Paper Collection of Safe Diffusion at CVPR 2025
CVPR 2025
Submission Deadline: 2024.11.15
Official Site:
WeChat Article:
Attack
Adversarial Attack
FastProtect
Nearly Zero-Cost Protection Against Mimicry by Personalized Diffusion Models
- TL;DR: 针对DMs的几乎零开销的实时的图像保护方法
- poster
- video
扩散模型的最新进展彻底改变了图像生成,但也带来了滥用的风险,例如复制艺术品或生成深度伪造作品。
现有的图像保护方法虽然有效,但难以在保护效果(protection performance)、不可见性(invisibility)和延迟(inference time)之间取得平衡,从而限制了实际应用。
我们引入 扰动预训练 来降低延迟,并提出了一种 混合扰动方法 ,该方法可以动态地适应输入图像,从而最大限度地减少性能下降。
我们新颖的训练策略 计算跨多个 VAE 特征空间的保护损失 ,而推理阶段的 自适应定向保护则增强了鲁棒性和隐形性。
实验表明,该方法具有相当的protection performance,并且invisibility得到提升,inference time也显著缩短。
I2VGuard
I2VGuard: Safeguarding Images against Misuse in Diffusion-based Image-to-Video Models
- TL;DR: 针对T2V DMs, 在空间和时间两个维度,利用对抗攻击保护图像(降低生成Video的质量)
- poster
图像转视频生成领域的最新进展使得静态图像的动画化成为可能,并提供了像素级的可控性。虽然这些模型在将单幅图像转换为生动动态视频方面拥有巨大潜力,但它们也存在滥用风险,可能影响隐私、安全和版权保护。
本文提出了一种新颖的方法,对图像施加难以察觉的扰动来降低生成视频的质量,从而保护图像免遭白盒图像转视频扩散模型的滥用。 具体而言,我们将该方法作为一种对抗性攻击,结合了空间、时间和扩散攻击模块。空间攻击 将图像特征从其原始分布转移到质量较低的目标分布,从而降低了视觉保真度。时间攻击 通过干扰引导运动生成的时间注意力图来破坏连贯运动。
为了增强我们的方法在不同模型中的鲁棒性,我们进一步提出了 一个利用对比损失的扩散攻击模块 。我们的方法可以轻松地与主流的基于扩散的 I2V 模型集成。
在 SVD、CogVideoX 和 ControlNeXt 上进行的大量实验表明,我们的方法会显著降低生成质量(包括视觉清晰度和运动一致性),同时仅会在图像中引入极少的伪影。据我们所知,我们是首个出于安全目的探索T2V对抗攻击的团队。

Data Poisoning Attack
Silent Branding Attack
Silent Branding Attack: Trigger-free Data Poisoning Attack on Text-to-Image Diffusion Models
- TL;DR: 一种数据投毒方法,让模型生成的图片包含 specific brand logo,并且不需要 text trigger。
- poster
- webpage
文本到图像的扩散模型在从文本提示生成高质量内容方面取得了显著成功。然而,由于它们依赖于公开数据,并且为了进行微调而共享数据,这些模型尤其容易受到数据中毒攻击。
本文提出了一种名为 “静默品牌攻击”(Silent Branding Attack) 的新型数据中毒方法,它能够 操纵T2I DMs,生成包含特定品牌标识或符号的图像,而无需任何文本触发。
