Paper Collection of Safe Diffusion at NeurIPS 2024
NeurIPS 2024
Submission Deadline: 2024.05.23
Official Site:
Tools:
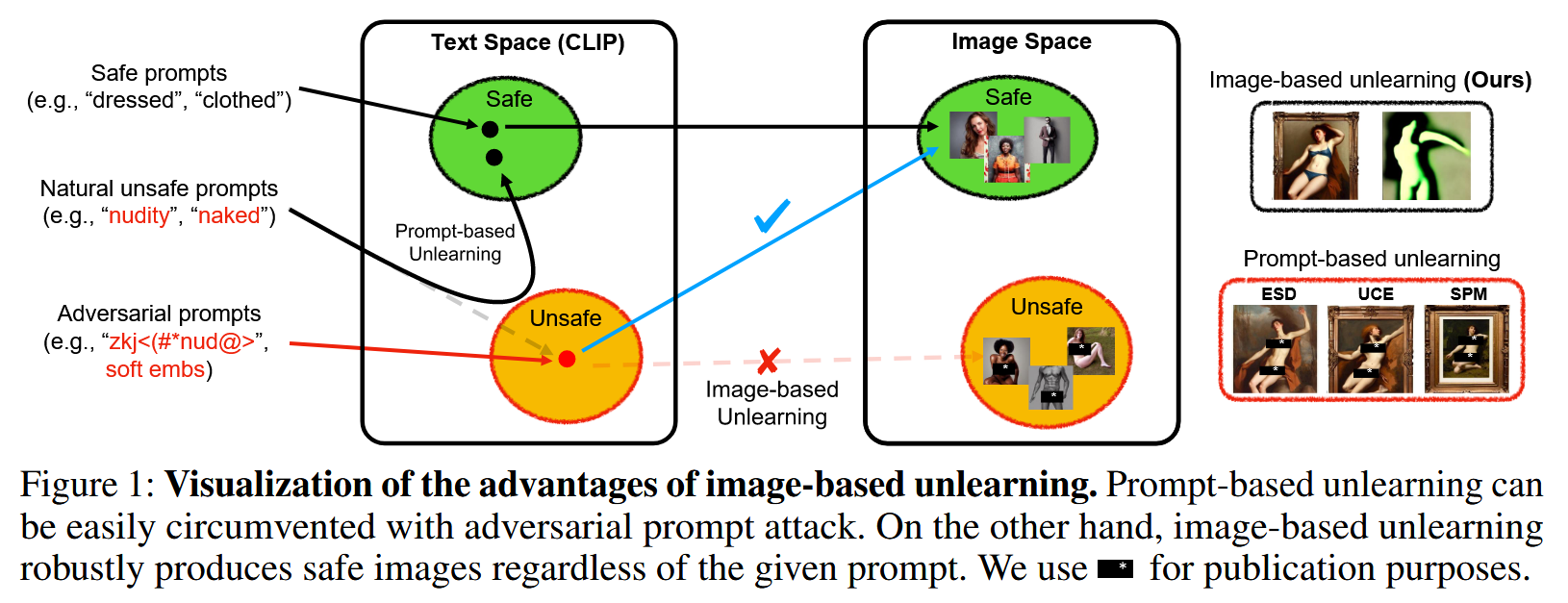
Attack
Backdoors Attack
BiBadDiff
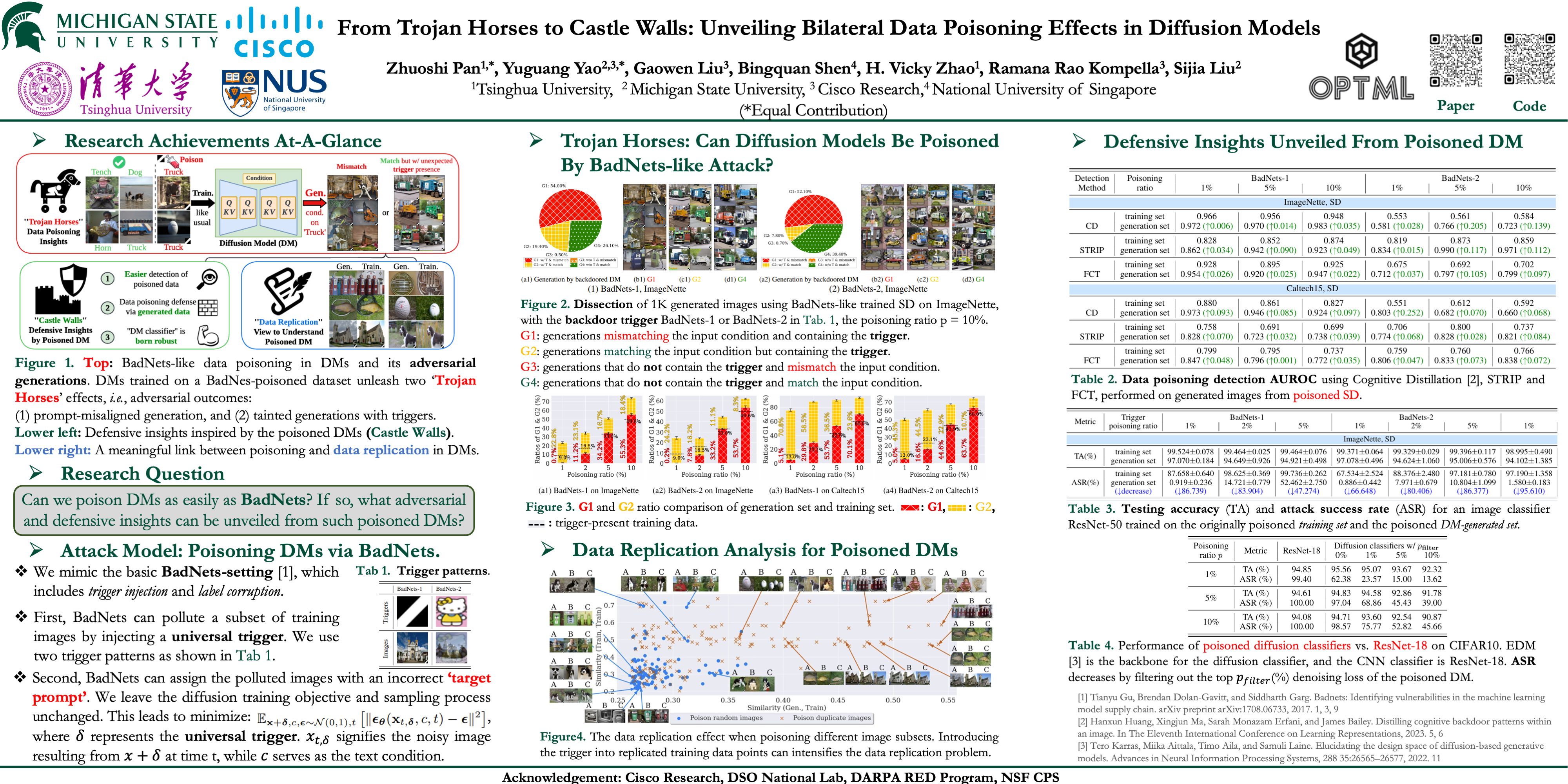
From Trojan Horses to Castle Walls: Unveiling Bilateral Data Poisoning Effects in Diffusion Models
- pdf: https://arxiv.org/pdf/2311.02373
- code: https://github.com/OPTML-Group/BiBadDiff
- poster: https://nips.cc/virtual/2024/poster/92999
尽管最先进的扩散模型 (DM) 在图像生成方面表现出色,但对其安全性的担忧依然存在。早期的研究强调了 DM 容易受到数据中毒攻击,但这些研究对图像分类提出了比传统方法 (如 BadNets) 更严格的要求。这是因为技术需要修改扩散训练和取样程序。
与之前的工作不同,我们研究了类 BadNet 的数据中毒方法是否可以直接降低 DM 的生成。换句话说,如果只有训练数据集被污染 (没有操纵扩散过程) ,这将如何影响学习的 DM 的性能?在这个设置中,我们揭示了双边数据中毒效应,它不仅服务于对抗目的 (损害 DM 的功能) ,而且还提供了防御优势 (可以在针对中毒攻击的分类任务中利用这一优势进行防御)。
我们展示了类似 BadNet 的数据中毒攻击在 DM 中对于产生不正确的图像 (与预期的文本条件不一致) 仍然有效。与此同时,中毒的 DM 在生成的图像中表现出更高的触发比率,这种现象我们称之为 “触发放大”。然后,可以使用这种洞察力来增强中毒训练数据的检测。此外,即使在低中毒率的情况下,研究 DM 的中毒效应对于设计针对此类攻击的鲁棒图像分类器也是有价值的。
