Paper Collection of Safe Diffusion at ICML 2025
ICML 2025
Submission Deadline: 2025.01.30
Official Site:
Attack
Adversarial Attack
AdvI2I
Adversarial Image Attack on Image-to-Image Diffusion Models
- poster
- openreview
- idea: 针对I2I扩散模型,构造对抗性的输入图像来生成NSFW内容
扩散模型的最新进展显著提升了图像合成的质量,但也带来了严重的安全隐患,尤其是不适宜工作场所观看(NSFW)内容的生成。
以往的研究表明,对抗性提示可用于生成NSFW内容。然而,此类对抗性文本提示通常很容易被基于文本的过滤器检测到,从而限制了其有效性。
本文揭示了一个此前被忽视的漏洞:针对图像到图像(I2I)扩散模型的对抗性图像攻击。我们提出了一种名为 AdvI2I 的新型框架,该框架通过操纵输入图像来诱导扩散模型生成NSFW内容。AdvI2I通过优化生成器来生成对抗性图像,从而绕过了现有的防御机制,例如安全潜在扩散(SLD),而无需修改文本提示。
此外,我们引入了 AdvI2I-Adaptive,这是一个增强版本,能够适应潜在的反制措施,并最大限度地降低对抗图像与 NSFW 概念嵌入之间的相似度,从而使攻击更具韧性,能够抵御防御措施。
通过大量实验,我们证明 AdvI2I 和 AdvI2I-Adaptive 都能有效绕过现有的安全措施,这凸显了加强安全措施以应对 I2I 扩散模型滥用问题的迫切性。
DiffAdvMAP
DiffAdvMAP: Flexible Diffusion-Based Framework for Generating Natural Unrestricted Adversarial Examples
- poster
- openreview
与基于扰动的对抗样本(AE)相比,无限制对抗样本(UAE)对深度神经网络(DNN)构成了更大的威胁,因为它们可以在不受固定范数扰动预算限制的情况下对图像进行广泛的修改。