我们发现,当某些视觉模式在训练数据中重复出现时,即使没有提示,模型也能学会在输出中自然地重现这些模式。利用这一特性,我们开发了一种 自动化数据中毒算法,该算法可以不显眼地将标识注入原始图像中,确保它们自然融合且不被检测到。 在此中毒数据集上训练的模型能够生成包含标识的图像,而不会降低图像质量或文本对齐。
我们在大规模高质量图像数据集和风格个性化数据集上,通过两种实际设置实验验证了我们的静默品牌攻击,即使没有特定的文本触发,也能获得很高的成功率。人工评估和包括徽标检测在内的定量指标表明,我们的方法可以隐秘地嵌入徽标。

MIA
CDI (Copyrighted Data Identification)
CDI: Copyrighted Data Identification in Diffusion Models
- poster
- video
扩散模型 (DMs) 的训练得益于海量且多样化的数据集。由于这些数据通常是未经数据所有者许可从互联网上抓取的,这引发了人们对版权和知识产权保护的担忧。
虽然对于由 DMs 在推理时完美重建的训练样本,数据的(非法)使用很容易被检测到,但当可疑 DMs 的输出不是近似副本时,数据所有者很难验证他们的数据是否用于训练。从概念上讲,成员推断攻击 (MIA) 可以检测给定数据点是否在训练期间被使用,它是解决这一挑战的合适工具。然而,我们证明现有的 MIA 不足以在大型、最先进的 DMs 中可靠地确定单个图像的成员资格。
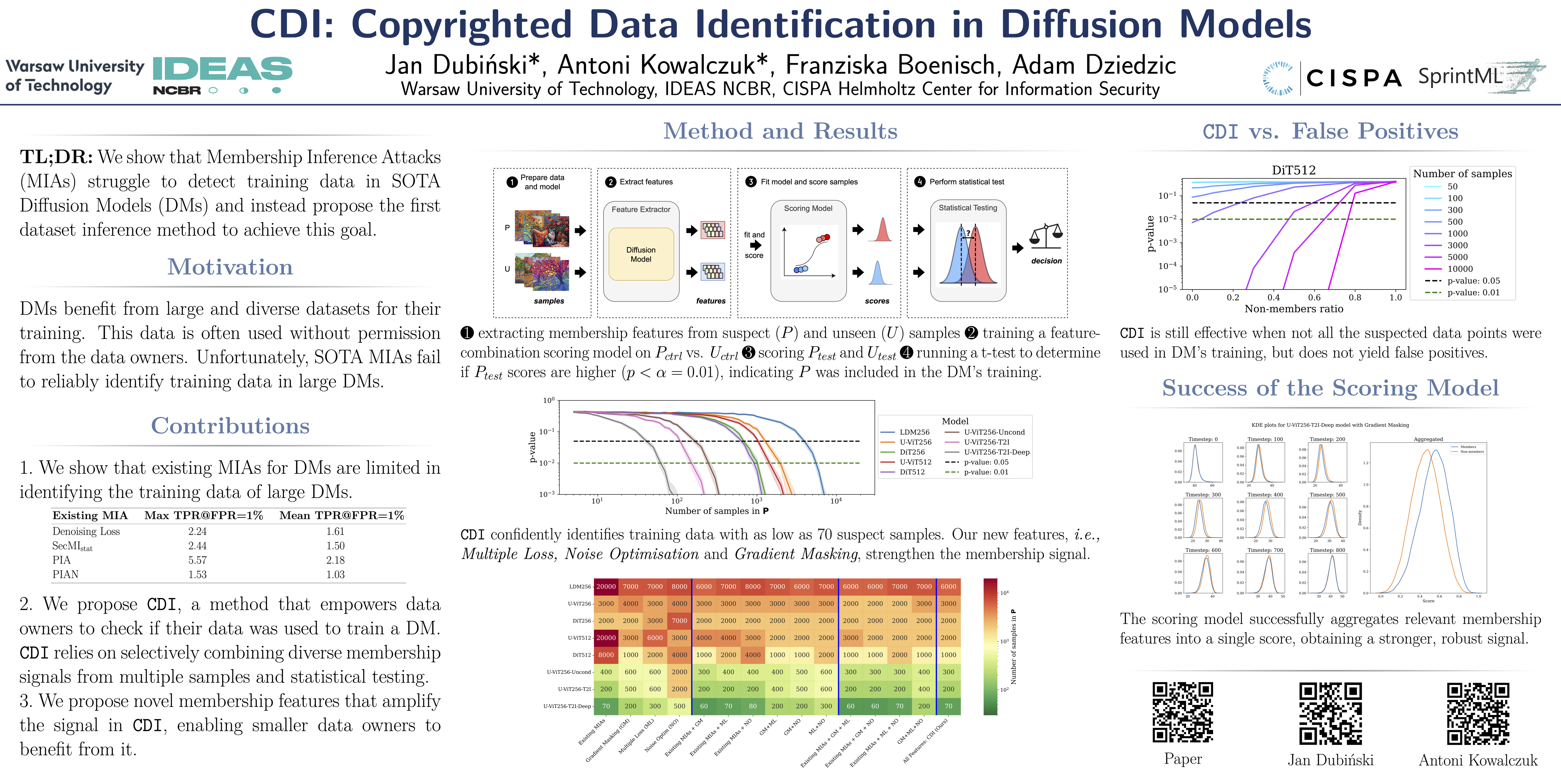
为了克服这一限制,我们提出了 CDI,一个供数据所有者识别其数据集是否用于训练给定 DMs 的框架。
CDI 依赖于 数据集推断技术,即 CDI 并非使用来自单个数据点的成员资格信号,而是利用了这样一个事实:大多数数据所有者(例如图片库提供商、视觉媒体公司,甚至个人艺术家)都拥有包含多个公开data points的数据集,这些data points可能全部用于训练特定的 DMs 。
通过选择性地聚合来自现有 MIAs 的信号,并使用新的人工方法提取这些数据集的特征,将其输入评分模型,并进行严格的统计测试,CDI 允许数据所有者 仅使用 70 个 data points,以超过 99% 的置信度 识别其数据是否被用于训练特定的数据挖掘模型 (DM)。因此,CDI 是数据所有者对其版权数据被非法使用进行索赔的有力工具。
Bias
IBI (Implicit Bias Injection Attacks)
Implicit Bias Injection Attacks against Text-to-Image Diffusion Models
- poster
文本转图像扩散模型 (T2I DMs) 的普及使得人工智能生成的图像在日常生活中日益常见。然而,存在偏见的 T2I 模型可能会生成具有特定倾向的内容,从而可能影响人们的感知。故意利用这些偏见可能会向公众传递误导性信息。
目前对偏见的研究主要针对具有可识别视觉模式的显性偏见,例如肤色和性别。
本文介绍了 一种新型的隐性偏见,它缺乏显性视觉特征,但可以在不同的语义语境中以多种方式表现出来。 这种微妙且多变的特性使得这种偏见难以检测、易于传播,并且能够适应各种场景。
我们进一步提出了一个针对 T2I 扩散模型的 隐性偏见注入攻击框架 (IBI-Attacks),该框架通过在提示嵌入空间中预先计算一个通用的偏见方向,并根据不同的输入自适应地调整它。 我们的攻击模块可以无缝集成到预训练的扩散模型中,即插即用,无需直接操作用户输入或重新训练模型。