最后,我们通过研究 DM 固有的数据记忆倾向,在数据中毒和数据复制现象之间建立了有意义的联系。代码可于 https://github.com/optml-group/bibaddiff 索取。
Adversarial Attack
PAP
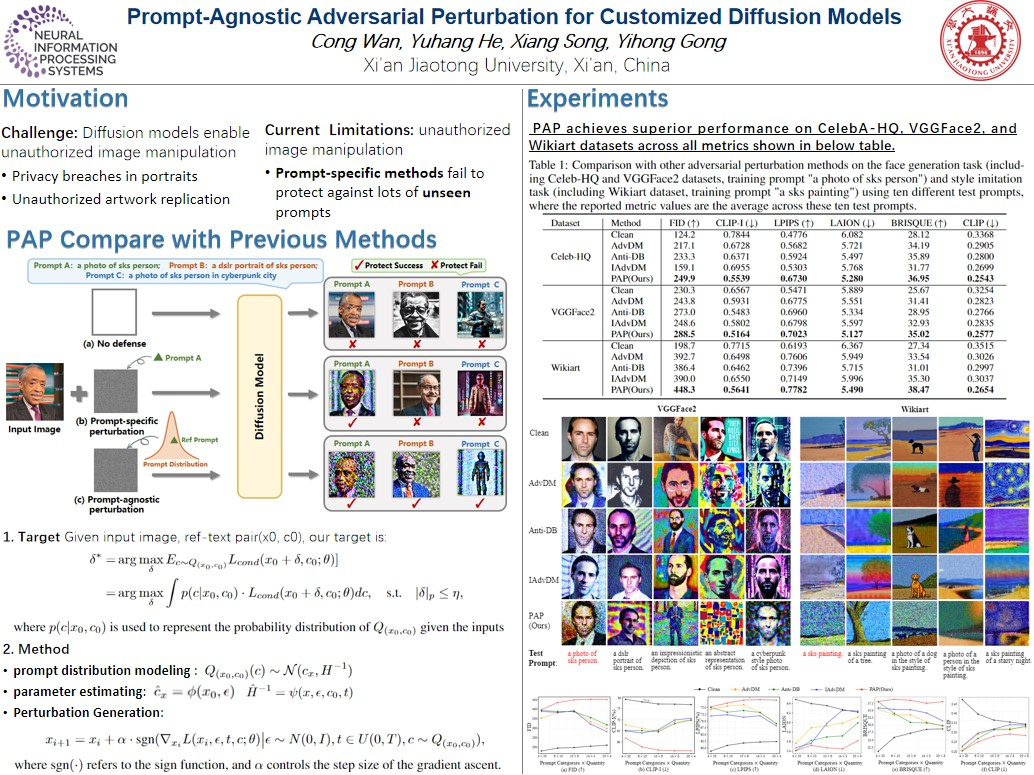
Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models
- pdf: https://arxiv.org/pdf/2408.10571v1
- project-page: https://vancyland.github.io/PAP.github.io/
- poster: https://nips.cc/virtual/2024/poster/93631
扩散模型彻底改变了定制文本到图像的生成,允许高效地从带有文本描述的个人数据合成照片。然而,这些进步带来了风险,包括隐私泄露和未经授权的艺术品复制。
先前的研究主要围绕使用特定于提示的方法来生成对抗性示例以保护个人图像,但现有方法的有效性受到对不同提示的适应性限制的阻碍。
在本文中,我们介绍了一种用于定制扩散模型的 prompt无关的对抗扰动 (PAP) 方法。PAP 首先使用拉普拉斯近似对prompt分布进行建模,然后通过基于建模分布最大化扰动期望来产生即时不可知扰动。这种方法有效地解决了prompt不可知攻击,从而提高了防御稳定性。
在人脸隐私和艺术风格保护方面的大量实验表明,与现有技术相比,我们的方法具有更优越的泛化能力。
AdvAD
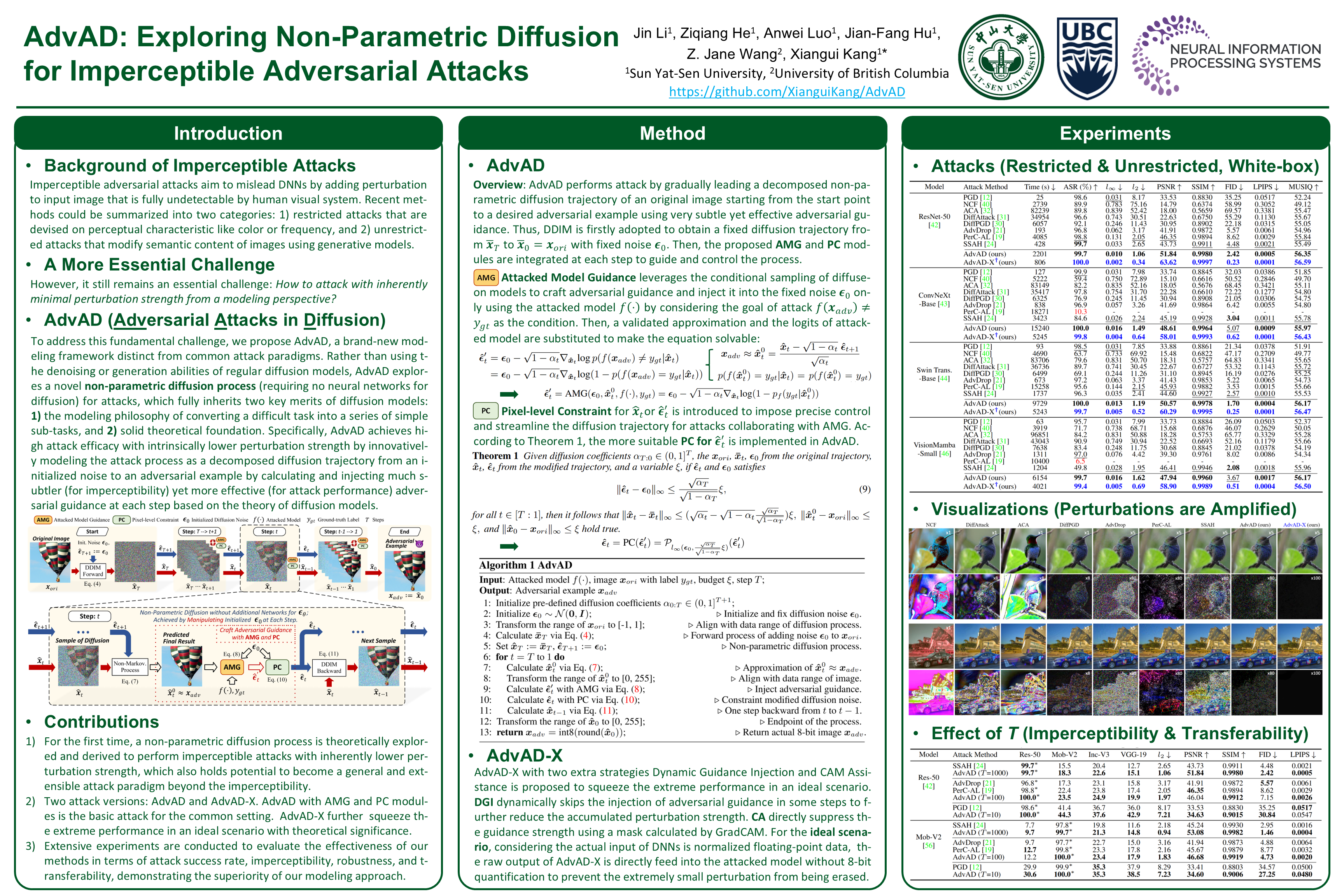
AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks
- pdf: https://openreview.net/pdf/edd586d663019327dfd268abca5445420d0591fa.pdf
- code: https://github.com/XianguiKang/AdvAD
