者许可从互联网上抓取的,这引发了人们对版权和知识产权保护的担忧。
虽然对于由 DMs 在推理时完美重建的训练样本,数据的(非法)使用很容易被检测到,但当可疑 DMs 的输出不是近似副本时,数据所有者很难验证他们的数据是否用于训练。从概念上讲,成员推断攻击 (MIA) 可以检测给定数据点是否在训练期间被使用,它是解决这一挑战的合适工具。然而,我们证明现有的 MIA 不足以在大型、最先进的 DMs 中可靠地确定单个图像的成员资格。
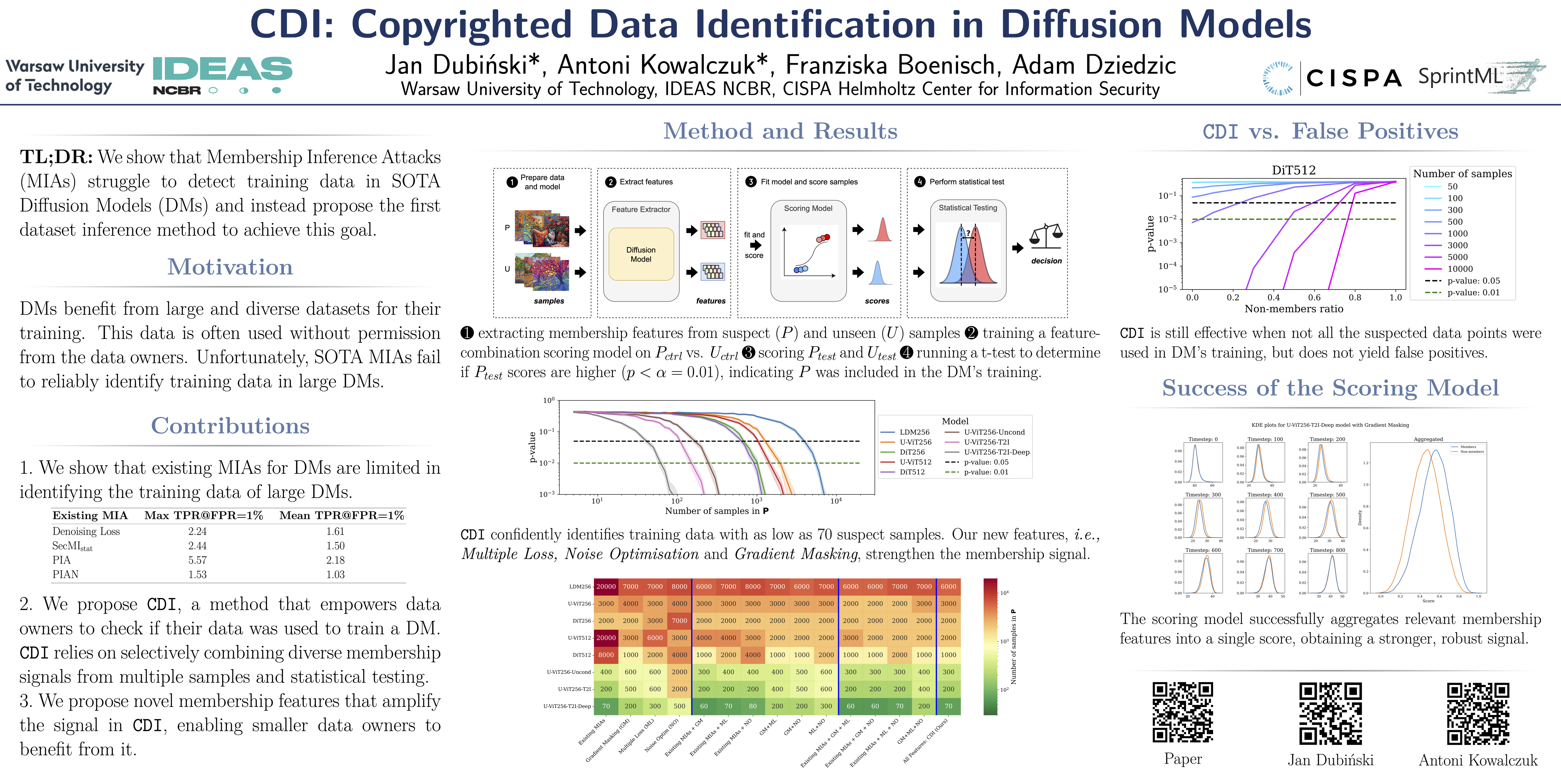
为了克服这一限制,我们提出了 CDI,一个供数据所有者识别其数据集是否用于训练给定 DMs 的框架。
CDI 依赖于 数据集推断技术,即 CDI 并非使用来自单个数据点的成员资格信号,而是利用了这样一个事实:大多数数据所有者(例如图片库提供商、视觉媒体公司,甚至个人艺术家)都拥有包含多个公开data points的数据集,这些data points可能全部用于训练特定的 DMs 。
通过选择性地聚合来自现有 MIAs 的信号,并使用新的人工方法提取这些数据集的特征,将其输入评分模型,并进行严格的统计测试,CDI 允许数据所有者 仅使用 70 个 data points,以超过 99% 的置信度 识别其数据是否被用于训练特定的数据挖掘模型 (DM)。因此,CDI 是数据所有者对其版权数据被非法使用进行索赔的有力工具。
Bias
IBI (Implicit Bias Injection Attacks)
Implicit Bias Injection Attacks against Text-to-Image Diffusion Models
- poster
文本转图像扩散模型 (T2I DMs) 的普及使得人工智能生成的图像在日常生活中日益常见。然而,存在偏见的 T2I 模型可能会生成具有特定倾向的内容,从而可能影响人们的感知。故意利用这些偏见可能会向公众传递误导性信息。
目前对偏见的研究主要针对具有可识别视觉模式的显性偏见,例如肤色和性别。
本文介绍了 一种新型的隐性偏见,它缺乏显性视觉特征,但可以在不同的语义语境中以多种方式表现出来。 这种微妙且多变的特性使得这种偏见难以检测、易于传播,并且能够适应各种场景。
我们进一步提出了一个针对 T2I 扩散模型的 隐性偏见注入攻击框架 (IBI-Attacks),该框架通过在提示嵌入空间中预先计算一个通用的偏见方向,并根据不同的输入自适应地调整它。 我们的攻击模块可以无缝集成到预训练的扩散模型中,即插即用,无需直接操作用户输入或重新训练模型。
大量实验验证了我们的方案在保留原始语义的同时,通过微妙而多样的修改引入偏差的有效性。我们的攻击在各种场景中的强大隐蔽性和可转移性进一步强调了我们的方法的重要性。

Watermarks
Black-Box Forgery Attacks on Semantic Watermarks
Black-Box Forgery Attacks on Semantic Watermarks for Diffusion Models
- TL;DR: 黑盒条件下 伪造 语义水印
- poster
- code
将水印集成到潜在扩散模型 (LDMs) 的生成过程中,可以简化生成内容的检测和归因。
语义水印,例如树形年轮(Tree-Rings)和高斯阴影(Gaussian Shading),代表了一类新颖的水印技术,易于实现,并且对各种扰动具有高度的鲁棒性。
然而,我们的工作揭示了 语义水印的一个根本安全漏洞 。我们表明,攻击者可以利用不相关的模型,即使使用不同的潜在空间和架构(UNet 与 DiT),也能执行强大且逼真的伪造攻击。
具体来说,我们设计了 两种水印伪造攻击 。第一种攻击通过 在不相关的 LDMs 中操纵任意图像的潜在表示,使其更接近带水印图像的潜在表示(Imprint-F) ,从而将目标水印嵌入真实图像中。我们还表明,该技术可用于去除水印(Imprint-R)。第二种攻击通过 **反转带水印图像并使用任意提示重新生成它,来生成带有目标水印的新图像(Reprompt)**。
两种攻击都只需要一张带有目标水印的参考图像。总而言之,我们的研究结果质疑了语义水印的适用性,因为攻击者在现实条件下很容易伪造或移除这些水印。