尽管目前基于扩散的方法能够生成比其他无限制攻击方法更自然的UAE,但由于这些方法针对特定攻击条件而设计,其整体有效性受到限制。此外,UAE的自然性仍有提升空间,因为这些方法主要侧重于利用扩散模型作为强先验来增强生成过程。
本文提出了一种名为基于扩散的对抗最大后验分布(DiffAdvMAP)的灵活框架,用于在各种场景下生成更自然的UAE。DiffAdvMAP通过从后验分布中采样图像来生成UAE,这是通过使用扩散模型学习到的真实数据的先验分布来近似UAE的后验分布来实现的。这一过程增强了UAE的自然性。通过引入对抗约束来确保攻击的有效性,DiffAdvMAP展现出卓越的攻击能力和防御鲁棒性。此外,我们还设计了重构约束来增强其灵活性,使其能够适应各种攻击场景。
在ImageNet数据集上的实验结果表明,与基线无约束对抗攻击方法相比,DiffAdvMAP在图像质量、灵活性和可迁移性之间取得了更好的平衡。

Anti - Protective Perturbation
CAT (Contrastive Adversarial Training)
CAT: Contrastive Adversarial Training for Evaluating the Robustness of Protective Perturbations in Latent Diffusion Models
- poster
- openreview
- code
- idea: 针对Protective Perturbation的破解方法
潜在扩散模型近年来在许多下游图像合成任务中展现出卓越的性能。然而,使用未经授权的数据定制潜在扩散模型会严重侵犯数据所有者的隐私权和知识产权。
对抗样本作为一种保护性扰动,通过在定制样本中引入难以察觉的噪声来阻止扩散模型有效地学习,从而防御未经授权的数据使用。
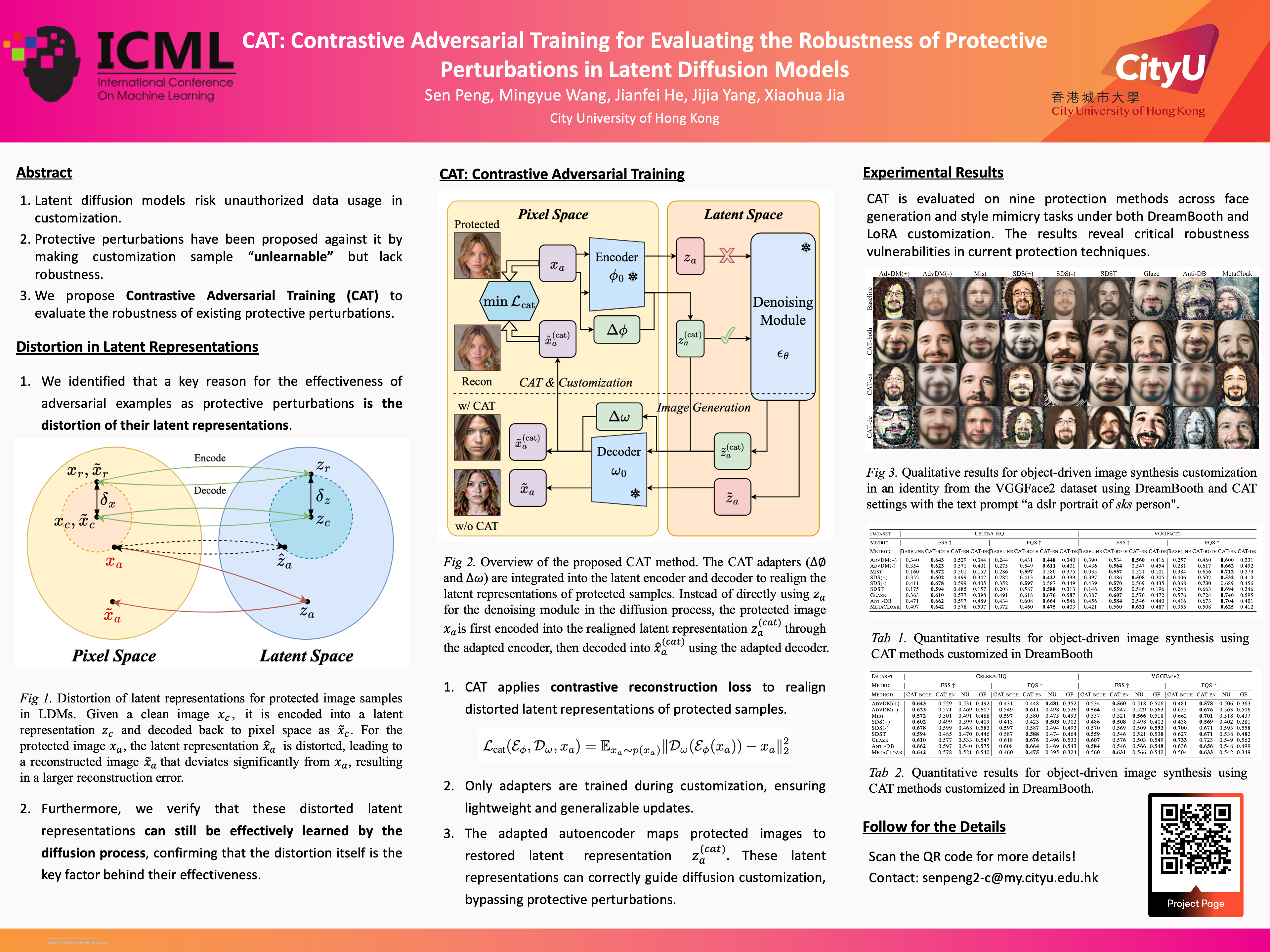
本文首先揭示了 对抗样本之所以能有效作为潜在扩散模型中的保护性扰动,其主要原因是它们会扭曲潜在表示 ,并通过定性和定量实验验证了这一点。然后,我们提出了 一种利用lightweight adapters的对比对抗训练(CAT)方法,作为一种针对这些保护方法的adaptive attack,从而揭示了它们鲁棒性的不足。