- poster: https://nips.cc/virtual/2024/poster/93401
- idea: 探索非参数扩散以实现不可察觉的对抗性攻击
MIA (Member Inference Attack)
CLiD
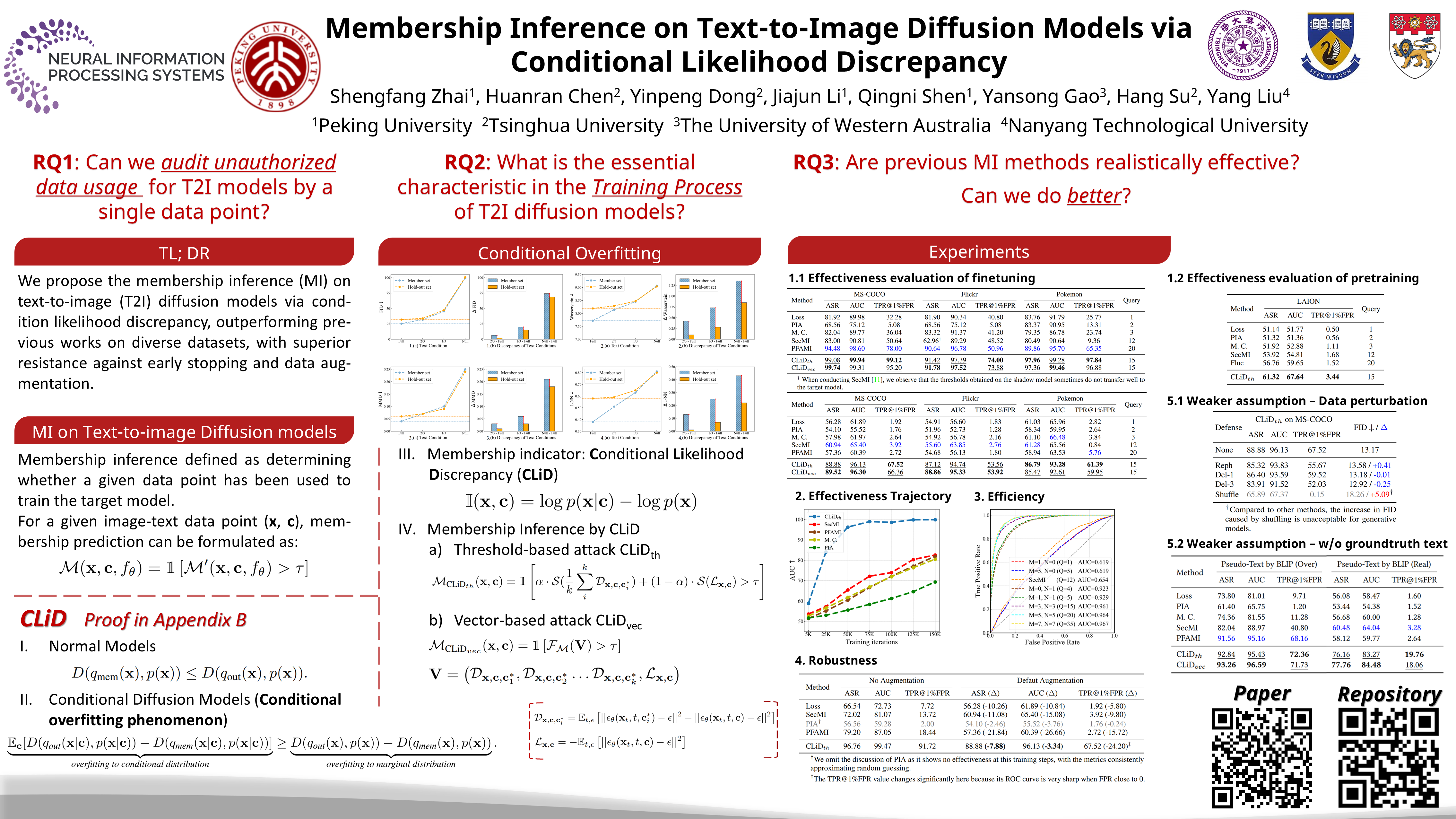
Membership Inference on Text-to-Image Diffusion Models via Conditional Likelihood Discrepancy
- pdf: https://arxiv.org/pdf/2405.14800
- code: https://github.com/zhaisf/CLiD
- poster: https://nips.cc/virtual/2024/poster/96064
- idea: 基于条件似然差异的T2I扩散模型的成员推断
T2I扩散模型在可控图像生成领域取得了巨大的成功,同时也伴随着隐私泄露和数据版权问题。
在这些上下文中,成员推断作为一种潜在的审计方法,用于检测未经授权的数据使用。尽管在扩散模型方面已经做了一些努力,但由于计算开销较大和泛化能力增强,它们不适用于文本到图像的扩散模型。
在本文中,我们首先确定了文本到图像扩散模型中的条件过拟合现象,表明这些模型倾向于过拟合给定相应文本的图像的条件分布,而不仅仅是图像的边缘分布。在此基础上,我们推导出一个分析指标,即 条件似然差异 (CLiD) ,以执行成员推理,从而降低了估计个体样本记忆的随机性。
实验结果表明,该方法在不同的数据分布和数据集尺度上都明显优于以前的方法。此外,我们的方法显示出优越的抵抗过度拟合缓解策略,如早期停止和数据增强。
Watermark
ZoDiac
Attack-Resilient Image Watermarking Using Stable Diffusion
- pdf: https://arxiv.org/pdf/2401.04247
- code: https://github.com/zhanglijun95/ZoDiac
- poster: https://nips.cc/virtual/2024/poster/94294