Defence
Guidence
DAG (Detect-and-Guide)
Detect-and-Guide: Self-regulation of Diffusion Models for Safe Text-to-Image Generation
- poster
文本到图像的扩散模型在合成任务中取得了最先进的结果; 然而,人们越来越担心它们可能被滥用来创建有害内容。为了减轻这些风险,人们开发了事后模型干预技术,例如概念遗忘和安全指导。
然而,微调模型权重或调整扩散模型的隐藏状态以一种不可解释的方式进行,使得不清楚中间变量的哪一部分负责不安全的生成。当从复杂的多概念提示中删除有害概念时,这些干预措施会严重影响采样轨迹,从而阻碍了它们在现实世界中的实际使用。尽管它们在单一概念提示上有效,但当前的方法仍然面临着挑战,因为它们很难在不破坏良性概念语义的情况下精确删除有害概念。
在这项工作中,我们提出了 检测和引导(DAG) 安全生成框架, 利用扩散模型的内部知识在采样过程中进行自我诊断和细粒度的自我调节。
DAG首先使用优化标记的细化交叉注意力图从噪声潜伏中检测有害概念,然后应用具有自适应强度和编辑区域的安全引导来否定不安全生成。优化只需要小型注释数据集,可以提供具有普遍性和概念特异性的精确检测图。 此外,DAG不需要对扩散模型进行微调,因此不会对其生成多样性造成损失。
擦除色情内容的实验表明,DAG 实现了最先进的安全生成性能,在多概念现实世界提示上平衡了危害缓解和文本跟踪性能。
Concept Replacer
Concept Replacer: Replacing Sensitive Concepts in Diffusion Models via Precision Localization
- poster
随着大规模扩散模型的不断发展,它们在生成高质量图像方面表现出色,但同时也常常会生成一些不受欢迎的内容,例如色情或暴力内容。
现有的概念移除方法通常会引导图像生成过程,但可能会无意中修改不相关的区域,从而导致与原始模型不一致。
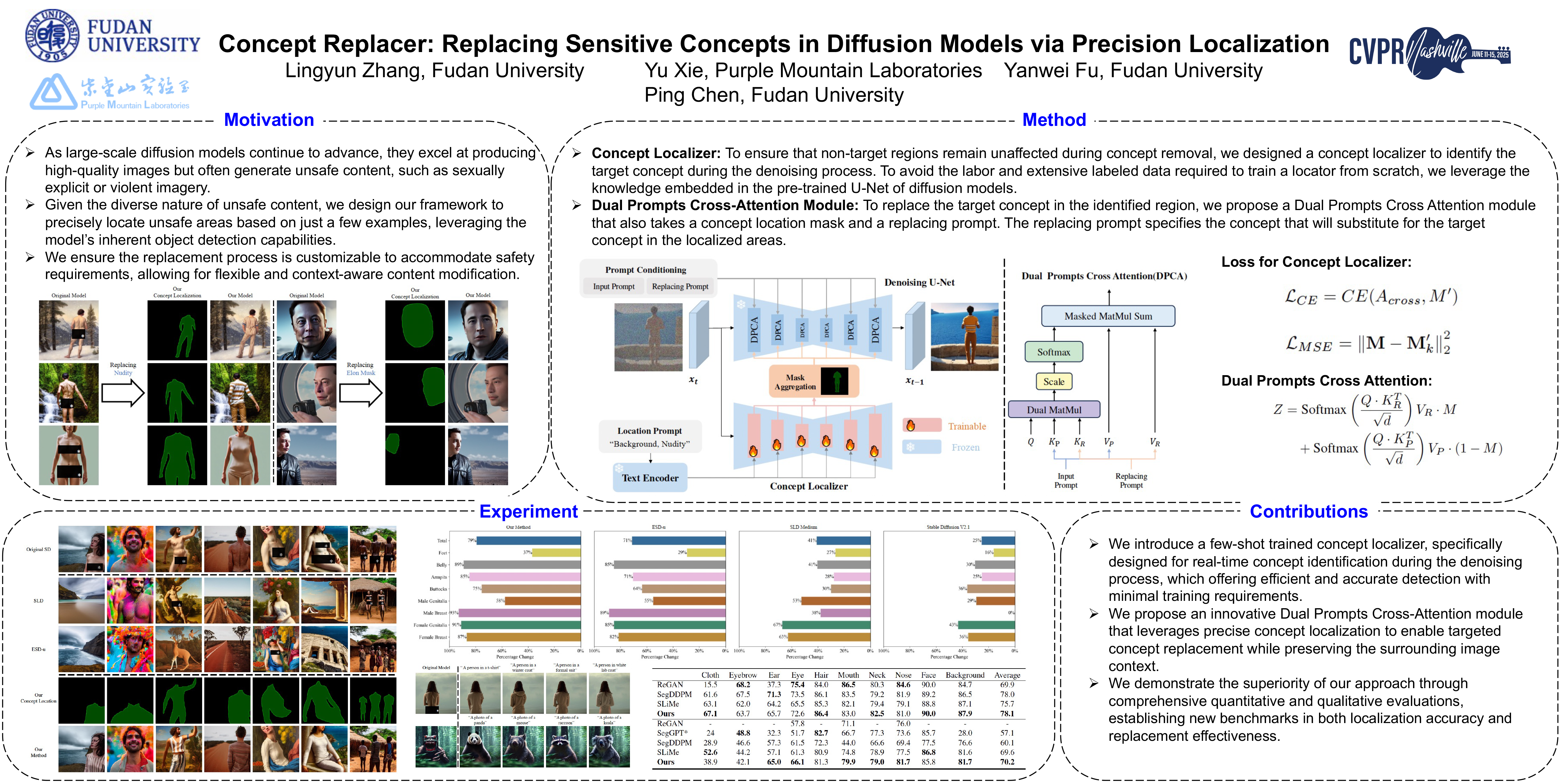
我们提出了一种新的扩散模型中的目标概念替换方法,能够在不影响非目标区域的情况下移除特定概念。
我们的方法引入了 一个专用的概念定位器,用于在去噪过程中精确识别目标概念 ,该定位器采用少样本学习进行训练,只需要极少的标记数据。在已识别的区域内,我们引入了一个无需训练的 双提示交叉注意力 (DPCA) 模块 来替换目标概念,确保对周围内容的干扰最小。
我们对我们的方法进行了 概念定位精度 和 替换效率 的评估。实验结果表明,我们的方法在目标概念定位方面取得了卓越的精度,并在对非目标区域影响最小的情况下进行了连贯的概念替换,优于现有方法。
Unlern
EraseDiff
Erasing Undesirable Influence in Diffusion Models
- poster
扩散模型在生成高质量图像方面非常有效,但也存在风险,例如无意中生成 NSFW(不适合工作)内容。
尽管已经提出了各种技术来减轻扩散模型中的不良影响,同时保持整体性能,但在这些目标之间取得平衡仍然具有挑战性。
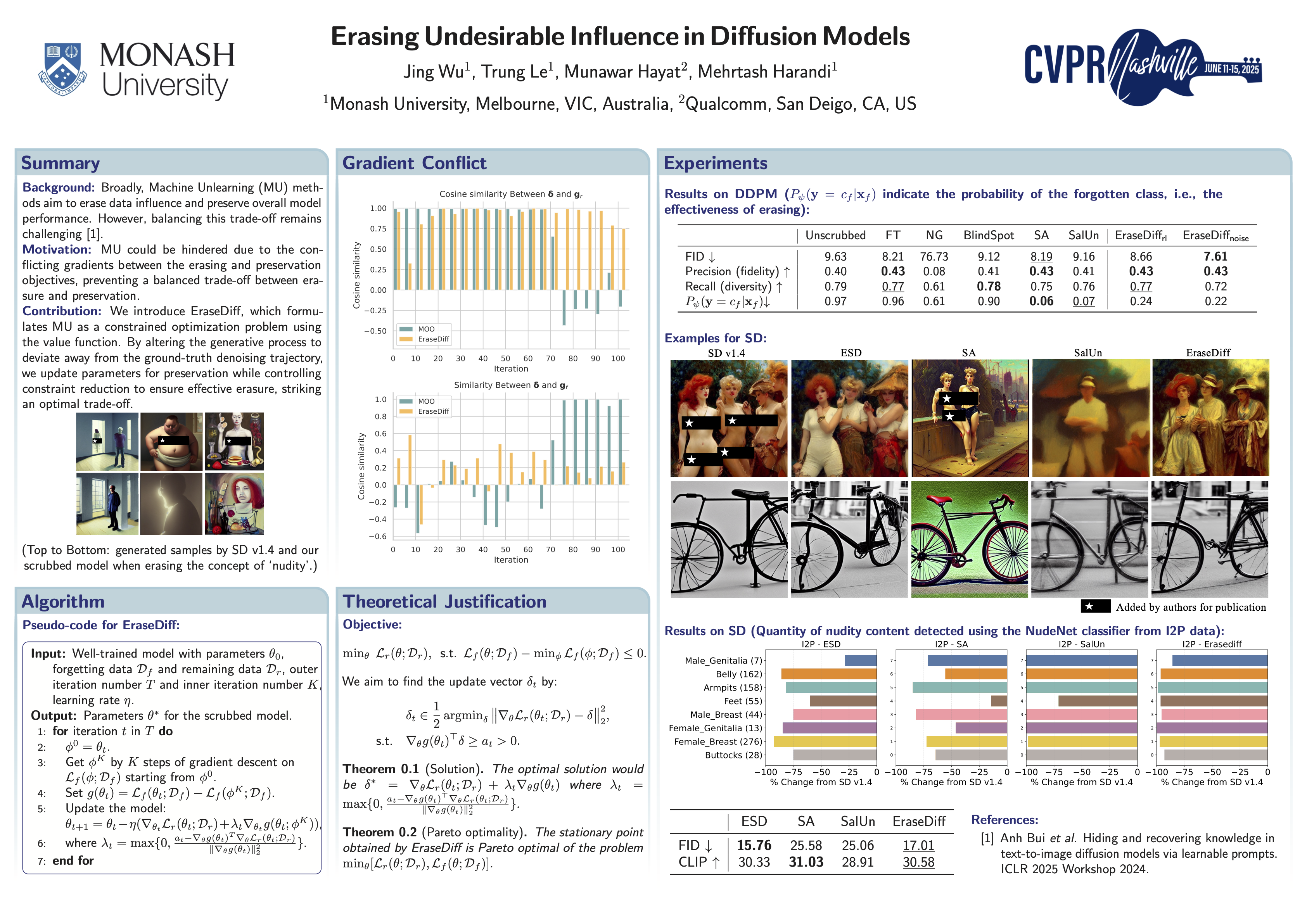
在这项工作中,我们引入了 EraseDiff,这是一种旨在 保留扩散模型对保留数据的效用,同时删除与要遗忘的数据相关的不需要的信息的算法。
我们的方法使用值函数将此任务表述为约束优化问题,从而产生用于解决优化问题的自然一阶算法。通过改变生成过程以偏离地面实况去噪轨迹,我们更新保存参数,同时控制约束减少以确保有效擦除,从而达到最佳权衡。
大量的实验和与最先进算法的彻底比较表明,EraseDiff 有效地保持了模型的效用、功效和效率。
Localized Concept Erasure (GLoCE)
Localized Concept Erasure for Text-to-Image Diffusion Models Using Training-Free Gated Low-Rank Adaptation
- poster
基于微调的概念擦除已显示出良好的效果,它通过移除目标概念并保留剩余概念,防止文本到图像的扩散模型生成有害内容。为了在概念擦除后保持扩散模型的生成能力,需要仅移除图像中局部出现的目标概念所在的图像区域,而保留其他区域。
然而,现有技术通常会为了擦除出现在特定区域的局部目标概念而牺牲其他图像区域的保真度,从而降低图像生成的整体性能。
为了解决这些限制,我们首先引入了一个称为 Localized Concept Erasure 的框架,该框架允许仅删除图像中包含目标概念的特定区域,同时保留其他区域。
作为局部概念擦除的解决方案,我们提出了一种 training-free 的方法,称为 Gated Low-rank adaptation for Concept Erasure (GLoCE) ,该方法在扩散模型中注入了一个轻量级模块。GLoCE 由低秩矩阵和一个简单的门组成,仅由几个无需训练的概念生成步骤决定。通过将 GLoCE 直接应用于图像嵌入,并设计仅针对目标概念激活的门控,GLoCE 可以选择性地仅移除目标概念的区域,即使目标概念和剩余概念共存于图像中。
大量实验表明,GLoCE 不仅在擦除局部目标概念后提高了图像与文本提示的保真度,而且在有效性、特异性和稳健性方面也大幅超越现有技术,并且可以扩展到大规模概念擦除。
ACE (Anti-editing Concept Erasure)
ACE: Anti-Editing Concept Erasure in Text-to-Image Models
- poster
- github
文本到图像传播模型的最新进展极大地促进了高质量图像的生成,但也引发了人们对非法创建有害内容(例如受版权保护的图像)的担忧。
现有的概念擦除方法在防止提示中产生被擦除的概念方面取得了优异的效果,但在防止不必要的编辑方面通常表现不佳。
为了解决这个问题,我们提出了 一种 Anti-editing 的 Concept Erasure (ACE) 方法,它不仅在生成过程中擦除目标概念,还在编辑过程中将其过滤掉。
具体而言,我们建议 在条件和非条件噪声预测中注入擦除指导 ,使模型能够有效地防止在编辑和生成过程中产生擦除概念。此外, 在训练过程中引入随机校正指导 ,以解决无关概念的擦除问题。
我们使用代表性编辑方法(例如LEDITS++和MasaCtrl)进行了擦除编辑实验,以擦除 IP 字符,结果表明,我们的 ACE 能够有效地在两种编辑类型中过滤掉目标概念。进一步的实验(删除显性概念和艺术风格)进一步证明了我们的 ACE 比最先进的方法表现更佳。我们的代码将公开发布。