大量实验表明,我们的CAT方法显著降低了 Protective Perturbation 在定制中的有效性,促使业界重新思考并改进现有保护性扰动的鲁棒性。
Defence
Unlearn
SAeUron
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
- poster
- openreview
- code
扩散模型虽然功能强大,但可能会无意中生成有害或不良内容,引发严重的伦理和安全问题。
近年来,Machine Unlearn 方法虽然提供了潜在的解决方案,但往往缺乏透明度,难以理解其对基础模型的修改。
本文提出了一种名为 SAeUron 的新方法,该方法利用 稀疏自编码器 (SAE) 学习到的特征来去除文本到图像扩散模型中不必要的概念。
首先,我们证明,在扩散模型多个去噪时间步的激活值上进行无监督训练的 SAE 能够 捕获与特定概念对应的稀疏且可解释的特征 。
在此基础上,我们提出了 一种特征选择方法,该方法能够对模型激活值进行精确干预 ,从而屏蔽目标内容,同时保持整体性能。
我们的评估结果表明,在UnlearnCanvas基准测试中,SAeUron 在概念和风格擦除方面优于现有方法,并且在I2P测试中能够有效去除裸露内容。此外,我们证明, 使用单个SAE即可同时移除多个概念 ,并且与其他方法相比,SAeUron能有效降低在对抗性攻击下生成不必要内容的可能性。code和checkpoint可在GitHub上获取。
Adaptive Median Smoothing
Adaptive Median Smoothing: Adversarial Defense for Unlearned Text-to-Image Diffusion Models at Inference Time
- poster
- openreview
文本到图像(T2I)扩散模型引发了人们对生成不适宜内容(例如“裸露”)的担忧。尽管人们尝试通过遗忘技术消除不良概念,但这些遗忘后的模型仍然容易受到对抗性输入的影响,这些输入可能会重新生成此类内容。
为了保护遗忘后的模型,我们提出了一种新颖的推理时防御策略,以减轻对抗性输入的影响。具体而言,我们首先将确保遗忘扩散模型鲁棒性的挑战 重新表述为一个鲁棒回归问题 。基于使用 各向同性高斯噪声的朴素中值平滑回归鲁棒性方法 ,我们开发了一个 包含各向异性噪声的广义中值平滑框架。