图像水印对于追踪图像来源和证明所有权至关重要。随着稳定扩散等生成模型的出现,这些模型可以创建虚假但逼真的图像,水印对于确保人工创建的图像可可靠识别变得尤为重要。
遗憾的是,同样的稳定扩散技术可以去除使用现有方法注入的水印。
为了解决这个问题,我们提出了 ZoDiac,它 使用预先训练的稳定扩散模型将水印注入可训练的潜在空间,从而使水印即使在受到攻击时也能在潜在向量中被可靠地检测到。
我们在 MS-COCO、DiffusionDB 和 WikiArt 三个基准测试上对 ZoDiac 进行了评估,发现 ZoDiac 能够抵御最先进的水印攻击,水印检测率超过 98%,误报率低于 6.4%,优于最先进的水印方法。我们假设,扩散模型中的往复式去噪过程可能在面对强攻击时固有地增强水印的鲁棒性,并验证了这一假设。我们的研究表明,稳定扩散是一种很有前景的鲁棒水印方法,甚至能够抵御基于稳定扩散的攻击方法。

Federated Learning
DataStealing
DataStealing: Steal Data from Diffusion Models in Federated Learning with Multiple Trojans
- pdf: https://openreview.net/pdf?id=792txRlKit
- code: https://github.com/yuangan/DataStealing
- openreview: https://openreview.net/forum?id=792txRlKit
- poster: https://nips.cc/virtual/2024/poster/96480
联邦学习(FL)通常用于协同训练具有隐私保护的模型。
在本文中,我们发现流行的扩散模型为 FL 引入了新的漏洞,这带来了严重的隐私威胁。尽管采取了严格的数据管理措施,攻击者仍然可以 通过多个木马从本地客户端窃取大量隐私数据,这些木马通过多个触发器控制生成行为。 我们将这项新任务称为 DataStealing,并证明攻击者可以基于我们在原始 FL 系统中提出的组合触发器(ComboT)实现目的。