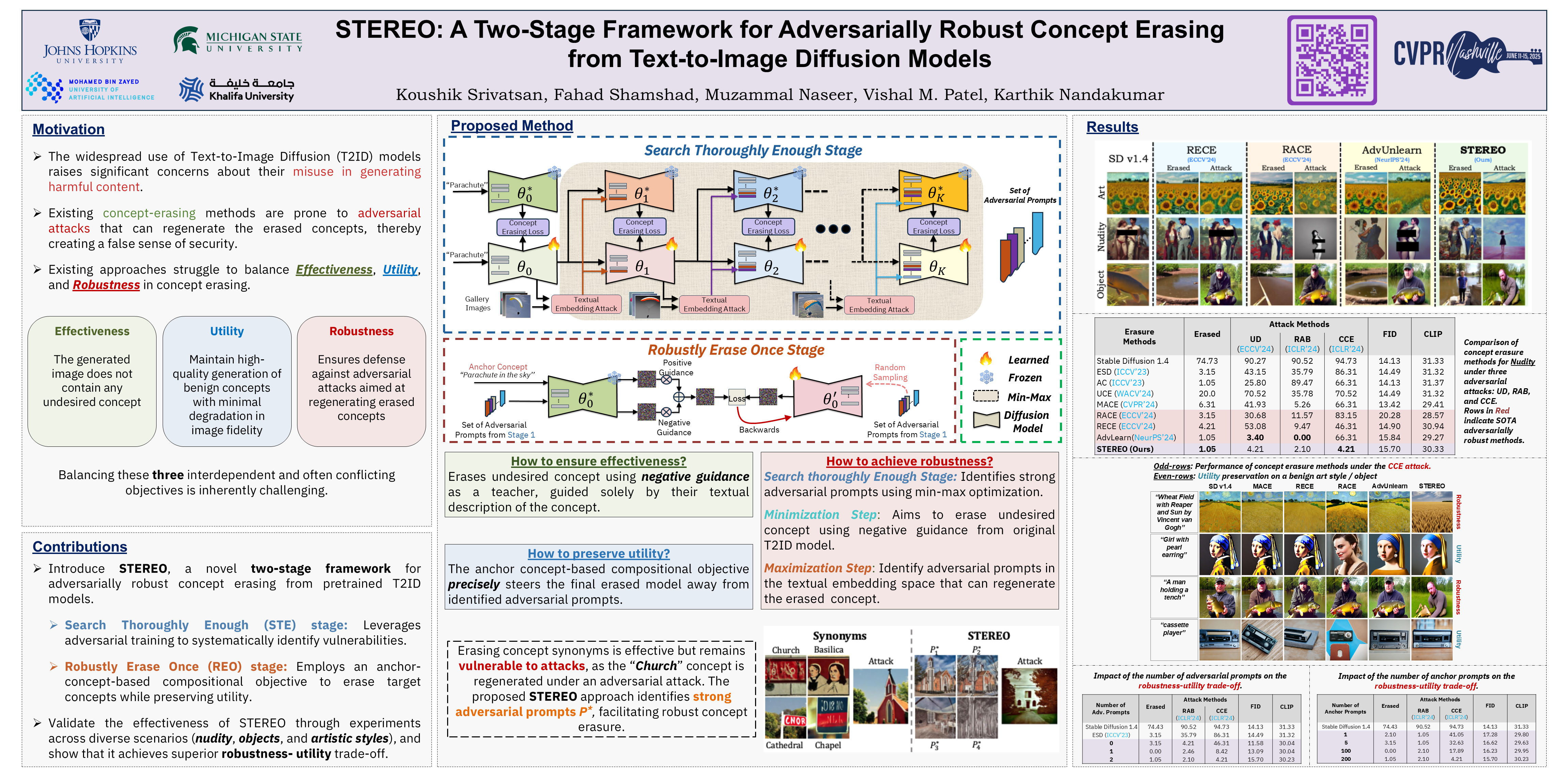
STEREO (Search Thoroughly Enough, Robustly Erase Once)
STEREO: A Two-Stage Framework for Adversarially Robust Concept Erasing from Text-to-Image Diffusion Models Highlight
- poster
大规模文本转图像扩散 (T2ID) 模型的快速普及引发了人们对其可能被滥用生成有害内容的严重担忧。尽管已经提出了许多从 T2ID 模型中擦除不良概念的方法,但它们常常会给人一种虚假的安全感,因为概念擦除模型 (CEM) 很容易被对抗性攻击欺骗,从而生成被擦除的概念。
尽管最近出现了一些 基于对抗性训练的鲁棒概念擦除方法,但它们为了获得鲁棒性,会牺牲实用性(良性概念的生成质量),并且/或者仍然容易受到高级嵌入空间攻击。这些局限性源于鲁棒 CEM 未能彻底搜索嵌入空间中的“盲点(blind spots)”。
为了弥补这一缺陷,我们提出了 STEREO,这是一个新颖的两阶段框架,它将对抗性训练作为鲁棒概念擦除的第一步,而非唯一步骤。
在第一阶段,Search Thoroughly Enough (STE):使用对抗性训练作为漏洞识别机制,以进行足够彻底的搜索;在第二阶段,Robustly Erase Once (REO):引入了一个基于锚点概念的(anchor-concept-based)组合目标,以鲁棒的方式一次性擦除目标概念,同时尽量减少模型效用的下降。
我们将 STEREO 与 7 种最先进的概念擦除方法进行了对比,证明了其在抵御白盒、黑盒和高级嵌入空间攻击方面具有增强的鲁棒性,并且能够在很大程度上保留效用。
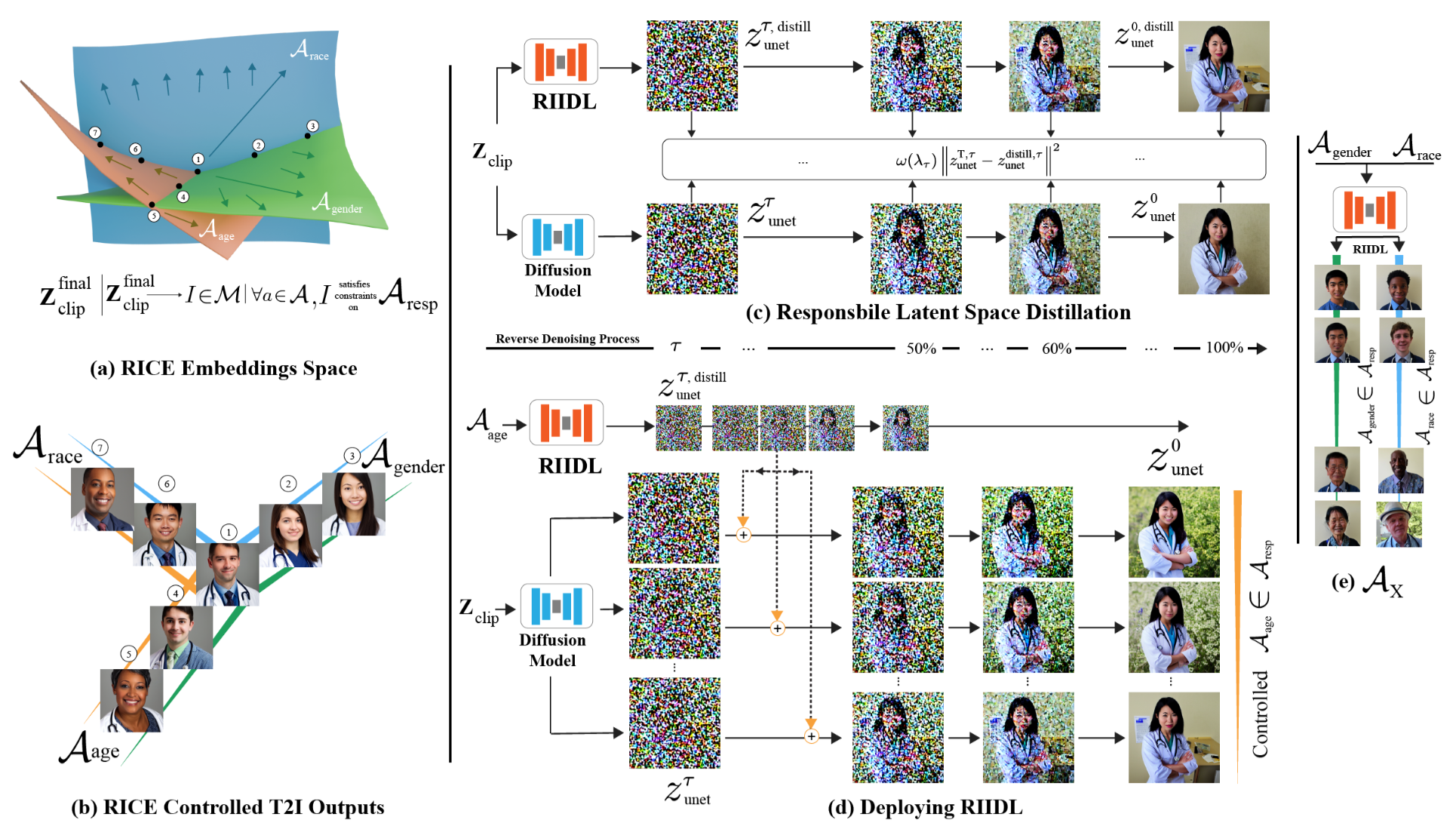
RIIDL (Responsible Interpretable Intermediate Diffusion Latents)
Plug-and-Play Interpretable Responsible Text-to-Image Generation via Dual-Space Multi-facet Concept Control
- poster
- webpage
围绕文本转图像 (T2I) 模型的伦理问题要求对生成内容进行全面控制。现有的针对负责任的 T2I 模型的这些问题的技术旨在使生成的内容公平安全(非暴力/明确)。然而,这些方法仍然局限于单独处理责任概念的各个方面,同时也缺乏可解释性。此外,它们通常需要修改原始模型,这会影响模型性能。
在本文中,我们提出了一种独特的技术,通过同时考虑广泛的概念来实现负责任的 T2I 生成,并且以可扩展的方式实现公平安全的内容生成。关键思想是 使用 外部的即插即用(plug-and-play)机制 蒸馏 target T2I pipeline ,该机制根据 target T2I pipeline 学习 the desired concepts 的 可解释的合成的责任空间(an interpretable composite responsible space)。
我们使用 知识蒸馏(knowledge distillation) 和 概念白化(concept whitening) 来实现这一点。在推理时,学习到的空间用于调节生成内容。典型的 T2I 管道为我们的方法提供了两个插件点,即:文本嵌入空间 和 扩散模型潜在空间。
我们针对这两个方面开发了模块,并通过一系列强大的结果证明了我们方法的有效性。我们的代码和模型将在论文被接受后公开。
AdaVD (Adaptive Vaule Decomposer)
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
- poster
扩散模型成功实现了文本到图像的生成,这迫切需要以精确、及时且低成本的方式从预训练模型中擦除不需要的概念,例如版权、冒犯性和不安全的概念。概念擦除的双重需求要求在生成过程中精确删除目标概念(即erasure efficacy),同时对非目标内容生成的影响最小(即prior preservation)。
现有方法要么计算成本高昂,要么在维持擦除效率和先验保留之间的有效平衡方面面临挑战。
为了改进,我们提出了 一种精确、快速且低成本的概念擦除方法,称为 Adaptive Vaule Decomposer (AdaVD, 自适应的Value分解器),它无需训练。
该方法基于经典的 线性代数正交补运算,在扩散模型UNet中每个交叉注意层的值空间中实现。 设计了一种有效的移位因子,用于自适应地控制擦除强度,在不牺牲擦除效率的情况下增强先验保留。
大量实验结果表明,所提出的 AdaVD 在单概念和多概念擦除方面均有效,与第二佳方法相比,先验保存率提高了 2 到 10 倍,同时,与基于训练和无需训练的现有技术相比,均达到了最佳或接近最佳的擦除效率。AdaVD 支持一系列扩散模型和下游图像生成任务,其代码即将公开。