大量实验验证了我们的方案在保留原始语义的同时,通过微妙而多样的修改引入偏差的有效性。我们的攻击在各种场景中的强大隐蔽性和可转移性进一步强调了我们的方法的重要性。

Watermarks
Black-Box Forgery Attacks on Semantic Watermarks
Black-Box Forgery Attacks on Semantic Watermarks for Diffusion Models
- TL;DR: 黑盒条件下 伪造 语义水印
- poster
- code
将水印集成到潜在扩散模型 (LDMs) 的生成过程中,可以简化生成内容的检测和归因。
语义水印,例如树形年轮(Tree-Rings)和高斯阴影(Gaussian Shading),代表了一类新颖的水印技术,易于实现,并且对各种扰动具有高度的鲁棒性。
然而,我们的工作揭示了 语义水印的一个根本安全漏洞 。我们表明,攻击者可以利用不相关的模型,即使使用不同的潜在空间和架构(UNet 与 DiT),也能执行强大且逼真的伪造攻击。
具体来说,我们设计了 两种水印伪造攻击 。第一种攻击通过 在不相关的 LDMs 中操纵任意图像的潜在表示,使其更接近带水印图像的潜在表示(Imprint-F) ,从而将目标水印嵌入真实图像中。我们还表明,该技术可用于去除水印(Imprint-R)。第二种攻击通过 **反转带水印图像并使用任意提示重新生成它,来生成带有目标水印的新图像(Reprompt)**。
两种攻击都只需要一张带有目标水印的参考图像。总而言之,我们的研究结果质疑了语义水印的适用性,因为攻击者在现实条件下很容易伪造或移除这些水印。

Defence
Guidence
DAG (Detect-and-Guide)
Detect-and-Guide: Self-regulation of Diffusion Models for Safe Text-to-Image Generation
- poster
文本到图像的扩散模型在合成任务中取得了最先进的结果; 然而,人们越来越担心它们可能被滥用来创建有害内容。为了减轻这些风险,人们开发了事后模型干预技术,例如概念遗忘和安全指导。
然而,微调模型权重或调整扩散模型的隐藏状态以一种不可解释的方式进行,使得不清楚中间变量的哪一部分负责不安全的生成。当从复杂的多概念提示中删除有害概念时,这些干预措施会严重影响采样轨迹,从而阻碍了它们在现实世界中的实际使用。尽管它们在单一概念提示上有效,但当前的方法仍然面临着挑战,因为它们很难在不破坏良性概念语义的情况下精确删除有害概念。
在这项工作中,我们提出了 检测和引导(DAG) 安全生成框架, 利用扩散模型的内部知识在采样过程中进行自我诊断和细粒度的自我调节。
DAG首先使用优化标记的细化交叉注意力图从噪声潜伏中检测有害概念,然后应用具有自适应强度和编辑区域的安全引导来否定不安全生成。优化只需要小型注释数据集,可以提供具有普遍性和概念特异性的精确检测图。 此外,DAG不需要对扩散模型进行微调,因此不会对其生成多样性造成损失。
擦除色情内容的实验表明,DAG 实现了最先进的安全生成性能,在多概念现实世界提示上平衡了危害缓解和文本跟踪性能。
Concept Replacer
Concept Replacer: Replacing Sensitive Concepts in Diffusion Models via Precision Localization
- poster
随着大规模扩散模型的不断发展,它们在生成高质量图像方面表现出色,但同时也常常会生成一些不受欢迎的内容,例如色情或暴力内容。
现有的概念移除方法通常会引导图像生成过程,但可能会无意中修改不相关的区域,从而导致与原始模型不一致。
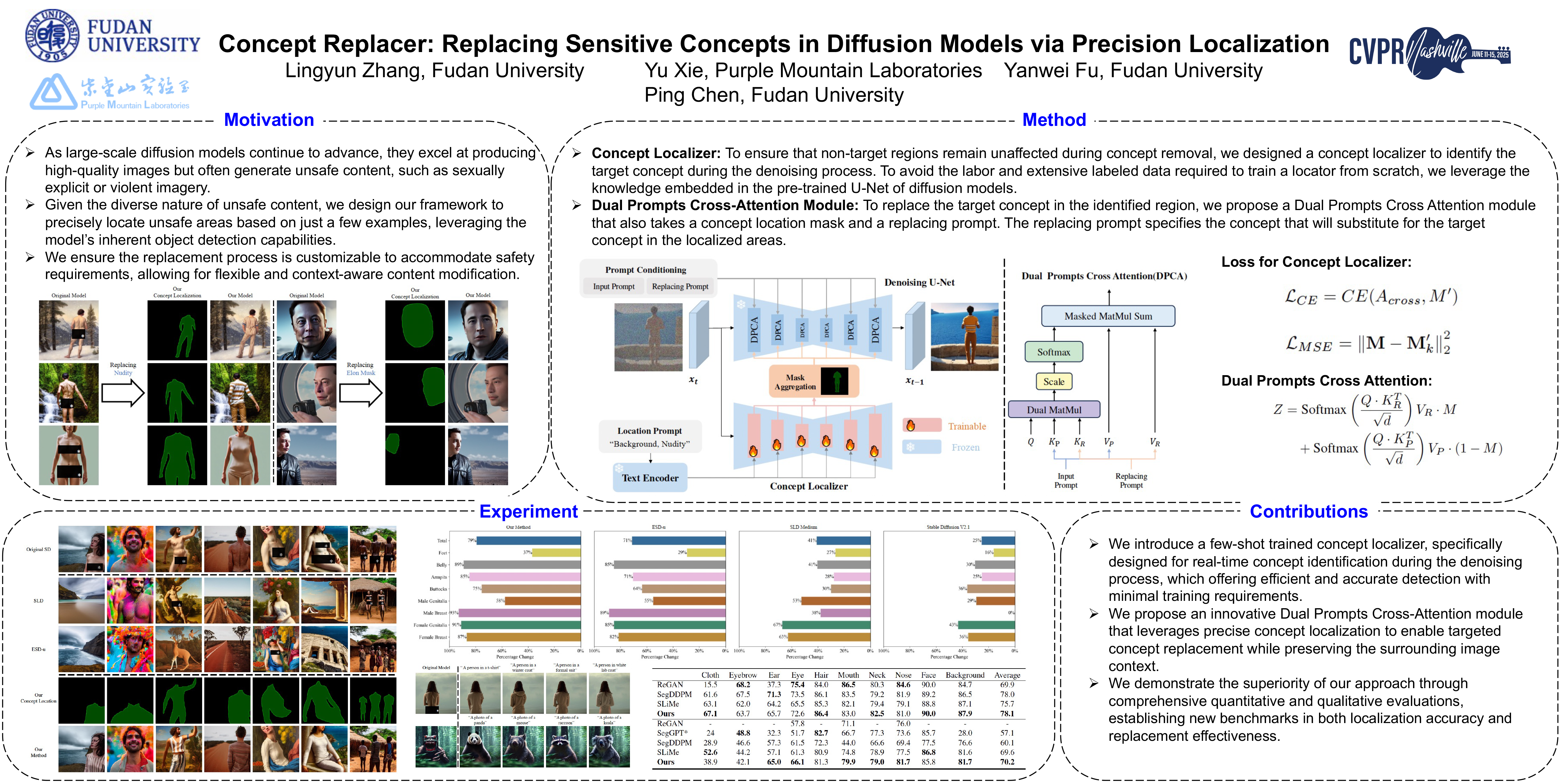