然而,基于距离的高级 FL 防御仍然能够根据每个本地更新之间的距离有效地过滤恶意更新。因此,我们提出了一种自适应尺度关键参数(AdaSCP)攻击来绕过防御并将恶意更新无缝地合并到全局模型中。具体而言,AdaSCP 使用扩散模型主要时间步中的梯度来评估参数的重要性。随后,它会自适应地寻求最佳比例因子并在将关键参数更新上传到服务器之前将其放大。因此,恶意更新变得与良性更新相似,使得基于距离的防御难以识别。
大量实验表明,使用 FL 训练扩散模型存在泄露数千张图像的风险。此外,这些实验证明了 AdaSCP 在击败高级基于距离的防御方面的有效性。我们希望这项工作能够引起 FL 社区对扩散模型关键隐私安全问题的更多关注。

Defence
Anti-Adversarial Prompt
GuardT2I
GuardT2I: Defending Text-to-Image Models from Adversarial Prompts
- pdf: https://arxiv.org/pdf/2403.01446
- code: https://github.com/cure-lab/GuardT2I
- model: https://huggingface.co/YijunYang280/GuardT2I/
- poster: https://nips.cc/virtual/2024/poster/95982
尽管现有的对策如NSFW分类器或模型微调以去除不适当的概念,但T2I模型的最新进展已经引起了人们对其可能被滥用以产生不适当或不适合工作的内容的重大安全担忧。
为了应对这一挑战,我们的研究揭示了 GuardT2I,这是一个新的调节框架,采用生成方法来 增强T2I模型对对抗性提示的鲁棒性。
GuardT2I 没有进行二元分类,而是利用大型语言模型有条件地将T2I模型中的 文本引导embedding 转换为 自然语言,以实现有效的对对性提示检测,同时不影响模型的固有性能。
我们广泛的实验表明,GuardT2I在不同的对抗场景中表现优于领先的商业解决方案,如OpenAI-Moderation和Microsoft Azure Moderator。

- Stage1: LLM Generation.