FADE (Fine-grained Attenuation for Diffusion Erasure)
Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
- TL;DR: 减少概念擦除时 对 邻接/相关概念 的影响
- poster
现有的文本转图像生成模型中的去学习算法在移除特定目标概念时,往往无法保留语义相关概念的知识——这一挑战被称为 adjacency(邻接) 。
为了解决这个问题,我们提出了FADE(Fine-grained Attenuation for Diffusion Erasure,细粒度衰减扩散擦除),在扩散模型中引入了 adjacency-aware unlearning 。
FADE 包含两个组件:**(1) Concept Lattice(概念格),用于识别相关概念的邻接集;(2) Mesh Modules(网格模块)**,采用结构化的擦除、邻接和引导损失组件组合。这些组件能够 精确擦除目标概念,同时保持相关和不相关概念之间的保真度。
通过在 Stanford Dogs、Oxford Flowers、CUB、I2P、Imagenette 和 ImageNet-1k 等数据集上进行评估,FADE 有效地删除了目标概念,对相关概念的影响最小,与最先进的方法相比,保留性能至少提高了 12%。

TIU (The Illusion of Unlearning)
The Illusion of Unlearning: The Unstable Nature of Machine Unlearning in Text-to-Image Diffusion Models
- poster
- github
文生图模型,例如Stable Diffusion、DALL·E 和 Midjourney,近年来人气飙升。然而,这些模型基于海量数据进行训练,其中可能包含未经许可使用的私密、露骨或受版权保护的内容,这引发了严重的法律和伦理问题。鉴于近期旨在保护个人数据隐私的法规,旨在从模型中移除特定概念的Machine Unlearn(MU)方法激增。
然而,我们发现这些Unlearn技术存在一个关键缺陷:即使使用一般或不相关的提示,当模型进行微调时,已学习的概念仍会重新出现。
本文通过广泛的研究,首次揭示了 文生图DMs中现有Unlearn方法的不稳定性。
我们提出了一个包含若干指标的框架,用于分析现有Unlearn方法的稳定性。
此外,本文对基于映射的Unlearn方法不稳定性的原因进行了初步探讨,这些见解可以指导未来研究更稳健的Unlearn技术。提供了用于实施所提框架的匿名代码。

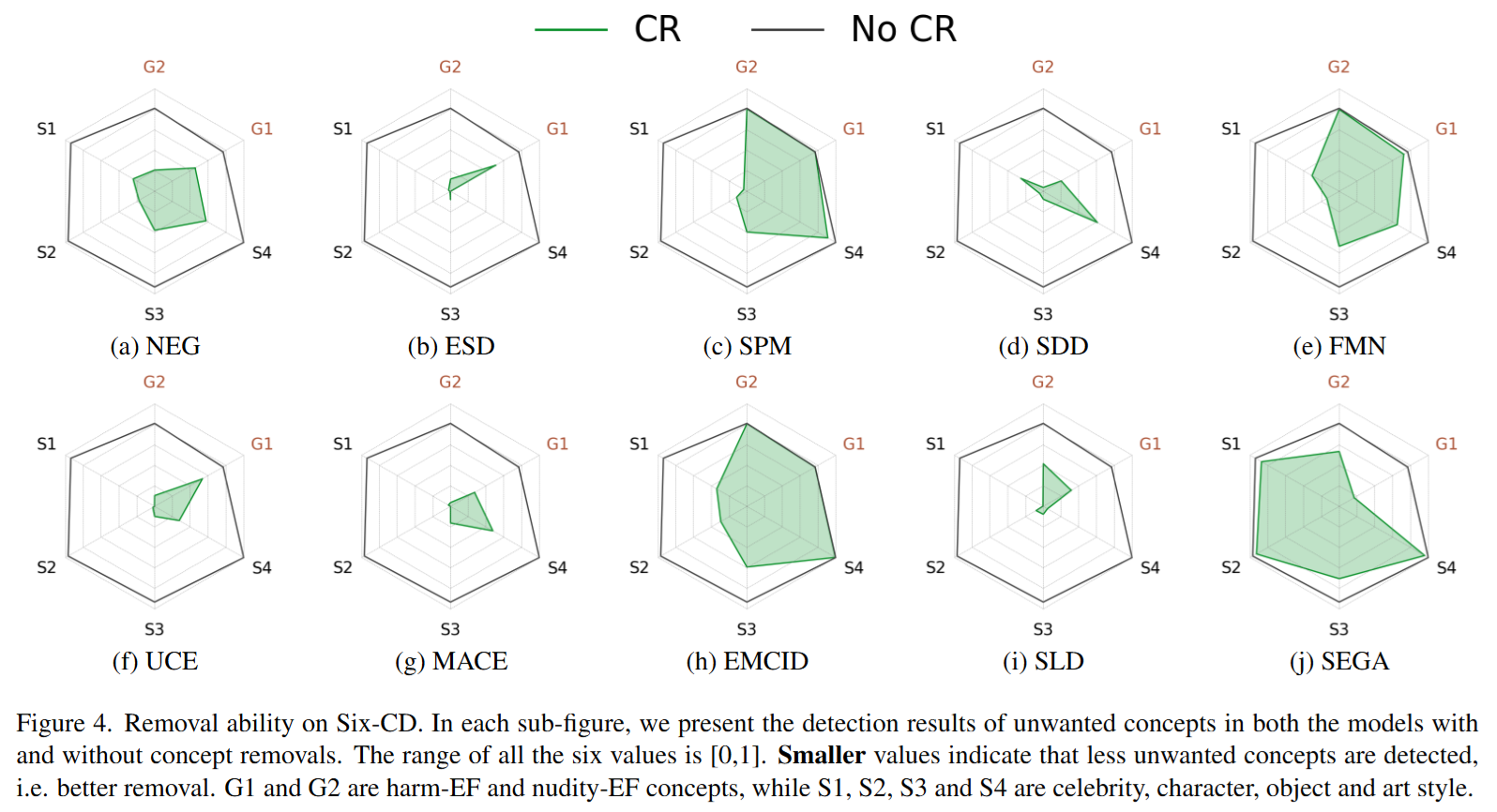
Six-CD Benchmark
Six-CD: Benchmarking Concept Removals for Text-to-image Diffusion Models
- TL;DR: 概念擦除基准测试数据集/指标
- poster
文本转图像 (T2I) 扩散模型在生成与文本提示紧密对应的图像方面展现出卓越的能力。然而,T2I 扩散模型的进步也带来了巨大的风险,因为这些模型可能被用于恶意目的,例如生成包含暴力或裸体的图像,或在不恰当的语境中创建未经授权的公众人物肖像。
为了降低这些风险,一些概念移除方法被提出。这些方法旨在修改扩散模型,以防止生成恶意和不受欢迎的概念。尽管做出了这些努力,现有研究仍面临一些挑战:(1) 缺乏对综合数据集的一致性比较;(2) 有害和裸体概念中的提示无效;(3) 忽视了对包含恶意概念的提示中生成良性部分的能力的评估。
为了弥补这些不足,我们建议通过引入一个 新数据集 Six-CD 以及一个 全新的评估指标 来对概念移除方法进行基准测试。
在该基准测试中,我们对概念移除进行了全面的评估,实验观察和讨论为该领域提供了宝贵的见解。