我们提出了一种新的扩散模型中的目标概念替换方法,能够在不影响非目标区域的情况下移除特定概念。
我们的方法引入了 一个专用的概念定位器,用于在去噪过程中精确识别目标概念 ,该定位器采用少样本学习进行训练,只需要极少的标记数据。在已识别的区域内,我们引入了一个无需训练的 双提示交叉注意力 (DPCA) 模块 来替换目标概念,确保对周围内容的干扰最小。
我们对我们的方法进行了 概念定位精度 和 替换效率 的评估。实验结果表明,我们的方法在目标概念定位方面取得了卓越的精度,并在对非目标区域影响最小的情况下进行了连贯的概念替换,优于现有方法。
Unlern
EraseDiff
Erasing Undesirable Influence in Diffusion Models
- poster
- note: 考虑到“擦除
”和“保留 ”两个目标,对vanilla MOO(多目标优化)改进,变成contrained optimization problem(有natutral first-order solution)。解决了优化梯度冲突问题。 扩散模型在生成高质量图像方面非常有效,但也存在风险,例如无意中生成 NSFW(不适合工作)内容。
尽管已经提出了各种技术来减轻扩散模型中的不良影响,同时保持整体性能,但在这些目标之间取得平衡仍然具有挑战性。
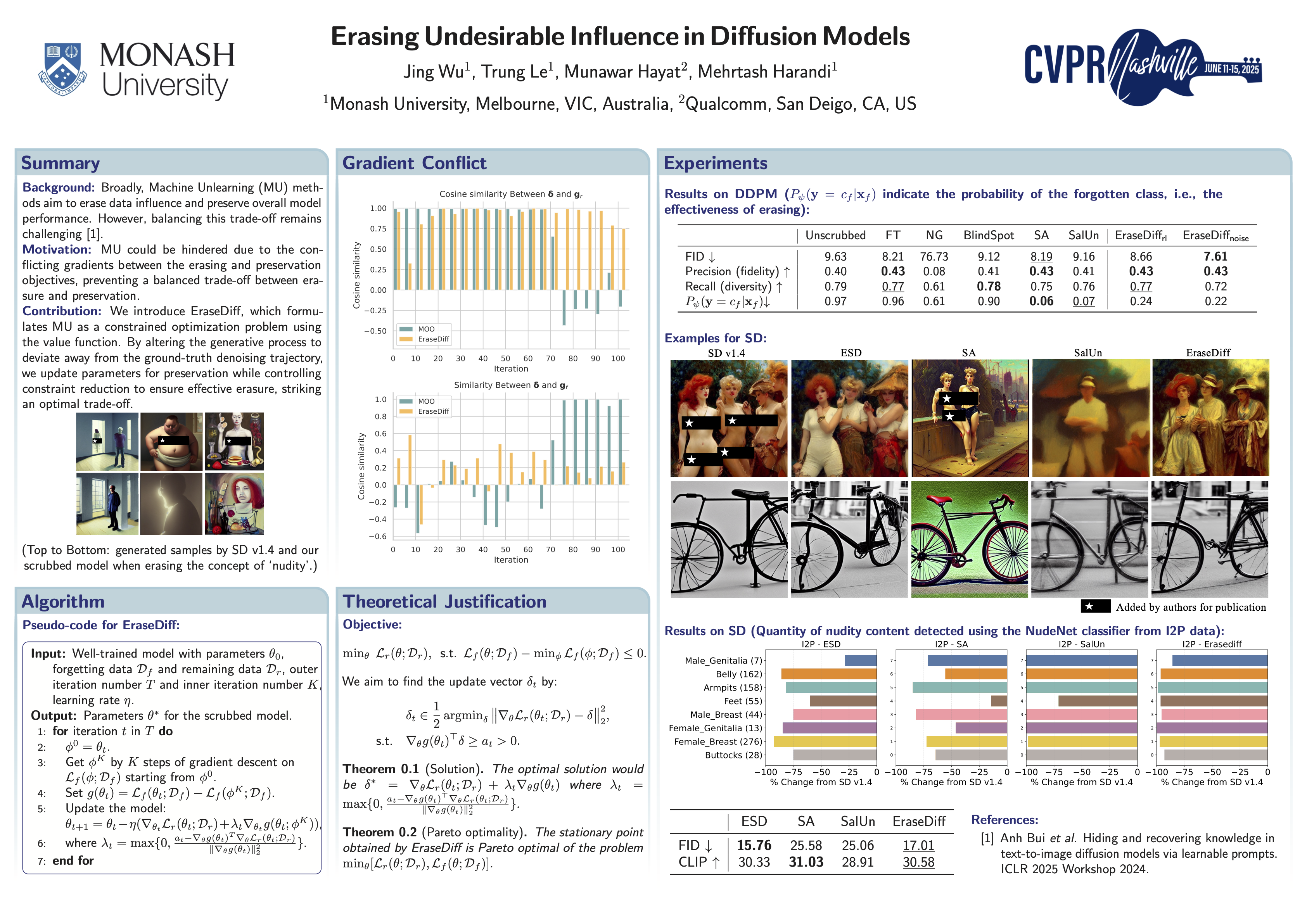
在这项工作中,我们引入了 EraseDiff,这是一种旨在 保留扩散模型对保留数据的效用,同时删除与要遗忘的数据相关的不需要的信息的算法。
我们的方法使用值函数将此任务表述为约束优化问题,从而产生用于解决优化问题的自然一阶算法。通过改变生成过程以偏离地面实况去噪轨迹,我们更新保存参数,同时控制约束减少以确保有效擦除,从而达到最佳权衡。
大量的实验和与最先进算法的彻底比较表明,EraseDiff 有效地保持了模型的效用、功效和效率。
Localized Concept Erasure (GLoCE)
Localized Concept Erasure for Text-to-Image Diffusion Models Using Training-Free Gated Low-Rank Adaptation
- poster
基于微调的概念擦除已显示出良好的效果,它通过移除目标概念并保留剩余概念,防止文本到图像的扩散模型生成有害内容。为了在概念擦除后保持扩散模型的生成能力,需要仅移除图像中局部出现的目标概念所在的图像区域,而保留其他区域。
然而,现有技术通常会为了擦除出现在特定区域的局部目标概念而牺牲其他图像区域的保真度,从而降低图像生成的整体性能。
为了解决这些限制,我们首先引入了一个称为 Localized Concept Erasure 的框架,该框架允许仅删除图像中包含目标概念的特定区域,同时保留其他区域。
作为局部概念擦除的解决方案,我们提出了一种 training-free 的方法,称为 Gated Low-rank adaptation for Concept Erasure (GLoCE) ,该方法在扩散模型中注入了一个轻量级模块。GLoCE 由低秩矩阵和一个简单的门组成,仅由几个无需训练的概念生成步骤决定。通过将 GLoCE 直接应用于图像嵌入,并设计仅针对目标概念激活的门控,GLoCE 可以选择性地仅移除目标概念的区域,即使目标概念和剩余概念共存于图像中。
大量实验表明,GLoCE 不仅在擦除局部目标概念后提高了图像与文本提示的保真度,而且在有效性、特异性和稳健性方面也大幅超越现有技术,并且可以扩展到大规模概念擦除。
ACE (Anti-editing Concept Erasure)