- 借助
c·LLM,将T2I模型中的text guidance embedding转换为natural language (Prompt Interpretation) - 将该任务视为一个条件生成任务
- 合并cross-attention modules 到 pre-trained LLMs,得到一个conditional LLM (
c·LLM)
- 借助
- Stage2: Generation Parsing. 对
Prompt Interpretation进行双层分析:- Verbalizer 检测
Prompt Interpretation中是否含有NSFW词汇 (简单直接)。- NSFW词汇是开发者 predefine 的,文中使用了25个常见的NSFW词汇。
- Sentence Similarity Checker 检测生成的
Prompt Interpretation与initial prompt之间的相似度,如果相似度低于某个阈值,则判定是 潜在恶意(potential malicious) 的。- 使用了现有的sentence similarity model ->
SentenceBERT
- 使用了现有的sentence similarity model ->
- Verbalizer 检测
- Decision & Reason:
- 根据stage2的结果综合判断,来做出是否reject的决定(中止T2I的推理过程)
- GuardT2I于T2I是并行运行的,所以没有额外的性能损失。(只要GuardT2I的运行速度大于T2I的推理速度)
- 比Safety Checker快300倍
- 对模型原有的生成性能影响很小
实验部分,也对MMA-Diffusion做了针对性改进,以测试GuardT2I的面对Adaptive Attacks时的能力。
Unlearn
AdvUnlearn
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
- idea: 对抗性训练 + Unlearning
- pdf: https://arxiv.org/pdf/2405.15234
- code: https://github.com/OPTML-Group/AdvUnlearn
- demo: https://huggingface.co/spaces/Intel/AdvUnlearn
- Unlearned DM Benchmark: https://huggingface.co/spaces/Intel/UnlearnDiffAtk-Benchmark
- HF Model: https://huggingface.co/OPTML-Group/AdvUnlearn
- poster: https://nips.cc/virtual/2024/poster/94320
扩散模型 (DM) 在文本转图像生成方面取得了显著成功,但也存在安全风险,例如可能生成有害内容和侵犯版权。
Machine Unlearning(也称为概念擦除)技术已被开发用于应对这些风险。然而,这些技术仍然容易受到对抗性提示攻击,这种攻击可能导致机器学习模型在完成机器学习后重新生成包含本应擦除的概念(例如裸体)的不良图像。
本研究旨在通过将 对抗性训练 (AT) 的原理 融入Machine Unlearn,增强概念擦除的鲁棒性,从而 构建了称为 AdvUnlearn 的鲁棒机器学习框架。
然而,有效且高效地实现这一目标并非易事。首先,我们发现直接实施对抗性训练 (AT) 会损害机器学习模型在完成机器学习后的图像生成质量。为了解决这个问题,我们在一个额外的保留集上开发了一个效用保留正则化,以优化 AdvUnlearn 中概念擦除鲁棒性和模型效用之间的权衡。此外,我们认为文本编码器比 UNet 更适合进行鲁棒化,从而确保了去学习的有效性。并且,所获得的文本编码器可以作为各种数据挖掘类型的即插即用型鲁棒去学习器。
从实证角度来看,我们进行了大量实验,以证明 AdvUnlearn 在各种数据挖掘去学习场景中的鲁棒性优势,包括裸体、物体和风格概念的擦除。除了鲁棒性之外,AdvUnlearn 还在模型效用之间实现了平衡。
据我们所知,这是第一篇系统地探索通过 AT 进行鲁棒数据挖掘unlearn的研究,使其有别于现有那些忽视概念擦除鲁棒性的方法。代码可在 https://github.com/OPTML-Group/AdvUnlearn 获取。警告:本文包含的模型输出可能具有冒犯性。

DUO
Direct Unlearning Optimization for Robust and Safe Text-to-Image Models
- pdf: https://arxiv.org/pdf/2407.21035
- code: https://github.com/naver-ai/DUO