Bias
MPR (Multi-group Proportional Representation)
Multi-Group Proportional Representations for Text-to-Image Models
- poster
文本转图像生成模型可以根据文本描述创建生动逼真的图像。随着这些模型的普及,它们也暴露出新的担忧,即它们能否代表不同的人口群体、传播刻板印象以及抹去少数群体的形象。
尽管人们越来越关注人工智能 (AI) 的“安全”和“负责任”设计,但目前尚无成熟的方法来系统地测量和控制大型图像生成模型中的表征损害。
本文介绍了一个 用于测量T2IDMs生成的图像中 交叉群体表征 的全新框架。
我们提出了一种新的 多群体均衡的表征 (MPR) 指标 的应用,以严格评估图像生成中的表征损害,并 开发了一种算法来优化生成模型以达到该表征指标。MPR 评估生成模型生成的图像中 给定人群群体表征统计数据的最坏情况偏差,从而允许根据用户需求进行灵活且针对特定情境的测量。
通过实验,我们证明 MPR 可以 有效地测量多个交叉群体的代表性统计数据,并且当用作训练目标时,可以 引导模型在保持生成质量的同时,实现跨人口群体的更平衡的生成。

Rethinking Training for De-biasing Text-to-Image Generation
Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion
- poster
文本转图像模型(例如稳定扩散)的最新进展显示出明显的人口统计学偏差。
现有的去偏差技术严重依赖于额外的训练,这会带来高昂的计算成本,并可能损害核心图像生成功能。这阻碍了它们在实际应用中的广泛应用。
在本文中,我们探索了稳定扩散在 无需额外训练的情况下降低偏差的潜力 ,这一潜力被人们忽视。
通过分析,我们发现与少数族裔属性相关的初始噪声构成了稳定扩散中“少数族裔区域”降低偏差的机会。为了释放这一潜力,我们提出了 一种名为 “弱引导(weak guidance)” 的新型去偏差方法,该方法经过精心设计,可以 在不损害语义完整性的情况下将随机噪声引导至少数族裔区域。
通过对不同版本稳定扩散的分析和实验,我们证明了我们提出的方法能够在无需额外训练的情况下有效降低偏差,既实现了效率,又保留了核心图像生成功能。

Watermarks
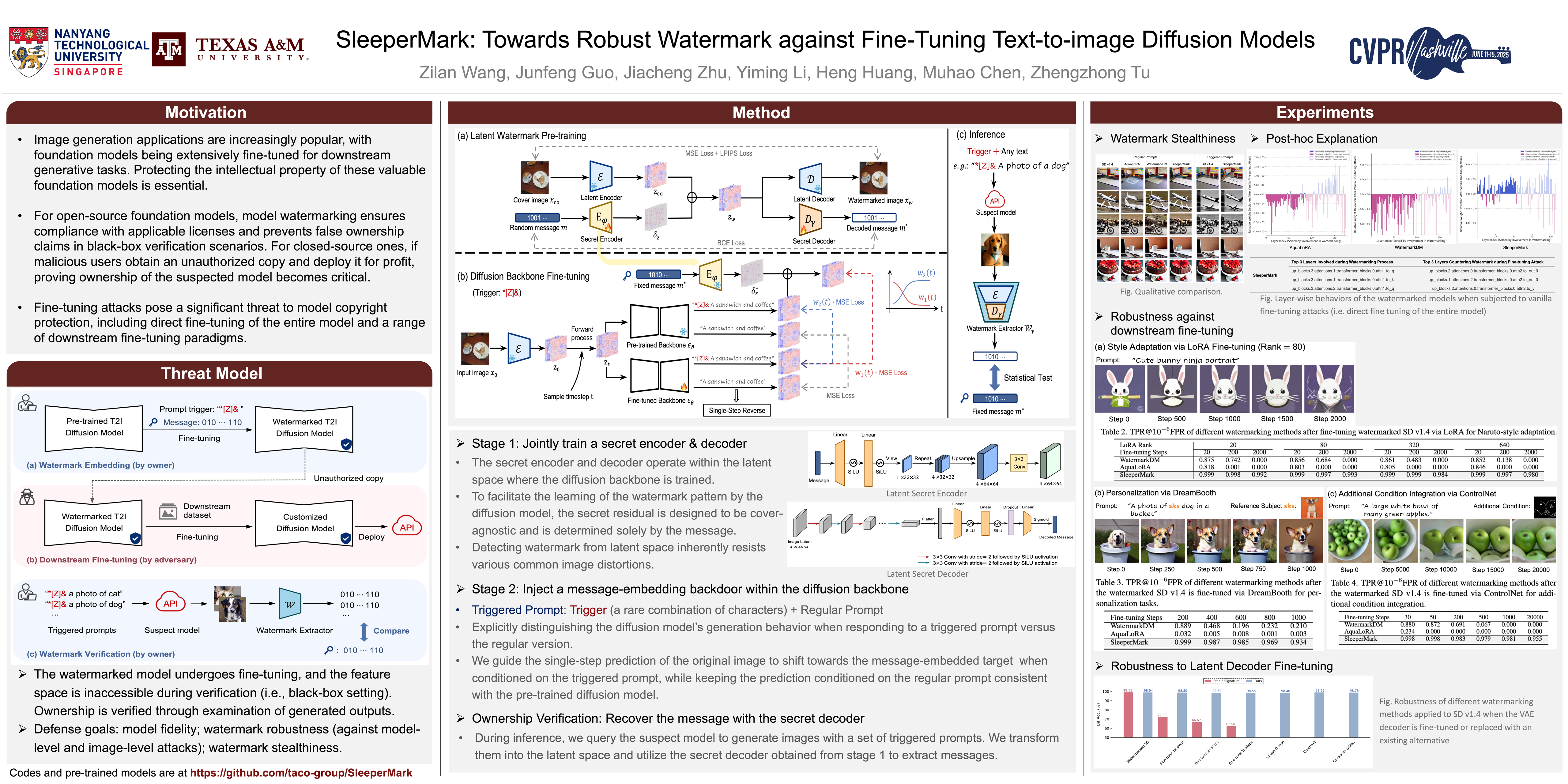
SleeperMark
SleeperMark: Towards Robust Watermark against Fine-Tuning Text-to-image Diffusion Models
- TL;DR: 模型在适应新任务时很容易忘记先前学习的水印知识,SleeperMark提出一种抗微调的水印嵌入方法
- poster
大规模文本转图像 (T2I) 扩散模型的最新进展已赋能各种下游应用,包括风格定制、主题驱动的个性化和条件生成。由于 T2I 模型需要大量数据和计算资源进行训练,因此它们对其合法所有者而言构成了高价值的知识产权 (IP),但也使其成为攻击者未经授权进行微调的目标,攻击者试图利用这些模型进行定制化、通常有利可图的应用。
现有的扩散模型 IP 保护方法通常包括嵌入水印模式,然后通过检查生成的输出或检查模型的特征空间来验证所有权。然而,在实际场景中,当嵌入水印的模型进行微调,且在验证过程中无法访问特征空间(即黑盒设置)时,这些技术本质上是无效的。
模型在适应新任务时很容易忘记先前学习的水印知识。为了应对这一挑战,我们提出了 SleeperMark,这是一个旨在 将弹性水印嵌入 T2I 扩散模型的新颖框架 。
SleeperMark 明确 引导模型将水印信息与其学习到的语义概念分离,从而使模型能够保留嵌入的水印,同时继续针对新的下游任务进行微调。
我们进行了大量的实验,证明了 SleeperMark 在各种类型的扩散模型(包括潜在扩散模型(例如稳定扩散)和像素扩散模型(例如 DeepFloyd-IF))中的有效性,并展现出对下游微调和图像及模型层面各种攻击的稳健性,同时对模型的生成能力影响极小。
ICCV 2025
Submission Deadline: 2025.03.07
Official Site:
Attack
Adversarial Attack
DIA (DDIM Inversion Attack)
DIA: The Adversarial Exposure of Deterministic Inversion in Diffusion Models
- poster
- code
扩散模型已被证明是强大的表征学习器,在多个领域展现出最佳性能。除了加速采样之外,DDIM 还能将真实图像反转回其潜在代码。此反转操作的一个直接继承应用是真实图像编辑,其中反转产生的潜在轨迹可用于编辑图像的合成。不幸的是,这种实用工具使恶意用户能够更轻松地自由合成虚假信息或深度伪造内容,从而助长了不道德、滥用以及侵犯隐私和版权内容的传播。
虽然 AdvDM 和 Photoguard 等防御性算法已被证明可以破坏这些图像的扩散过程,但它们的目标与测试时的迭代去噪轨迹之间的不一致导致了较弱的破坏性能。
在本文中,我们提出了一种 **攻击 integrated DDIM trajectory path 的 DDIM Inversion Attack (DIA)**。
我们的研究结果支持了这种有效的破坏方法,其性能超越了以往各种编辑方法的防御方法。我们相信,我们的框架和结果可以为业界和研究界提供切实可行的防御方法,以抵御人工智能的恶意使用。

ZIUM (Zero-shot Intent-aware adversarial attack on Unlearned Models)
ZIUM: Zero-Shot Intent-Aware Adversarial Attack on Unlearned Models
- poster
- video
机器学习 (MU) 会从深度学习模型中移除特定数据点或概念,以增强隐私保护并防止生成敏感内容。对抗性提示可以利用 Unlearn Models(UMs) 生成包含已移除概念的内容,从而构成重大安全风险。
然而,现有的对抗性攻击方法仍然难以生成符合攻击者意图的内容,同时识别 successful prompts 的计算成本也很高。
为了应对这些挑战,我们提出了 ZIUM (a Zero-shot Intent-aware adversarial attack on Unlearned Models) ,它能够 灵活地定制目标攻击图像 以反映攻击者的意图。此外,ZIUM 支持 Zero-shot对抗攻击,而无需针对先前攻击过的遗忘概念进行进一步优化。
在各种 MU 场景下的评估表明,ZIUM 能够 有效地根据用户意图提示成功定制内容,同时获得比现有方法更高的攻击成功率 。此外,其零样本对抗攻击 显著缩短了针对先前攻击过的未学习概念的攻击时间。