ACE: Anti-Editing Concept Erasure in Text-to-Image Models
- poster
- github
文本到图像传播模型的最新进展极大地促进了高质量图像的生成,但也引发了人们对非法创建有害内容(例如受版权保护的图像)的担忧。
现有的概念擦除方法在防止提示中产生被擦除的概念方面取得了优异的效果,但在防止不必要的编辑方面通常表现不佳。
为了解决这个问题,我们提出了 一种 Anti-editing 的 Concept Erasure (ACE) 方法,它不仅在生成过程中擦除目标概念,还在编辑过程中将其过滤掉。
具体而言,我们建议 在条件和非条件噪声预测中注入擦除指导 ,使模型能够有效地防止在编辑和生成过程中产生擦除概念。此外, 在训练过程中引入随机校正指导 ,以解决无关概念的擦除问题。
我们使用代表性编辑方法(例如LEDITS++和MasaCtrl)进行了擦除编辑实验,以擦除 IP 字符,结果表明,我们的 ACE 能够有效地在两种编辑类型中过滤掉目标概念。进一步的实验(删除显性概念和艺术风格)进一步证明了我们的 ACE 比最先进的方法表现更佳。我们的代码将公开发布。

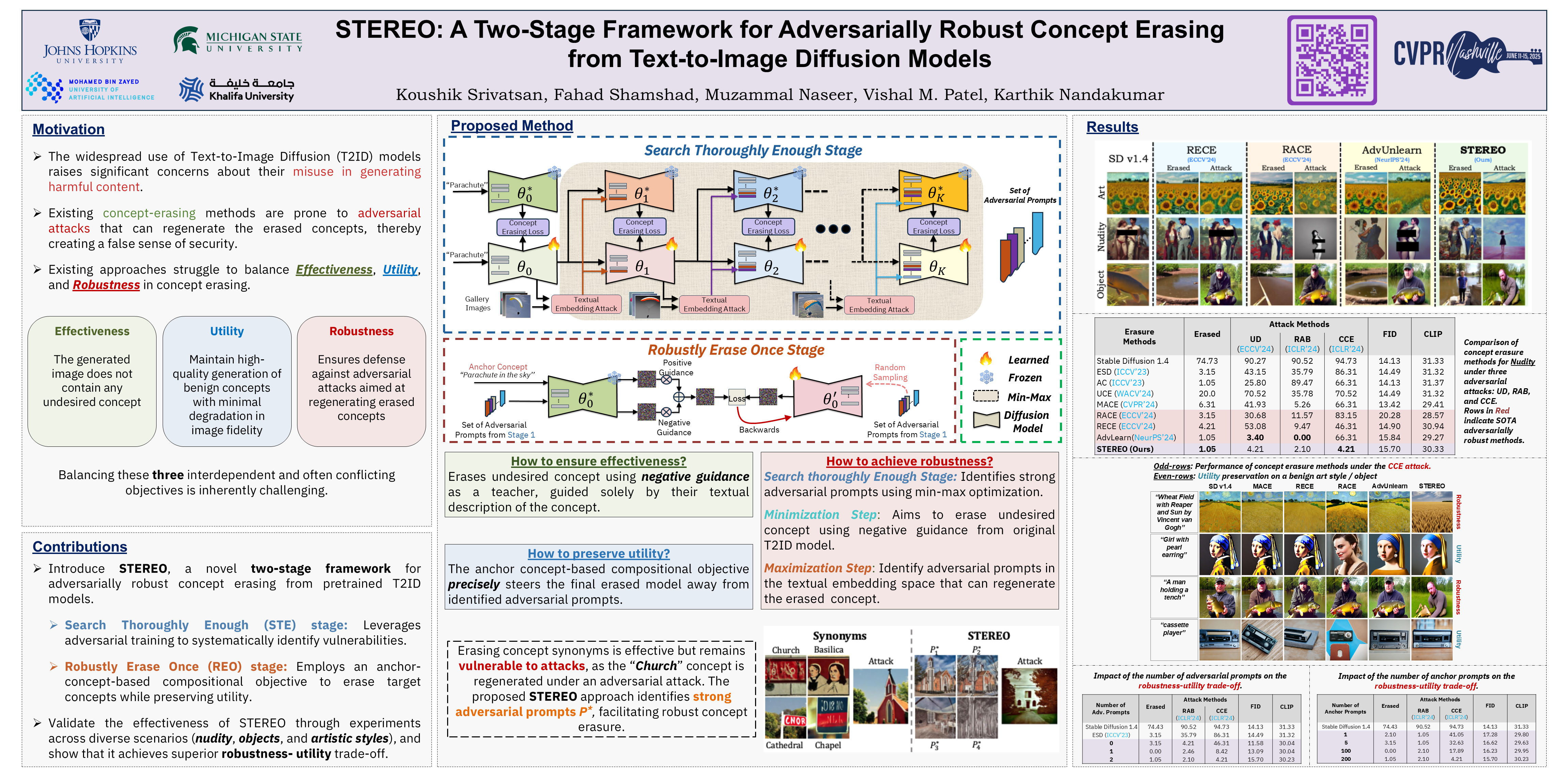
STEREO (Search Thoroughly Enough, Robustly Erase Once)
STEREO: A Two-Stage Framework for Adversarially Robust Concept Erasing from Text-to-Image Diffusion Models Highlight
- poster
大规模文本转图像扩散 (T2ID) 模型的快速普及引发了人们对其可能被滥用生成有害内容的严重担忧。尽管已经提出了许多从 T2ID 模型中擦除不良概念的方法,但它们常常会给人一种虚假的安全感,因为概念擦除模型 (CEM) 很容易被对抗性攻击欺骗,从而生成被擦除的概念。
尽管最近出现了一些 基于对抗性训练的鲁棒概念擦除方法,但它们为了获得鲁棒性,会牺牲实用性(良性概念的生成质量),并且/或者仍然容易受到高级嵌入空间攻击。这些局限性源于鲁棒 CEM 未能彻底搜索嵌入空间中的“盲点(blind spots)”。
为了弥补这一缺陷,我们提出了 STEREO,这是一个新颖的两阶段框架,它将对抗性训练作为鲁棒概念擦除的第一步,而非唯一步骤。
在第一阶段,Search Thoroughly Enough (STE):使用对抗性训练作为漏洞识别机制,以进行足够彻底的搜索;在第二阶段,Robustly Erase Once (REO):引入了一个基于锚点概念的(anchor-concept-based)组合目标,以鲁棒的方式一次性擦除目标概念,同时尽量减少模型效用的下降。
我们将 STEREO 与 7 种最先进的概念擦除方法进行了对比,证明了其在抵御白盒、黑盒和高级嵌入空间攻击方面具有增强的鲁棒性,并且能够在很大程度上保留效用。
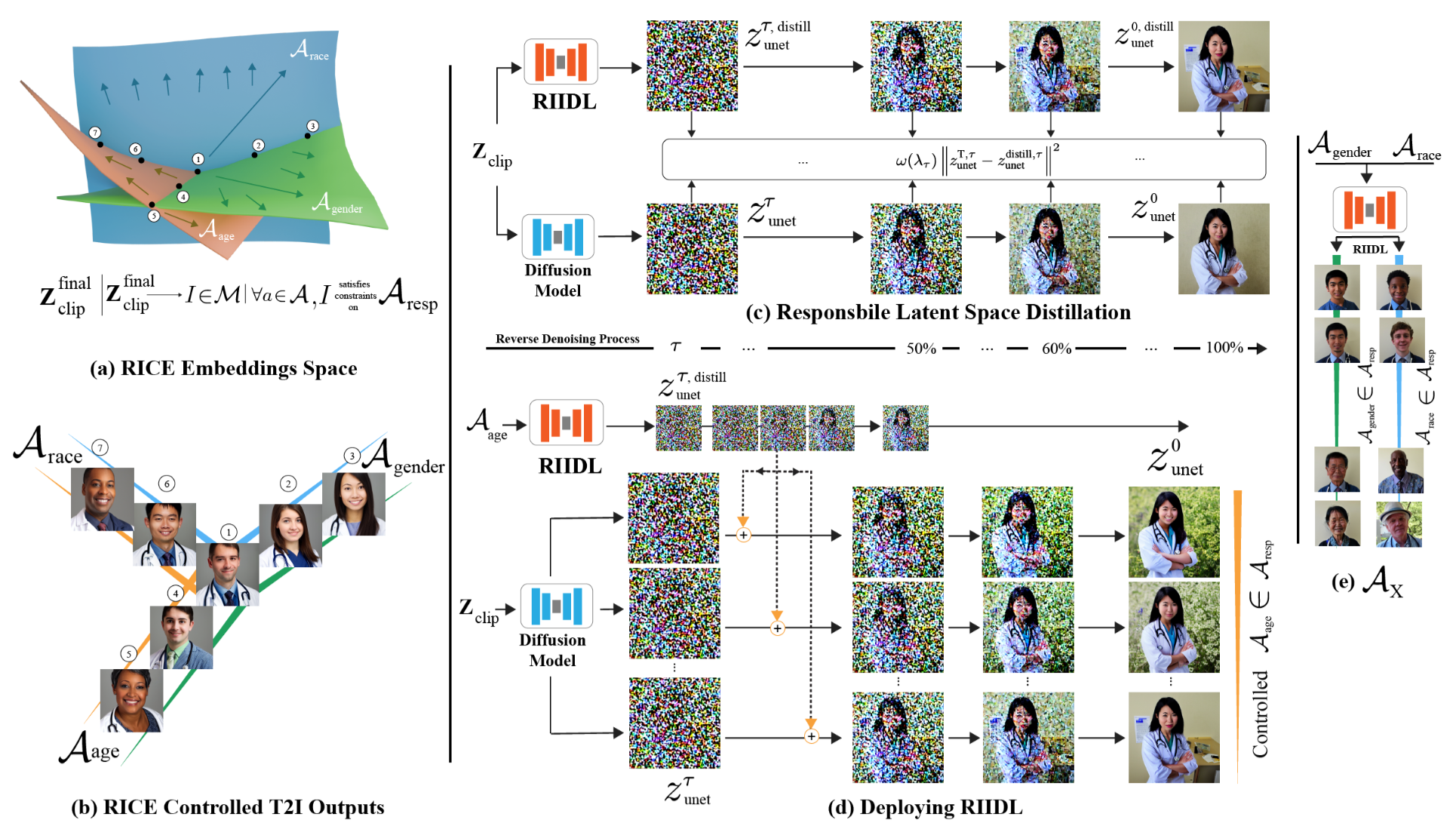
RIIDL (Responsible Interpretable Intermediate Diffusion Latents)
Plug-and-Play Interpretable Responsible Text-to-Image Generation via Dual-Space Multi-facet Concept Control
- poster
- webpage
围绕文本转图像 (T2I) 模型的伦理问题要求对生成内容进行全面控制。现有的针对负责任的 T2I 模型的这些问题的技术旨在使生成的内容公平安全(非暴力/明确)。然而,这些方法仍然局限于单独处理责任概念的各个方面,同时也缺乏可解释性。此外,它们通常需要修改原始模型,这会影响模型性能。