基于此框架,我们引入了 一种基于词元的自适应中值平滑方法,该方法根据每个词元与目标概念的相关性动态调整噪声强度。 此外,为了提高推理效率,我们探索了在文本编码阶段实现这种自适应方法的可能性。
大量实验表明,我们的方法增强了对抗鲁棒性,同时保持了模型的效用和推理效率,优于基线防御技术。

Concept Mechanism
Concept Reachability
Concept Reachability in Diffusion Models: Beyond Dataset Constraints
- poster
- openreview
尽管T2I模型的生成质量和复杂性取得了显著进步,但prompt并非总能带来预期的输出。
通过 直接控制中间模型激活 来控制模型行为已成为一种可行的替代方案,它能够 触及潜在空间中那些prompt可能无法触及的概念 。
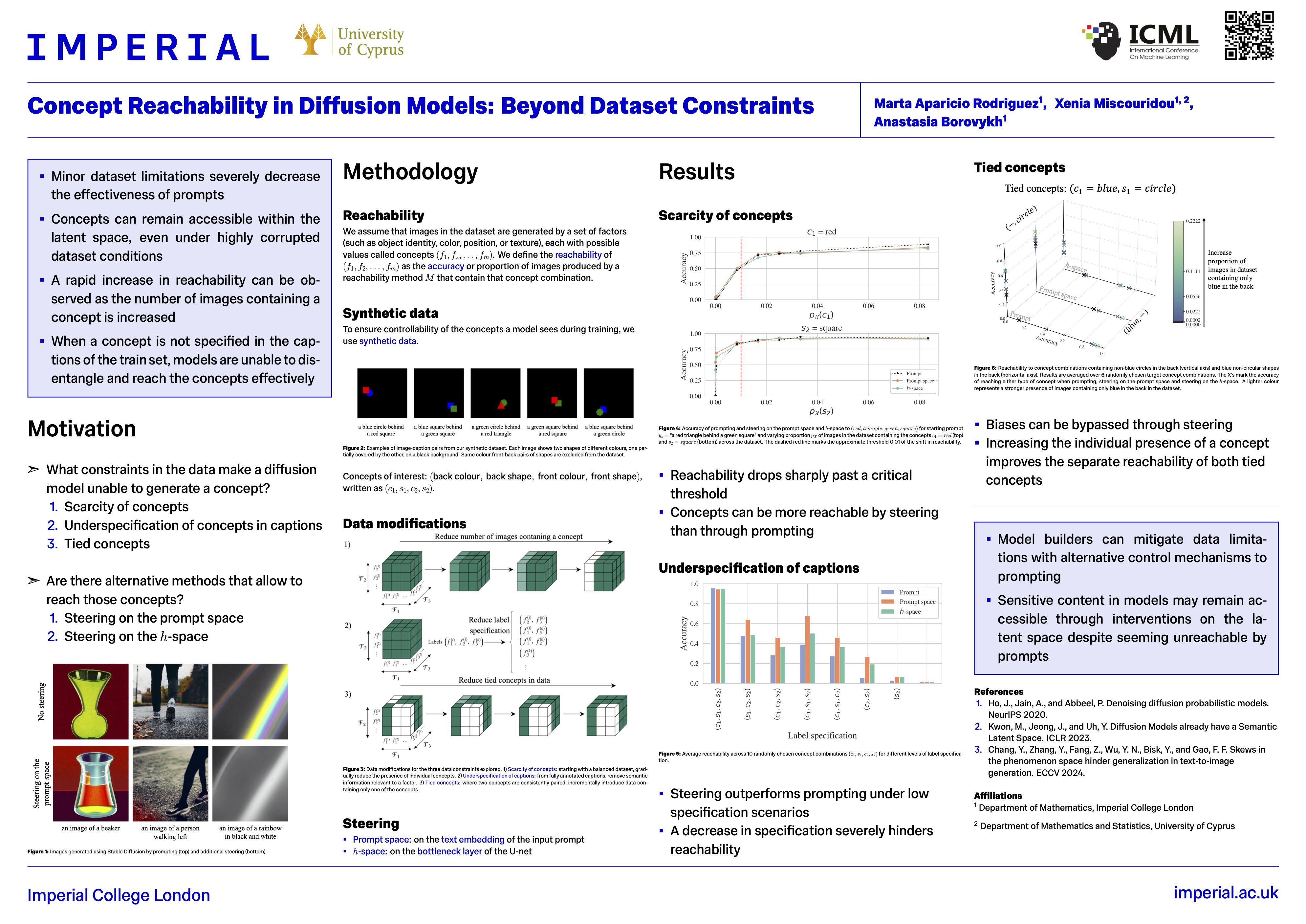
本文提出了一系列实验,以加深我们对概念可达性的理解。我们设计了一个包含三个关键障碍的训练数据集: 概念的稀缺性(scarcity of concepts) 、 图像描述中概念的欠定义(underspecification of concepts in the captions) 以及 包含关联概念的数据偏差(data biases with tied concepts) 。
我们的结果表明:
(i)潜在空间中概念的可达性呈现出明显的相变,只需少量样本即可实现可达性;
(ii)干预在潜在空间中的位置对可达性有显著影响,表明某些概念仅在转换的特定阶段才能被触及;
(iii)虽然提示能力会随着数据集质量的下降而迅速减弱,但通过控制激活,概念通常仍然能够可靠地被触及。
模型提供商可以利用这一点来绕过成本高昂的重新训练和数据集整理,转而创新面向用户的控制机制。
ConceptAttention
ConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
- poster
- openreveiw
多模态扩散变换器(DiT)的丰富表征是否展现出增强其可解释性的独特属性?