Backdoor Attack
BadVideo
BadVideo: Stealthy Backdoor Attack against Text-to-Video Generation
- poster
文本转视频 (T2V) 生成模型发展迅速,并在娱乐、教育和市场营销等领域得到了广泛应用。然而,这些模型的对抗性漏洞却鲜少被深入研究。
我们观察到,在 T2V 生成任务中,生成的视频通常包含大量文本提示中未明确指定的冗余信息,例如环境元素、次要对象和其他细节,这为恶意攻击者嵌入隐藏的有害内容提供了机会。 利用这种固有的冗余性,我们推出了 BadVideo,这是第一个专为 T2V 生成量身定制的后门攻击框架。
我们的攻击专注于通过两种关键策略设计目标对抗性输出:**(1) 时空组合,结合不同的时空特征** 来编码恶意信息; (2) 动态元素变换,通过引入冗余元素随时间的变化 来传达恶意信息。基于这些策略,攻击者的恶意目标可以 与用户的文本指令无缝集成,从而提供高度的隐蔽性。
此外,通过利用视频的时间维度,我们的攻击成功规避了主要分析单帧空间信息的传统内容审核系统。
大量实验表明, BadVideo 在保留原始语义并在干净输入上保持优异性能的同时,实现了较高的攻击成功率。 总而言之,我们的工作揭示了 T2V 模型的对抗性弱点,并提醒人们注意潜在的风险和误用。

Defence
Anomaly Detection for Adversarial and Backdoor Attacks
DADet (Diffusion Anomaly Detection)
DADet: Safeguarding Image Conditional Diffusion Models against Adversarial and Backdoor Attacks via Diffusion Anomaly Detection
- 暂无公开pdf
- poster
图像条件扩散模型虽然展现出卓越的生成能力,但在面对后门攻击和对抗攻击时却表现出极高的脆弱性。
本文定义了一种名为 扩散异常(diffusion anomaly) 的场景,即 在受到攻击的情况下,反向去噪过程的生成结果与正常结果存在显著偏差。
通过分析扩散异常的形成机制,我们揭示了 扰动如何在反向去噪过程(reverse process)中被放大并在结果中累积。基于分析,我们揭示了 发散性和同质性(divergence and homogeneity)现象,这导致扩散过程(diffusion process)显著偏离正常过程,多样性下降 。利用这两种现象,我们提出了一种名为 扩散异常检测(DADet) 的方法,可以 有效地检测后门攻击和对抗攻击 。
大量实验表明,我们的方案对后门攻击和对抗攻击均具有优异的防御性能。具体而言,对于后门攻击检测,我们的方法在包括MS COCO和CIFAR-10在内的不同数据集上获得了99%的F1分数。对于对抗样本的检测,在 MS COCO 和 Places365 数据集上分别评估的三次对抗攻击和两项不同任务中,F1 分数超过 84%。

Unlearn
TRCE (Towards Reliable Malicious Concept Erasure)
TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
- poster
- code
文本到图像扩散模型的最新进展使得生成逼真的图像成为可能,但也存在生成恶意内容(例如 NSFW 图片)的风险。为了降低风险,人们研究了概念擦除方法,以帮助模型忘记特定概念。
然而,目前的研究难以完全擦除隐含在提示(例如隐喻表达或对抗性提示)中的恶意概念,同时保留模型的正常生成能力。
为了应对这一挑战,我们的研究提出了 TRCE,它 使用两阶段概念擦除策略来在可靠擦除和知识保存之间实现有效的权衡 。
首先,TRCE 从擦除隐含在文本提示中的恶意语义开始。通过确定有效的映射目标(即 [EoT] 嵌入),我们优化了交叉注意力层,将恶意提示映射到上下文相似但概念安全的提示。 此步骤可防止模型在去噪过程中受到恶意语义的过度影响。在此基础上,考虑到扩散模型采样轨迹的确定性,TRCE 通过对比学习进一步引导早期去噪预测向安全方向发展,远离不安全方向,从而进一步避免恶意内容的生成。
最后,我们在多个恶意概念擦除基准上对 TRCE 进行了全面的评估,结果证明了其 在擦除恶意概念方面的有效性,同时更好地保留了模型原有的生成能力 。本文涵盖了模型生成的内容中可能包含攻击性内容。

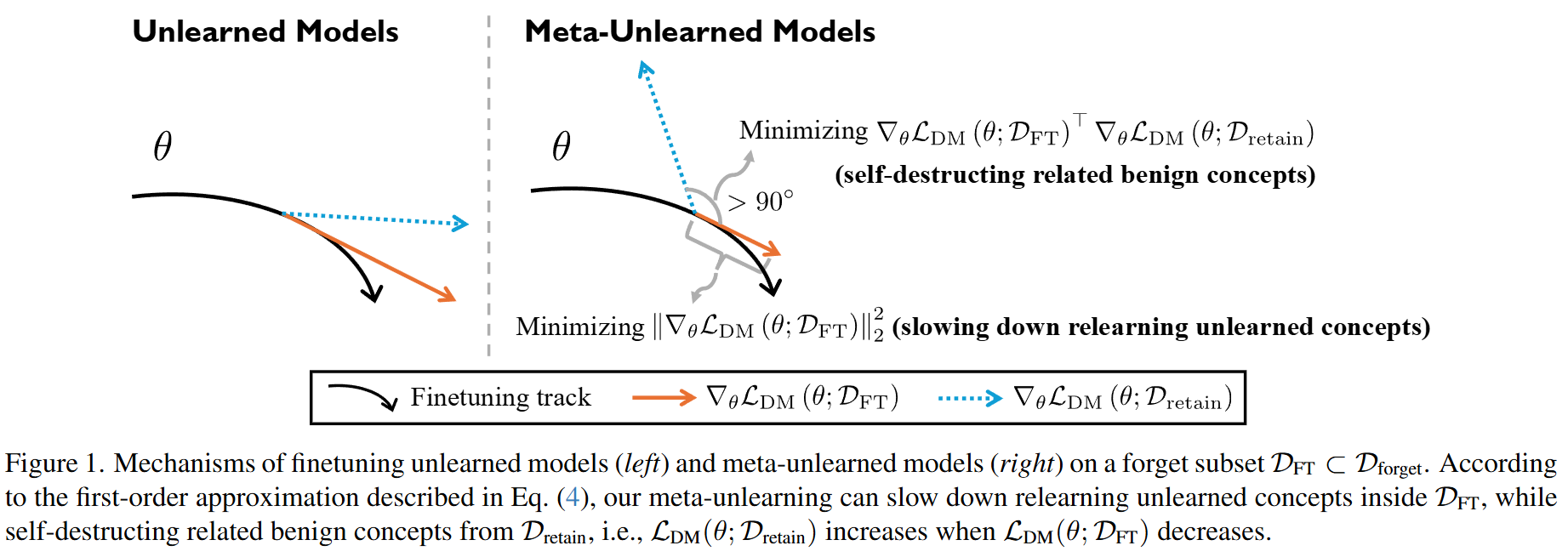
SuMa (Subspace Mapping)
SuMa: A Subspace Mapping Approach for Robust and Effective Concept Erasure in Text-to-Image Diffusion Models
- poster
- video
文本到图像扩散模型的快速发展引发了人们对其可能被滥用于生成有害或未经授权内容的担忧。为了解决这些问题,人们提出了几种概念擦除方法。
然而,大多数方法都无法实现 完整性(即完全删除目标概念的能力) 和 有效性(即保持图像质量) 。虽然近期有少数技术成功实现了针对 NSFW 概念的上述目标,但没有一种技术能够处理诸如受版权保护的人物或名人等狭义概念。
消除这些狭义概念对于解决版权和法律问题至关重要。然而,由于这些概念与非目标相邻概念的距离很近,因此从扩散模型中删除它们具有挑战性,需要更精细的操作。在本文中,我们介绍了子空间映射(SuMa),这是一种新颖的方法,专门用于实现 擦除这些狭义概念的完整性和有效性。
SuMa 首先得出一个代表要消除的概念的目标子空间,然后通过将其映射到一个参考子空间,使两者之间的距离最小化,从而对其进行中和。这种映射可确保目标概念被完全消除,同时保持图像质量。
我们用 SuMa 在四项任务中进行了广泛的实验:子类消除、名人消除、艺术风格消除 和 实例消除,并将实验结果与当前最先进的方法进行了比较。我们的方法不仅在图像质量方面优于那些注重有效性的方法,而且还取得了与注重完整性的方法相当的结果。
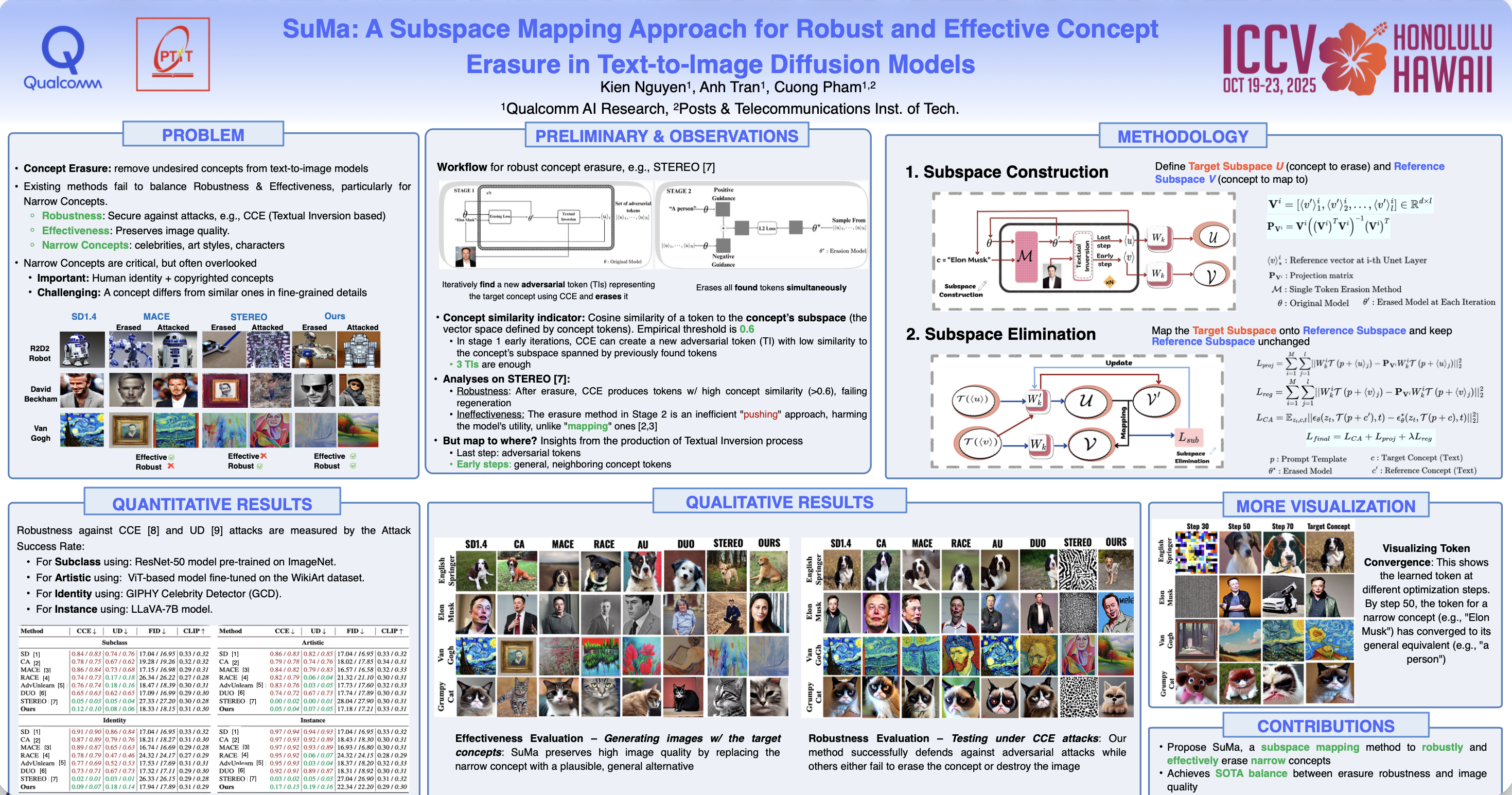
Meta-Unlearning
Meta-Unlearning on Diffusion Models: Preventing Relearning Unlearned Concepts
- poster
随着扩散模型 (DMs) 的快速发展,人们正在做出巨大努力来从预训练的 DMs 中清除有害或受版权保护的概念,以防止潜在的模型滥用。然而,据观察,即使 DMs 在发布前已正确清除,恶意的微调也会破坏这一过程,导致 DM重新学习 Unlearn的概念。
发生这种情况的部分原因是 DM 中保留的某些良性概念(例如“皮肤”)与 Unlearn的概念(例如“裸体”)相关,从而有助于通过微调进行重新学习。
为了解决这个问题,我们提出 meta-unlearning on DMs。直观地说,meta-unlearned DMs 在按原样使用时应该表现得像 unlearned DMs; 此外,如果 meta-unlearned DMs **对未学习的概念进行恶意微调时,其中保留的相关良性概念则将触发自毁(self-destruct)**,从而阻碍对 unlearned concepts 的重新学习。
我们的 meta-unlearning 框架与大多数现有的 Unlearn 方法兼容,只需添加一个易于实现的元目标(meta objective)即可。
我们通过对稳定扩散模型(SD-v1-4 和 SDXL)中的元反学习概念进行实证实验来验证我们的方法,并得到了大量消融研究的支持。
EraseBench
Erasing More Than Intended? How Concept Erasure Degrades the Generation of Non-Target Concepts
- poster
概念擦除技术因其从文本转图像模型中移除不想要概念的潜力而备受关注。虽然这些方法在受控环境中通常表现出良好的效果,但它们在实际应用中的稳健性和部署适用性仍不确定。
在本研究中,我们 (1) 发现了 评估 净化模型 的关键缺陷 ,尤其是在评估其在不同概念维度上的表现方面; (2) 系统地分析了 擦除后文本转图像模型的失效模式 。我们重点研究了概念移除对不同层次互联关系(包括视觉相似、二项式和语义相关概念)中的非目标概念造成的意外后果。
为了更全面地评估概念擦除,我们引入了 EraseBench,这是 一个多维框架,旨在严格评估擦除后的文本转图像模型 。它包含 100 多个不同的概念、精心策划的种子提示以确保可重复的图像生成,以及用于基于模型评估的专用评估提示。我们的框架 与一套强大的评估指标相结合 ,对 概念擦除的有效性及其对模型行为的长期影响 进行了全面而深入的分析。
我们的研究结果揭示了 概念纠缠现象,其中擦除导致非目标概念的意外抑制,导致溢出退化,表现为扭曲和生成质量下降。