在本文中,我们提出了一种独特的技术,通过同时考虑广泛的概念来实现负责任的 T2I 生成,并且以可扩展的方式实现公平安全的内容生成。关键思想是 使用 外部的即插即用(plug-and-play)机制 蒸馏 target T2I pipeline ,该机制根据 target T2I pipeline 学习 the desired concepts 的 可解释的合成的责任空间(an interpretable composite responsible space)。
我们使用 知识蒸馏(knowledge distillation) 和 概念白化(concept whitening) 来实现这一点。在推理时,学习到的空间用于调节生成内容。典型的 T2I 管道为我们的方法提供了两个插件点,即:文本嵌入空间 和 扩散模型潜在空间。
我们针对这两个方面开发了模块,并通过一系列强大的结果证明了我们方法的有效性。我们的代码和模型将在论文被接受后公开。
AdaVD (Adaptive Vaule Decomposer)
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
- poster
扩散模型成功实现了文本到图像的生成,这迫切需要以精确、及时且低成本的方式从预训练模型中擦除不需要的概念,例如版权、冒犯性和不安全的概念。概念擦除的双重需求要求在生成过程中精确删除目标概念(即erasure efficacy),同时对非目标内容生成的影响最小(即prior preservation)。
现有方法要么计算成本高昂,要么在维持擦除效率和先验保留之间的有效平衡方面面临挑战。
为了改进,我们提出了 一种精确、快速且低成本的概念擦除方法,称为 Adaptive Vaule Decomposer (AdaVD, 自适应的Value分解器),它无需训练。
该方法基于经典的 线性代数正交补运算,在扩散模型UNet中每个交叉注意层的值空间中实现。 设计了一种有效的移位因子,用于自适应地控制擦除强度,在不牺牲擦除效率的情况下增强先验保留。
大量实验结果表明,所提出的 AdaVD 在单概念和多概念擦除方面均有效,与第二佳方法相比,先验保存率提高了 2 到 10 倍,同时,与基于训练和无需训练的现有技术相比,均达到了最佳或接近最佳的擦除效率。AdaVD 支持一系列扩散模型和下游图像生成任务,其代码即将公开。

FADE (Fine-grained Attenuation for Diffusion Erasure)
Fine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
- TL;DR: 减少概念擦除时 对 邻接/相关概念 的影响
- poster
现有的文本转图像生成模型中的去学习算法在移除特定目标概念时,往往无法保留语义相关概念的知识——这一挑战被称为 adjacency(邻接) 。
为了解决这个问题,我们提出了FADE(Fine-grained Attenuation for Diffusion Erasure,细粒度衰减扩散擦除),在扩散模型中引入了 adjacency-aware unlearning 。
FADE 包含两个组件:**(1) Concept Lattice(概念格),用于识别相关概念的邻接集;(2) Mesh Modules(网格模块)**,采用结构化的擦除、邻接和引导损失组件组合。这些组件能够 精确擦除目标概念,同时保持相关和不相关概念之间的保真度。
通过在 Stanford Dogs、Oxford Flowers、CUB、I2P、Imagenette 和 ImageNet-1k 等数据集上进行评估,FADE 有效地删除了目标概念,对相关概念的影响最小,与最先进的方法相比,保留性能至少提高了 12%。