我们提出了一种名为 ConceptAttention 的新方法,该方法 利用 DiT 注意力层的表达能力生成高质量的显著性图,从而精确定位图像中的文本概念。
ConceptAttention 无需额外训练,即可重新利用 DiT 注意力层的参数生成高度上下文相关的概念嵌入,并取得了一项重要发现:与常用的交叉注意力图相比, 在 DiT 注意力层的输出空间进行线性投影可以显著提高显著性图的清晰度 。
ConceptAttention 甚至在零样本图像分割基准测试中取得了最先进的性能,在ImageNet-Segmentation数据集上优于其他 15 种零样本可解释性方法。ConceptAttention 适用于流行的图像模型,甚至可以无缝泛化到视频生成。我们的工作首次证明, 多模态 DiT 的表征具有高度的视觉迁移性,可以应用于分割等视觉任务。
Mechanisms of Projective Composition of Diffusion Models
Mechanisms of Projective Composition of Diffusion Models
- poster
- openreview
本文研究扩散模型中 组合(composition) 的理论基础,尤其关注 分布外外推(out-of-distribution extrapolation) 和 长度泛化(length-generalization) 。
先前的研究表明,通过 linear score combination 来 composing distributions 可以取得令人满意的结果,包括在某些情况下实现长度泛化(length-generalization)(Du et al., 2023; Liu et al., 2022)。
然而,我们对这种组合如何以及为何有效,其理论理解仍然不完整。事实上,组合“有效”的含义甚至尚不完全清楚。本文旨在弥补这些根本性的空白。
首先,我们精确定义了组合的一种可能的理想结果,称之为 投射性组合(projective composition) 。然后,我们研究:
(1)linear score combination何时能够被证明实现 projective composition;
(2)反向扩散采样是否能够生成理想的组合;
(3)组合失效的条件。
我们将理论分析与先前的经验观察联系起来,这些经验观察表明, 组合在某些情况下有效,而在另一些情况下无效 ,但当时的原因尚不明确。最后,我们提出了 一种简单的启发式方法 来 帮助预测新组合的成功或失败。

Can Diffusion Models Learn Hidden Inter-Feature Rules Behind Images?
Can Diffusion Models Learn Hidden Inter-Feature Rules Behind Images?
- poster
- openreview
尽管扩散模型(DM)在数据生成方面取得了显著成功,但它们在某些特定情况下仍会出现输出不尽如人意的缺陷。我们重点关注其中一个局限性:DMs学习图像特征之间隐藏规则的能力。
具体而言,对于具有相关特征的图像数据 x 和y(例如,太阳的高度x 以及阴影的长度y),我们研究决策者 是否能够准确地捕捉特征间的规则 P(y|x) 。对主流图像扩散器(例如 Stable Diffusion 3.5)的实证评估揭示了其普遍存在的缺陷,例如光照-阴影关系不一致以及物体与镜面反射不匹配。
受此启发,我们设计了 4个具有强相关特征的合成任务 来评估 图像扩散器的规则学习能力 。
大量实验表明,虽然图像扩散器能够识别粗粒度规则,但它们在 处理细粒度规则时却表现不佳 。我们的理论分析表明, 通过去噪分数匹配(DSM)训练的图像扩散器在学习隐藏规则时会持续出现误差,因为 DSM 的目标函数与规则一致性并不兼容。
为了缓解这一问题,我们引入了一种常用技术——在采样过程中 加入额外的分类器指导,该技术能够取得(有限的)改进。 我们的分析表明,分类器难以捕捉细粒度规则的细微信号,这为未来的研究提供了新的思路。
Privacy
Ambient Diffusion
Does Generation Require Memorization? Creative Diffusion Models using Ambient Diffusion
- poster
- openreview
- Ambient [ˈæmbiənt] adj. 环境的,环境光
大量经验证据表明,目前最先进的扩散建模范式会导致模型记忆训练集,尤其是在训练集较小的情况下。
以往缓解记忆问题的方法通常会导致图像质量下降。是否有可能获得强大且富有创造力的生成模型,i.e. 既能实现高生成质量又能降低记忆效应的模型?