Holistic Unlearning Benchmark
Holistic Unlearning Benchmark: A Multi-Faceted Evaluation for Text-to-Image Diffusion Model Unlearning
- poster
- webpage
随着文本到图像的传播模型获得广泛的商业应用,人们越来越担心不道德或有害的使用,包括未经授权生成受版权保护的内容或敏感内容。Concept unlearning 已成为应对这些挑战的一种有前途的解决方案,它从预训练模型中去除不需要的和有害的信息。
然而, 之前的评估主要关注是否在保留图像质量的同时删除了目标概念,而忽略了更广泛的影响,例如意想不到的副作用。
在本文中,我们提出了 Holistic Unlearning Benchmark (HUB) ,这是一个全面的框架,用于评估Unlearn方法的 6个关键维度:faithfulness, alignment, pinpoint-ness, multilingual robustness, attack robustness
我们的基准涵盖 33 个目标概念,每个概念包含 16,000 个提示 ,涵盖 4个类别:Celebrity, Style, Intellectual Property, and NSFW
我们的调查显示,没有一种方法在所有评估标准上都表现出色。通过发布我们的评估代码和数据集,我们希望激发该领域的进一步研究,从而产生更可靠、更有效的Unlearn方法。

Watermark
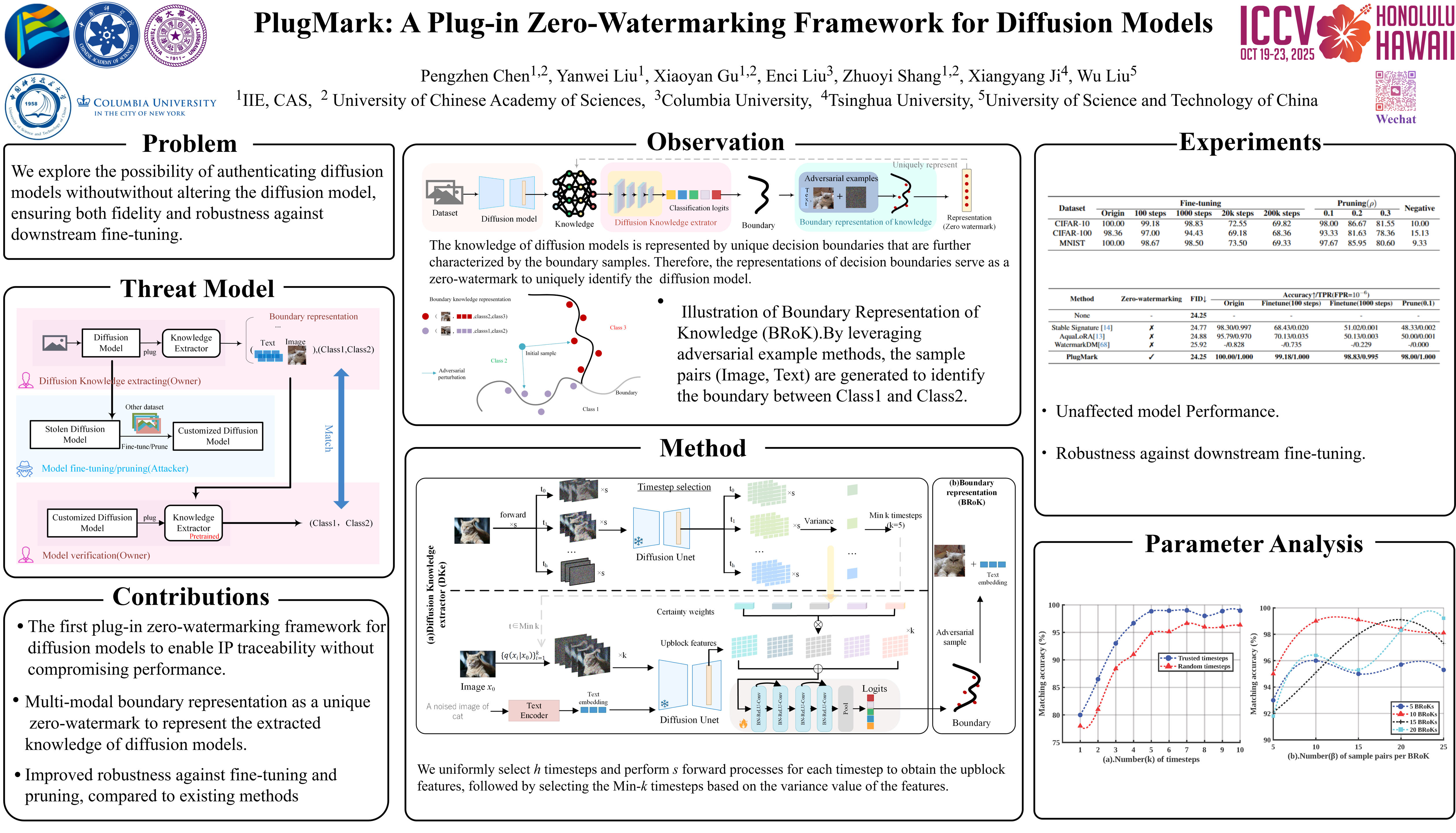
PlugMark
PlugMark: A Plug-in Zero-Watermarking Framework for Diffusion Models
- 暂无公开pdf
- poster
- video
扩散模型极大地推动了图像合成领域的发展,其知识产权 (IP) 的保护也成为至关重要的问题。
现有的 IP 保护方法主要集中在 通过改变扩散过程的结构来将水印嵌入到生成的图像中。然而,这些方法不可避免地会 损害生成图像的质量,并且特别容易受到微调攻击,尤其是对于稳定扩散 (SD) 等开源模型。
本文提出了 PlugMark,一个用于扩散模型的新型插件式零水印框架 。PlugMark 的核心思想基于 两个观察结果:分类器可以通过其决策边界唯一地表征,扩散模型可以通过从训练数据中获得的知识唯一地表示。 在此基础上,我们引入了一个扩散知识提取器,它可以插入到扩散模型中以提取其知识并输出分类结果。 随后,PlugMark 基于该分类结果生成边界表示,作为零失真水印,唯一地表示决策边界,进而表示扩散模型的知识。由于只有提取器需要训练,因此原始扩散模型的性能不受影响。
大量实验结果表明,PlugMark 可以从原始模型及其后处理版本中稳健地提取高置信度零水印,同时有效地将它们与非后处理的扩散模型区分开来。
Copyright
CopyrightShield
CopyrightShield: Enhancing Diffusion Model Security Against Copyright Infringement Attacks
- poster
扩散模型因其在图像合成等领域卓越的数据生成能力而备受关注。然而,近期研究表明,扩散模型易受版权侵权攻击。 攻击者会将经过策略性修改的非侵权图像注入训练集,诱导模型在特定“毒害”字幕的提示下生成侵权内容。
针对此问题,我们首先提出了一个防御框架—— CopyrightShield ,以防御上述攻击。具体而言,我们 分析了扩散模型的记忆机制,发现攻击利用模型对特定空间位置和提示的过拟合,导致其在后门触发下生成毒害样本。
基于此,我们提出了 一种基于空间掩蔽和数据归因的毒害样本检测方法,以量化毒害风险并准确识别隐藏的后门样本。 为了进一步降低对毒害特征的记忆,我们引入了 一种自适应优化策略,将动态惩罚项集成到训练损失中,在保持生成性能的同时降低对侵权特征的依赖。
实验结果表明,CopyrightShield在两种攻击场景下显著提升了中毒样本的检测性能,平均F1-scores达到0.665,首次攻击时间(FAE)延迟115.2%,版权侵权率(CIR)降低56.7%。相比于扩散模型中的SoTA后门防御,防御效果提升约25%,展现了其在提升扩散模型安全性方面的优越性和实用性。