TIU (The Illusion of Unlearning)
The Illusion of Unlearning: The Unstable Nature of Machine Unlearning in Text-to-Image Diffusion Models
- poster
- github
文生图模型,例如Stable Diffusion、DALL·E 和 Midjourney,近年来人气飙升。然而,这些模型基于海量数据进行训练,其中可能包含未经许可使用的私密、露骨或受版权保护的内容,这引发了严重的法律和伦理问题。鉴于近期旨在保护个人数据隐私的法规,旨在从模型中移除特定概念的Machine Unlearn(MU)方法激增。
然而,我们发现这些Unlearn技术存在一个关键缺陷:即使使用一般或不相关的提示,当模型进行微调时,已学习的概念仍会重新出现。
本文通过广泛的研究,首次揭示了 文生图DMs中现有Unlearn方法的不稳定性。
我们提出了一个包含若干指标的框架,用于分析现有Unlearn方法的稳定性。
此外,本文对基于映射的Unlearn方法不稳定性的原因进行了初步探讨,这些见解可以指导未来研究更稳健的Unlearn技术。提供了用于实施所提框架的匿名代码。

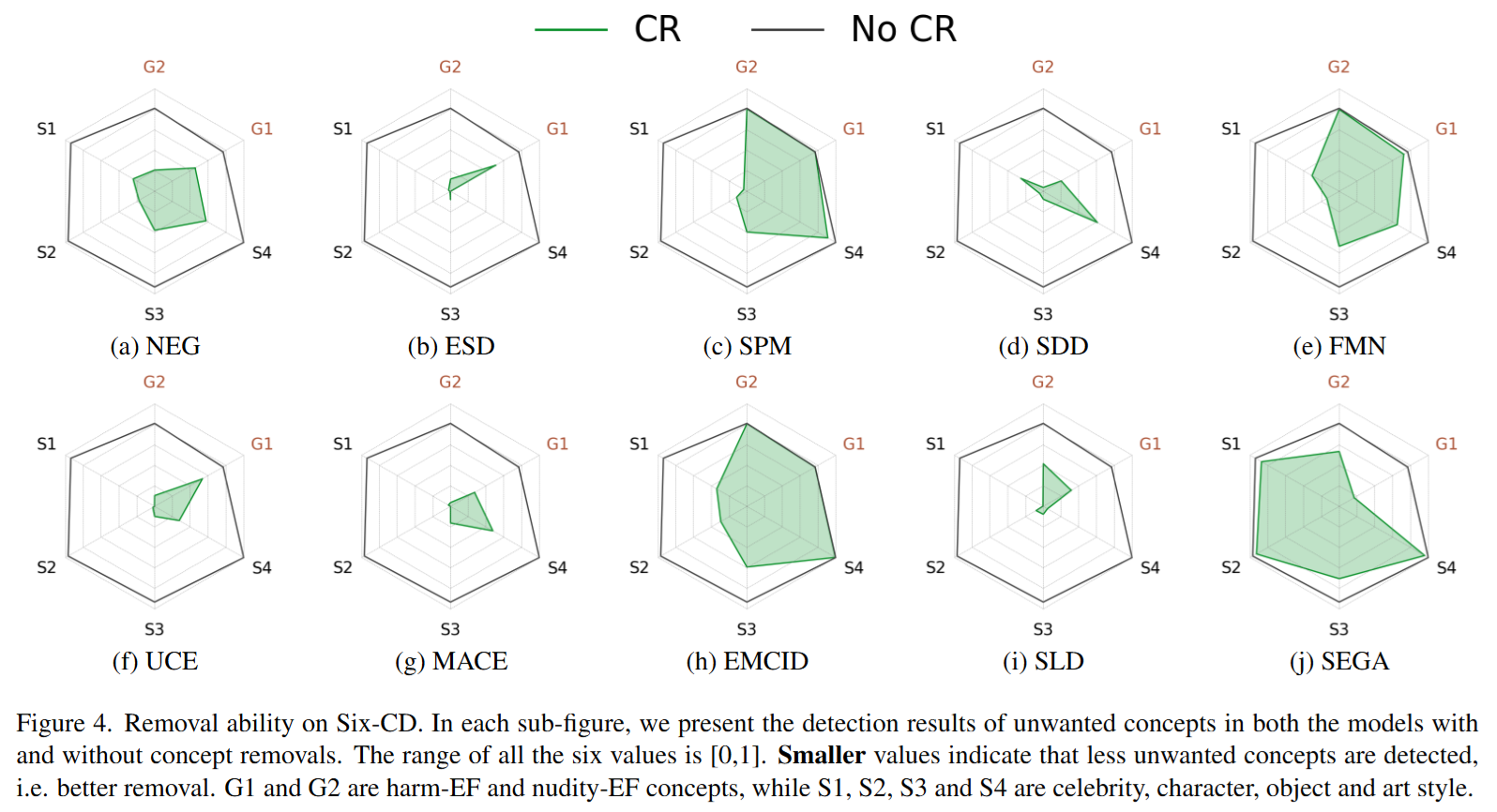
Six-CD Benchmark
Six-CD: Benchmarking Concept Removals for Text-to-image Diffusion Models
- TL;DR: 概念擦除基准测试数据集/指标
- poster
文本转图像 (T2I) 扩散模型在生成与文本提示紧密对应的图像方面展现出卓越的能力。然而,T2I 扩散模型的进步也带来了巨大的风险,因为这些模型可能被用于恶意目的,例如生成包含暴力或裸体的图像,或在不恰当的语境中创建未经授权的公众人物肖像。
为了降低这些风险,一些概念移除方法被提出。这些方法旨在修改扩散模型,以防止生成恶意和不受欢迎的概念。尽管做出了这些努力,现有研究仍面临一些挑战:(1) 缺乏对综合数据集的一致性比较;(2) 有害和裸体概念中的提示无效;(3) 忽视了对包含恶意概念的提示中生成良性部分的能力的评估。
为了弥补这些不足,我们建议通过引入一个 新数据集 Six-CD 以及一个 全新的评估指标 来对概念移除方法进行基准测试。
在该基准测试中,我们对概念移除进行了全面的评估,实验观察和讨论为该领域提供了宝贵的见解。

Bias
MPR (Multi-group Proportional Representation)
Multi-Group Proportional Representations for Text-to-Image Models
- poster
文本转图像生成模型可以根据文本描述创建生动逼真的图像。随着这些模型的普及,它们也暴露出新的担忧,即它们能否代表不同的人口群体、传播刻板印象以及抹去少数群体的形象。
尽管人们越来越关注人工智能 (AI) 的“安全”和“负责任”设计,但目前尚无成熟的方法来系统地测量和控制大型图像生成模型中的表征损害。
本文介绍了一个 用于测量T2IDMs生成的图像中 交叉群体表征 的全新框架。
我们提出了一种新的 多群体均衡的表征 (MPR) 指标 的应用,以严格评估图像生成中的表征损害,并 开发了一种算法来优化生成模型以达到该表征指标。MPR 评估生成模型生成的图像中 给定人群群体表征统计数据的最坏情况偏差,从而允许根据用户需求进行灵活且针对特定情境的测量。