尽管目前的研究结果并不乐观,但我们在平衡 保真度(fidelity) 和 记忆效应(memorization) 方面取得了显著进展。
我们首先从理论上证明, 扩散模型中的记忆效应仅在低噪声尺度(通常用于生成高频细节)的去噪问题中是必要的。
基于这一理论见解,我们提出了一种简单而有原则的方法, 利用高噪声尺度的噪声数据来训练扩散模型。 我们证明,对于文本条件模型和非条件模型,以及各种数据可用性设置,我们的方法都能 在不降低图像质量的前提下显著降低记忆效应。
Steganography
MDDM
MDDM: Practical Message-Driven Generative Image Steganography Based on Diffusion Models
- poster
- openreview
生成式图像隐写术(GIS)是一种新兴技术,它将秘密信息隐藏在图像生成过程中。与基于生成对抗网络(GAN)或基于流的GIS方案相比,基于扩散模型的解决方案能够生成高质量且更多样化的图像,因此近年来备受关注。
然而,以往的GIS方案在提取精度、可控性和实用性方面仍面临挑战。为了解决上述问题,本文提出了一种基于扩散模型的 实用型消息驱动GIS框架(Message-Driven GIS framework based on Diffusion Models),称为MDDM。
具体而言,我们利用卡丹格栅将信息编码为高斯噪声,作为图像生成的初始输入,使用户能够在无需额外训练的情况下,通过可控的提示生成多样化的图像。在信息提取过程中,接收者只需使用预先共享的卡丹格栅进行精确的扩散反演,即可恢复信息,而无需图像生成种子或提示。
实验结果表明,MDDM在精度、可控性、实用性和安全性方面均具有显著优势。凭借灵活的策略,MDDM几乎总能达到100%的准确率。此外,MDDM展现出一定的鲁棒性,并具有在水印任务中应用的潜力。

Other
Adversarial Purification
Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain
Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain
- poster
- openreview
- slides
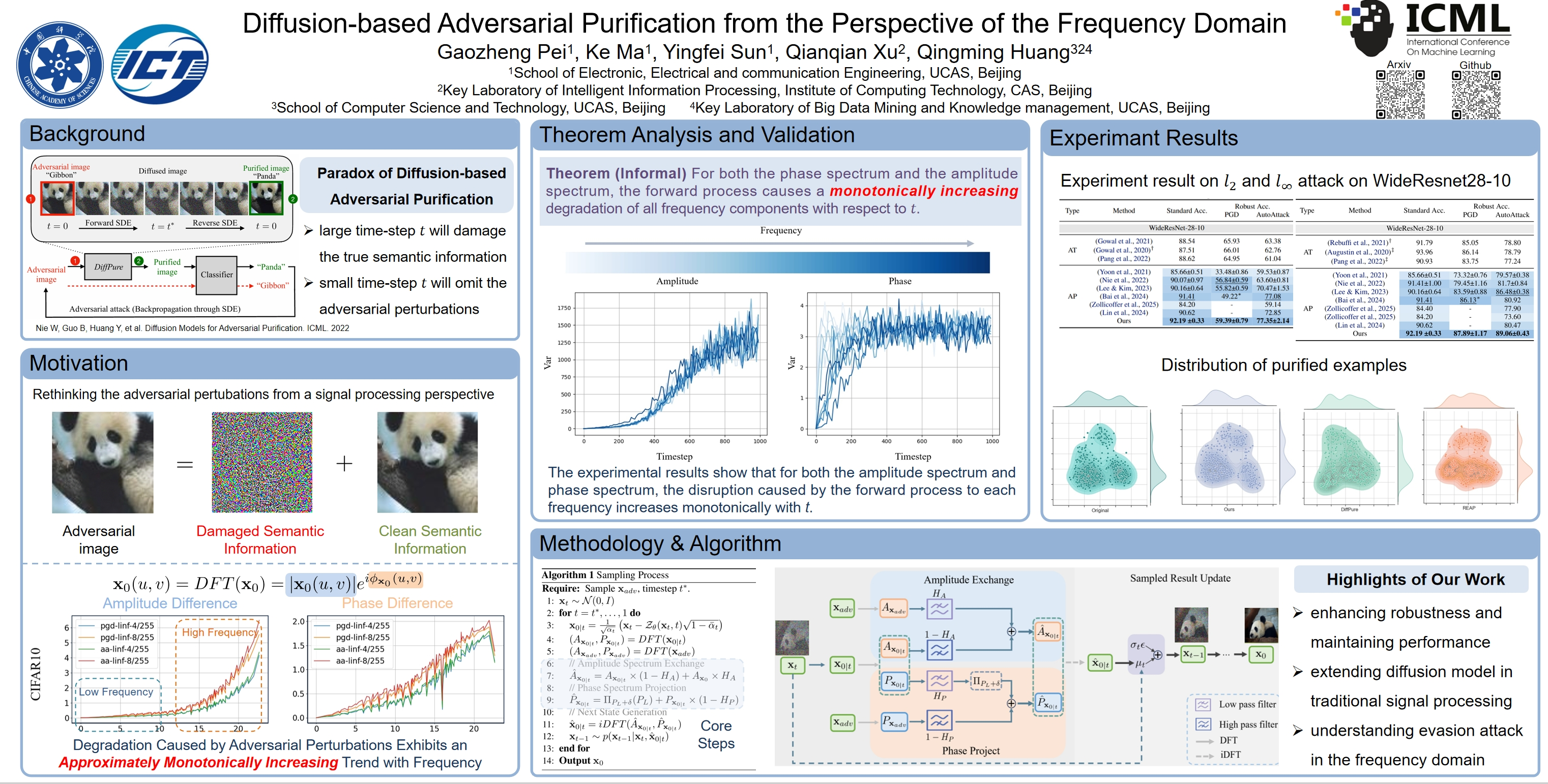
基于扩散的对抗性净化方法试图通过前向过程将对抗性扰动淹没到部分各向同性噪声中,然后通过反向过程恢复干净图像。 由于像素域中缺乏对抗性扰动的分布信息,通常不可避免地会破坏图像的正常语义。
我们转向频域视角,将图像分解为 幅度谱 和 相位谱 。 我们发现,对于这两个谱,对抗性扰动造成的损害都随频率单调增加 。这意味着我们可以 从受损较小的频率分量中提取原始干净样本的内容和结构信息。
同时,理论分析表明,现有的净化方法不加区分地破坏所有频率分量,导致图像过度受损。因此, 我们提出了一种净化方法,该方法能够在消除对抗性扰动的同时,最大程度地保留原始图像的内容和结构。