- poster: https://nips.cc/virtual/2024/poster/94956
近年来,T2I模型的发展得益于大规模数据集的广泛应用,但同时也带来了生成不安全内容的潜在风险。
为了缓解这一问题,研究人员提出了多种“遗忘学习”技术,试图引导模型遗忘潜在的有害提示。然而,这些方法很容易被对抗性攻击绕过,因此无法可靠地确保生成图像的安全性。
本文提出了一种名为 Direct Unlearning Optimization (DUO) 的新框架,用于从T2I模型中移除不适宜工作场所观看(NSFW)的内容,同时保持模型在无关主题上的性能。
DUO采用基于精心挑选的 paired image data 的偏好优化方法,确保模型在学习移除不安全视觉概念的同时,保留无关特征。此外,我们还引入了一个 输出保持正则化项 ,以维持模型在安全内容上的生成能力。
大量实验表明,DUO能够有效防御各种先进的红队攻击方法,并且在无关主题上的性能损失并不显著(以FID和CLIP分数衡量)。我们的工作有助于开发更安全、更可靠的 T2I 模型,为在闭源和开源场景中负责任地部署这些模型铺平道路。

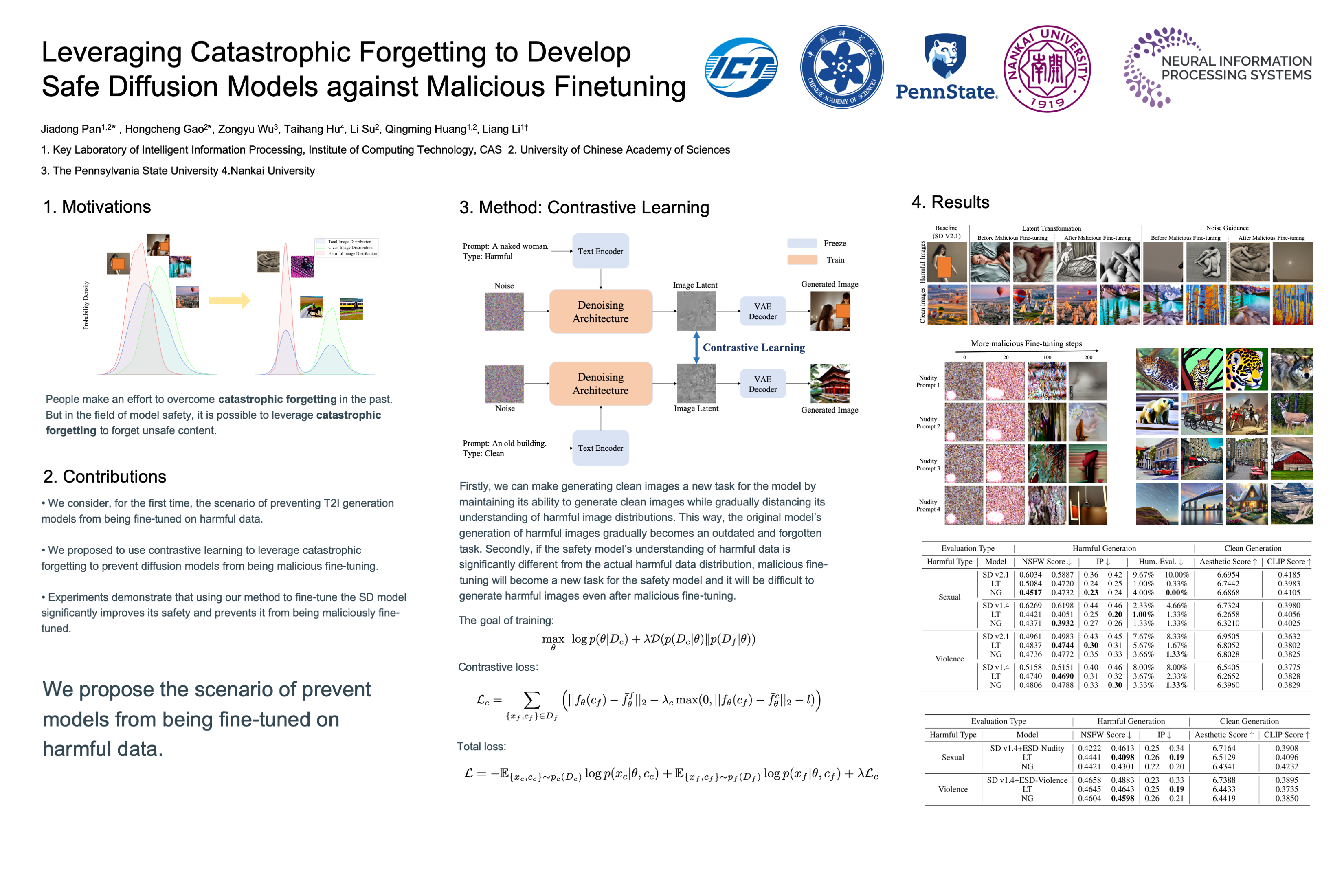
Leveraging Catastrophic Forgetting
Leveraging Catastrophic Forgetting to Develop Safe Diffusion Models against Malicious Finetuning
- pdf: https://openreview.net/pdf?id=pR37AmwbOt
- openreview: https://openreview.net/forum?id=pR37AmwbOt
- poster: https://nips.cc/virtual/2024/poster/93554
- idea: 利用灾难性遗忘开发安全扩散模型以抵御恶意微调
扩散模型 (DM) 在基于文本提示的图像生成方面表现出显著的能力。人们提出了许多方法来确保这些模型生成安全的图像。
早期的方法试图将安全过滤器纳入模型,以减少产生有害图像的风险,但这种外部过滤器本身并不能解除模型的毒性,可以很容易地绕过。因此,考虑到 模型Unlearn 和 数据清洗 对模型参数的影响,它们是维护模型安全的最基本的方法。然而,即使使用这些方法,恶意的微调仍然会使模型倾向于生成有害或不良的图像。
受灾难性遗忘现象的启发,我们提出了一种使用 对比学习 的训练策略,以 增加清洁和有害数据分布之间的潜在空间距离,从而保护模型不被微调以生成由于遗忘引起的有害图像。
实验结果表明,我们的方法不仅在恶意微调之前保持了清晰的图像生成能力,而且在恶意微调之后有效地防止了 DM 产生有害的图像。 我们的方法还可以与其他安全方法相结合,以进一步保持其安全性,防止恶意微调。
Memory/Concept Location

Finding NeMo
Finding NeMo: Localizing Neurons Responsible For Memorization in Diffusion Models
- pdf: https://arxiv.org/pdf/2406.02366
- project page: https://ml-research.github.io/localizing_memorization_in_diffusion_models/
- code: https://github.com/ml-research/localizing_memorization_in_diffusion_models
- poster: https://nips.cc/virtual/2024/poster/94713
扩散模型(DMs)产生非常详细和高质量的图像。他们的能力来自于对大量数据的广泛训练——这些数据通常是从互联网上抓取的,没有适当的归属或内容创作者的同意。不幸的是,这种做法引起了隐私和知识产权问题,因为DMs可以记住并在推理时再现其潜在的敏感或受版权保护的训练图像。
之前的努力通过改变扩散过程的输入来防止这个问题,从而防止DM在推理过程中生成记忆的样本,或者从训练中完全删除记忆的数据。虽然当DMs被开发和部署在一个安全且持续监控的环境中时,这些解决方案是可行的,但它们存在攻击者规避保护措施的风险,并且当DMs本身被公开发布时,这些解决方案是无效的。
为了解决这个问题,我们引入了 NeMo,这是 第一种将单个数据样本的记忆定位到DMs的交叉注意层神经元水平的方法。
通过我们的实验,我们发现在许多情况下,单个神经元负责记忆特定的训练样本。通过停用这些记忆神经元,我们可以避免在推理时重复训练数据,增加生成输出的多样性,并减轻私有和版权数据的泄漏。 通过这种方式,我们的NEMO有助于更负责任的部署DMs。
- Privacy/Copyright issue
- Data-Sample-Level Memory