Other
Unlearn
趋势:解决 Machine Unlearn 的两个目标的优化冲突问题
- 遗忘特定概念/数据
- 保持总体性能(减小对其他概念的干扰)
MUNBa (Machine Unlearning via Nash Bargaining)
MUNBa: Machine Unlearning via Nash Bargaining
- TL;DR: 用纳什谈判解的方法,优化MU的两个目标
- poster
机器遗忘(MU)旨在有选择性地清除模型中的有害行为,同时保留模型的整体效用。作为一个多任务学习问题,MU 需要在 遗忘特定概念/数据 和 保持总体性能 这两个目标之间取得平衡。
为了解决梯度冲突和优势问题,我们 将 MU 重新表述为双人合作博弈 ,即遗忘博弈者和保留博弈者通过梯度建议来最大化他们的整体收益并平衡他们的贡献。
我们对 MU 的表述 保证了均衡解,任何偏离最终状态的情况都会导致双方总体目标的降低,从而确保每个目标的最优性。
我们用 ResNet、视觉语言模型 CLIP 和文本到图像扩散模型进行了大量实验,结果表明我们的方法优于最先进的 MU 算法,在遗忘和保持之间实现了更好的权衡。

Water4MU
Invisible Watermarks, Visible Gains: Steering Machine Unlearning with Bi-Level Watermarking Design
- poster
随着人们对被遗忘权的需求日益增长,Machine Unlearn (MU) 已成为增强信任和法规遵从性的重要工具,因为它能够从机器学习 (ML) 模型中消除敏感数据的影响。然而,大多数 MU 算法主要依靠 in-training methods 来调整模型权重,而对 data-level adjustments 的探索有限。
为了弥补这一差距,我们提出了一种新颖的方法,利用 digital watermarking 策略性地修改数据内容,来促进 MU。 通过集成 watermarking,我们建立了 一种受控的Unlearn机制,该机制能够精确删除指定数据,同时保持不相关任务的模型效用。
我们首先研究了带水印的数据对 MU 的影响,发现 MU 可以有效地推广到带水印的数据。在此基础上,我们引入了 一个有利于反学习的水印框架,称为 Water4MU,以提高反学习的有效性。 Water4MU 的核心是 一个双层优化 (bi-level optimization, BLO) 框架:在上层,水印网络经过优化以最小化遗忘难度;而在下层,模型本身则独立于水印进行训练。
实验结果表明,Water4MU 在图像分类和图像生成任务中均能有效进行 MU。值得注意的是,它在具有挑战性的 MU 场景(即所谓的“挑战性遗忘”)中的表现优于现有方法。
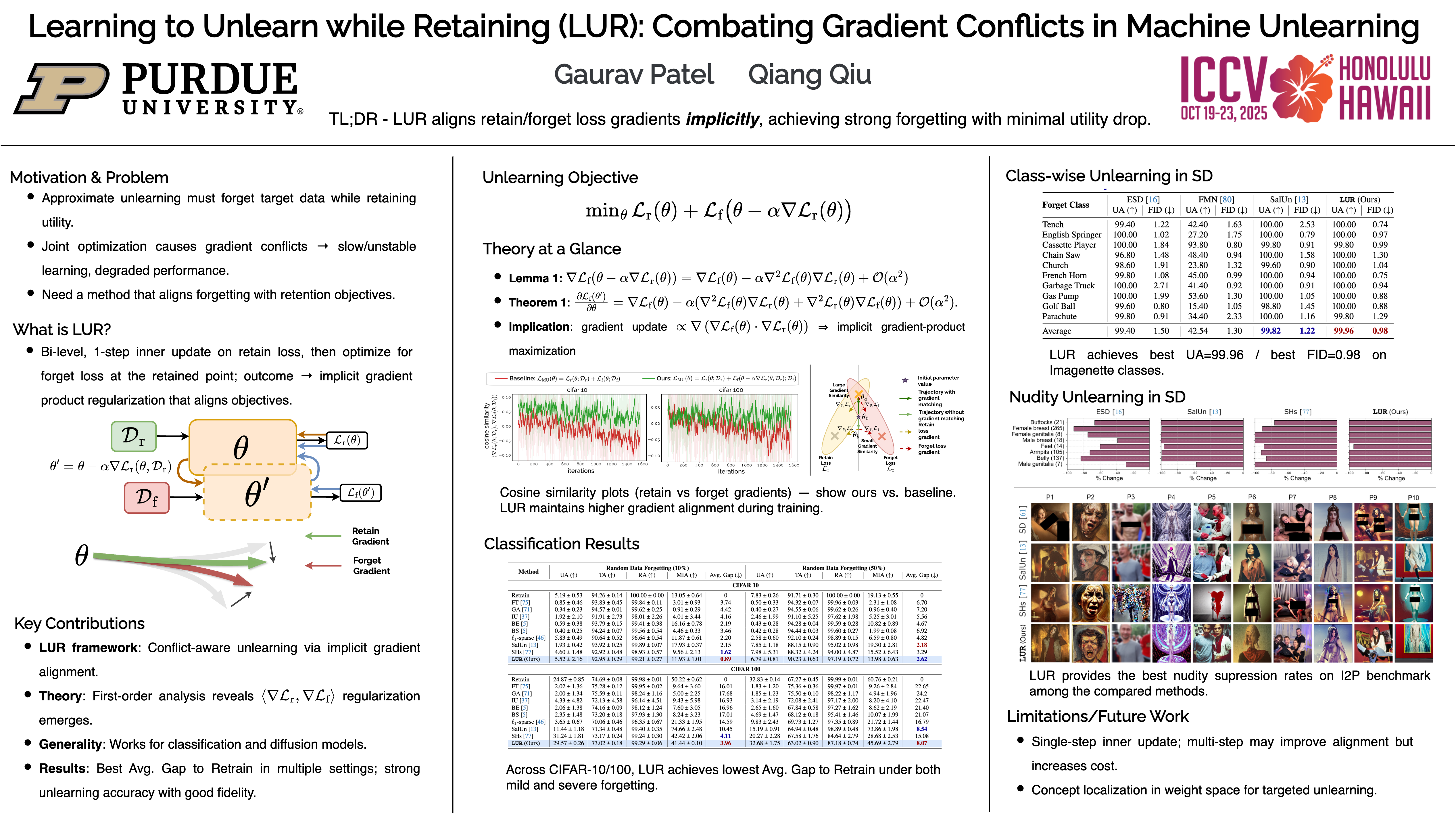
LUR (Learning to Unlearn while Retaining)
Learning to Unlearn while Retaining: Combating Gradient Conflicts in Machine Unlearning
- poster
- video
机器学习的 Unlearning 最近备受关注,其目标是选择性地移除与特定数据相关的知识,同时保留模型在剩余数据上的性能。
这一过程中的一个根本挑战是 如何平衡有效的遗忘和知识保留 ,因为对这些相互竞争的目标进行简单的优化可能会导致梯度冲突,从而阻碍收敛并降低整体性能。
为了解决这个问题,我们提出了 Learning to Unlearn while Retaining ,旨在 缓解遗忘和保留目标之间的梯度冲突。
我们的方法通过一种在所提框架内自然形成的 隐式梯度正则化机制,策略性地避免了冲突。 这可以防止遗忘和保留之间出现梯度冲突,从而实现有效的遗忘,同时保留模型的效用。
我们在判别任务和生成任务中验证了我们的方法,证明了它在不影响剩余数据性能的情况下实现Unlearn的有效性。我们的结果突出了避免此类梯度冲突的优势,优于未能考虑这些相互作用的现有方法。
FG-OrIU
FG-OrIU: Towards Better Forgetting via Feature-Gradient Orthogonality for Incremental Unlearning
- 暂无公开pdf
- poster
Incremental unlearning (IU) 对于预训练模型满足顺序数据删除要求至关重要,但现有方法主要抑制参数或混淆知识,而没有在特征和梯度层面进行明确的约束,导致 superficial forgetting(表面遗忘),残留信息仍然可恢复。
这种不完全遗忘存在安全漏洞风险,并破坏了保留平衡,尤其是在 IU 场景中。
我们提出了 FG-OrIU(Feature-Gradient Orthogonality for Incremental Unlearning) ,这是第一个 统一特征和梯度层面正交约束以实现深度遗忘的框架,其中遗忘效应是不可逆的。
FG-OrIU 通过奇异值分解 (SVD) 对特征空间进行分解,将遗忘特征和剩余类别特征分离到不同的子空间中。
然后,它强制实施双重约束:对遗忘类和剩余类进行 特征正交投影 ,而 梯度正交投影 则防止在更新过程中重新引入遗忘知识并干扰剩余类。
此外,动态子空间自适应 会合并新遗忘的子空间并收缩剩余子空间,从而确保在连续的反学习任务中,移除和保留之间保持稳定的平衡。
大量实验证明了我们方法的有效性。
- Title: Paper Collection of Safe Diffusion
- Author: LeoJeshua
- Created at : 2024-12-21 15:49:09
- Updated at : 2025-10-14 20:00:32
- Link: https://leojeshua.github.io/DMs/Paper-Collection-of-Safe-Diffusion/
- License: This work is licensed under CC BY-NC-SA 4.0.