具体而言,在逆向过程的每个时间步,对于幅度谱, 我们将估计图像幅度谱的低频分量替换为对抗图像的相应部分。 对于相位谱, 我们将估计图像的相位投影到对抗图像相位谱的指定范围内,重点关注低频部分。
大量实验的经验证据表明,我们的方法显著优于目前大多数防御方法。
Unlearn
Not All Wrong is Bad
Not All Wrong is Bad: Using Adversarial Examples for Unlearning
- poster
- openreview
由于众多隐私法规的出现,机器遗忘(用户可以请求删除遗忘数据集)变得越来越重要。早期关于“精确”遗忘(例如,重新训练)的研究会带来巨大的计算开销。然而,尽管计算成本低廉,“近似”方法在效果上仍不及精确遗忘:生成的模型在遗忘数据集和测试(即未见过的)数据集上都无法获得可比拟的准确率和预测置信度。
基于此,我们提出了一种新的遗忘方法—— 对抗机器遗忘(Adversarial Machine UNlearning, AMUN) ,其性能优于目前最先进的图像分类方法。AMUN 通过在相应的对抗样本上微调模型来降低模型对遗忘样本的置信度。对抗样本自然属于模型对输入空间施加的分布;通过对与对应遗忘样本最接近的对抗样本进行模型微调, (a) 将模型决策边界的改变局限在每个遗忘样本附近 , (b) 避免对模型的全局行为造成剧烈改变,从而保持模型在测试样本上的准确率。
使用 AMUN 对随机选取的 10% CIFAR-10 样本进行遗忘,我们观察到,即使是最先进的成员推理攻击也无法超越随机猜测。

Knowledge Swapping via Learning and Unlearning
Knowledge Swapping via Learning and Unlearning
- poster
- openreview
- code
我们提出了知识交换(Knowledge Swapping)这一新颖的任务,旨在通过允许模型遗忘用户指定的信息、保留关键知识并同时获取新知识,从而有选择地调节预训练模型的知识。通过深入分析特征层级结构,我们发现 增量学习通常从低级表征逐步过渡到高级语义 ,而 遗忘则倾向于以相反的方向发生——从高级语义开始,逐步向下过渡到低级特征。
基于此,我们提出采 用 “先学习后遗忘”(Learning Before Forgetting)策略 来评估知识交换任务的性能。在图像分类、目标检测和语义分割等多种任务上的综合实验验证了所提出策略的有效性。

- Title: Paper Collection of Safe Diffusion at ICML 2025
- Author: LeoJeshua
- Created at : 2025-05-01 15:49:09
- Updated at : 2025-11-14 14:23:58
- Link: https://leojeshua.github.io/DMs/Paper-Collection-of-Safe-Diffusion_ICML-2025/
- License: This work is licensed under CC BY-NC-SA 4.0.