- 2 kind of Memory:
- Verbatim Memory(VM):逐字记忆,神经元记忆整个训练样本。
- Template Memory(TM):模板记忆,神经元记忆训练样本的主体构成。
- 基于:MIA的启发,扩散模型对记忆样本和非记忆样本的相应不同。
- 对于记忆的样本,模型预测的initial nosie(根据
预测的 )趋向一致,与seed无关。 => 即预测噪声之于seed的分布是一致且平缓的。 - 对于非记忆的样本,模型预测的initial nosie更加多样,分布更加陡峭。
- 对于记忆的样本,模型预测的initial nosie(根据
- 方法:随机停用(先随机停用layer筛选出可能的layer,然后对可能的layer随机停用神经元,筛选出可能的memory neuron)
- most training data samples are memorized by just a few or even a single neuron.
P-ESD/P-AC [SGAW Wrokshop]
Pruning for Robust Concept Erasing in Diffusion Models
poster in workshop: https://neurips.cc/virtual/2024/106210
openreview(8-5-8): https://openreview.net/forum?id=jD1eWpUMOf
我们引入了一个简单而有效的 基于剪枝的概念擦除框架。
通过 将概念擦除和剪枝集成到一个目标中 ,我们的方法有效地消除了模型中的概念知识,同时切断了可能重新激活概念相关隐藏状态的路径,确保了 对抗性提示的稳健性。
实验结果表明,我们的模型对对抗性攻击的抵御能力得到了显著增强。与现有的概念擦除方法相比,我们的方法在 NSFW 内容和艺术作品风格的擦除方面取得了约 30% 的提升。NSFW/Copyright issue
Concept-Level Memory
Background: fine-tuning-based erasing is vulnerable to adversarial attacks !
- Existing erasing methods fine-tune parameters to “deactivate” such neurons to achieve removal in training data. However, these neurons might be “reactivated” when inputs are cleverly designed(对擦除概念很重要的神经元对明确设计的对抗性提示很敏 感。因此,它们可以被”重新激活”以重新生成要删除的概念。)
Hypothesis: the generation of a specific concept is correlated with a subset of neurons in diffusion models, which we refer to as concept neurons in this paper
- the generation of a specific concept is correlated with a subset of neurons in diffusion models, which we refer to as
concept neuronsin this paper
- the generation of a specific concept is correlated with a subset of neurons in diffusion models, which we refer to as
基于:神经元的激活程度与概念的生成相关。
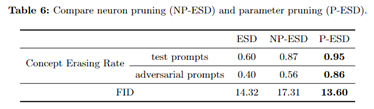
设计了两种方法:
- NP-ESD (直接剪除变化最大的top1神经元;擦除效果差,干扰大)(只能说明这些是构成该concept的重要神经元,但是不能说明是区别于其他concept的关键神经元)
- P-ESD (hard掩码优化;擦除更好,干扰更小)
- Title: Paper Collection of Safe Diffusion at NeurIPS 2024
- Author: LeoJeshua
- Created at : 2024-09-26 15:49:09
- Updated at : 2025-11-19 12:36:49
- Link: https://leojeshua.github.io/DMs/Paper-Collection-of-Safe-Diffusion_NeurIPS-2024/
- License: This work is licensed under CC BY-NC-SA 4.0.