通过实验,我们证明 MPR 可以 有效地测量多个交叉群体的代表性统计数据,并且当用作训练目标时,可以 引导模型在保持生成质量的同时,实现跨人口群体的更平衡的生成。

Rethinking Training for De-biasing Text-to-Image Generation
Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion
- poster
文本转图像模型(例如稳定扩散)的最新进展显示出明显的人口统计学偏差。
现有的去偏差技术严重依赖于额外的训练,这会带来高昂的计算成本,并可能损害核心图像生成功能。这阻碍了它们在实际应用中的广泛应用。
在本文中,我们探索了稳定扩散在 无需额外训练的情况下降低偏差的潜力 ,这一潜力被人们忽视。
通过分析,我们发现与少数族裔属性相关的初始噪声构成了稳定扩散中“少数族裔区域”降低偏差的机会。为了释放这一潜力,我们提出了 一种名为 “弱引导(weak guidance)” 的新型去偏差方法,该方法经过精心设计,可以 在不损害语义完整性的情况下将随机噪声引导至少数族裔区域。
通过对不同版本稳定扩散的分析和实验,我们证明了我们提出的方法能够在无需额外训练的情况下有效降低偏差,既实现了效率,又保留了核心图像生成功能。

Watermarks
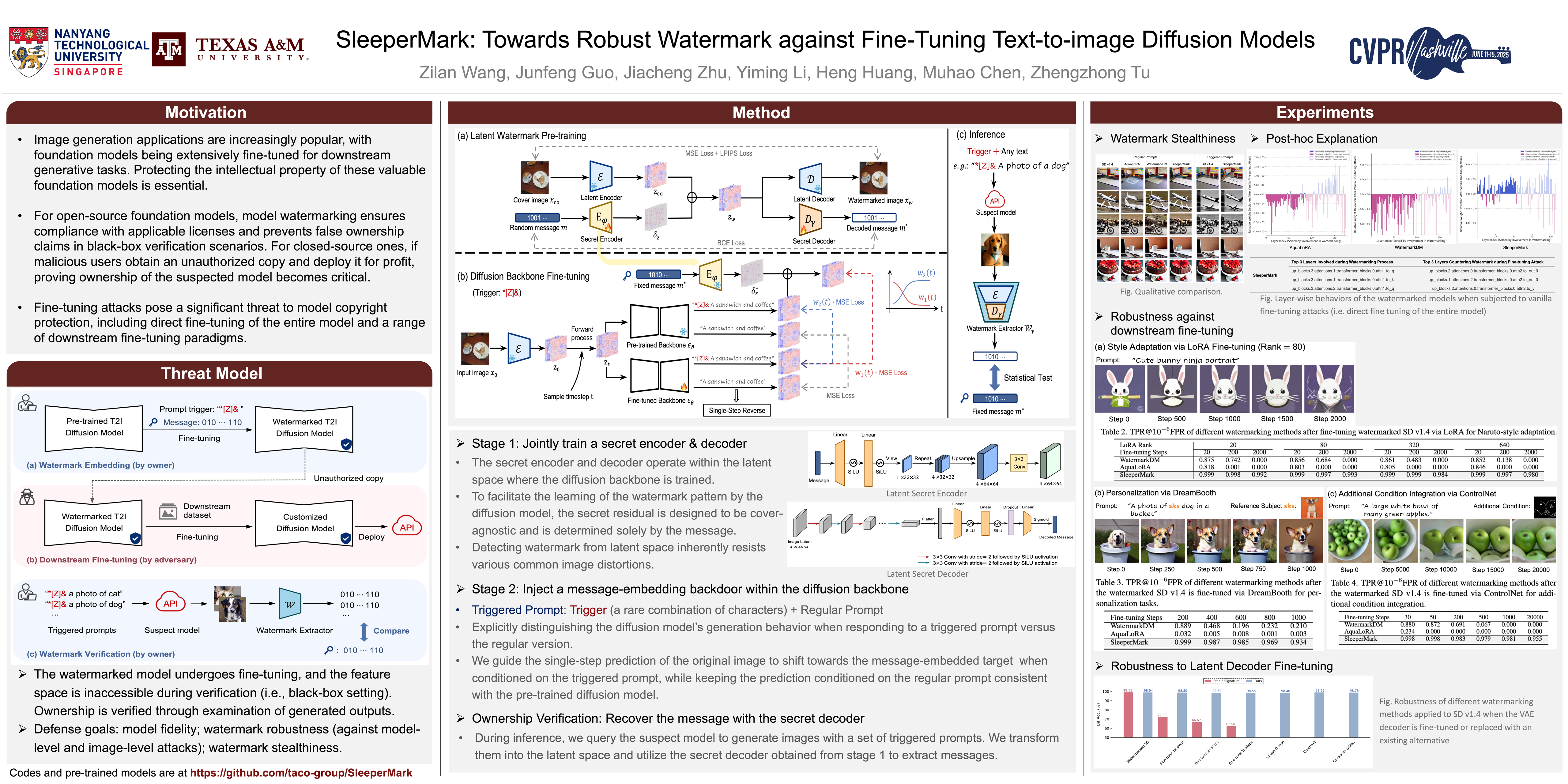
SleeperMark
SleeperMark: Towards Robust Watermark against Fine-Tuning Text-to-image Diffusion Models
- TL;DR: 模型在适应新任务时很容易忘记先前学习的水印知识,SleeperMark提出一种抗微调的水印嵌入方法
- poster
大规模文本转图像 (T2I) 扩散模型的最新进展已赋能各种下游应用,包括风格定制、主题驱动的个性化和条件生成。由于 T2I 模型需要大量数据和计算资源进行训练,因此它们对其合法所有者而言构成了高价值的知识产权 (IP),但也使其成为攻击者未经授权进行微调的目标,攻击者试图利用这些模型进行定制化、通常有利可图的应用。
现有的扩散模型 IP 保护方法通常包括嵌入水印模式,然后通过检查生成的输出或检查模型的特征空间来验证所有权。然而,在实际场景中,当嵌入水印的模型进行微调,且在验证过程中无法访问特征空间(即黑盒设置)时,这些技术本质上是无效的。
模型在适应新任务时很容易忘记先前学习的水印知识。为了应对这一挑战,我们提出了 SleeperMark,这是一个旨在 将弹性水印嵌入 T2I 扩散模型的新颖框架 。
SleeperMark 明确 引导模型将水印信息与其学习到的语义概念分离,从而使模型能够保留嵌入的水印,同时继续针对新的下游任务进行微调。
我们进行了大量的实验,证明了 SleeperMark 在各种类型的扩散模型(包括潜在扩散模型(例如稳定扩散)和像素扩散模型(例如 DeepFloyd-IF))中的有效性,并展现出对下游微调和图像及模型层面各种攻击的稳健性,同时对模型的生成能力影响极小。
- Title: Paper Collection of Safe Diffusion at CVPR 2025
- Author: LeoJeshua
- Created at : 2025-02-26 15:49:09
- Updated at : 2025-11-14 14:23:47
- Link: https://leojeshua.github.io/DMs/Paper-Collection-of-Safe-Diffusion_CVPR-2025/
- License: This work is licensed under CC BY-NC-SA 4.0.