classifier = pipeline("zero-shot-classification") classifier( "This is a course about the Transformers library", candidate_labels=["education", "politics", "business"], )
1 2 3
>>> {'sequence': 'This is a course about the Transformers library', 'labels': ['education', 'business', 'politics'], 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
Text Gengeration
1 2 3 4
from transformers import pipeline
generator = pipeline("text-generation") generator("In this course, we will teach you how to")
1 2 3 4 5
>>> [{'generated_text': 'In this course, we will teach you how to understand and use ' 'data flow and data interchange when handling user data. We ' 'will be working with one or more of the most commonly used ' 'data flows — data flows of various types, as seen by the ' 'HTTP'}]
Named Entity Recognition (NER)
Return the words representing persons, organizations or locations.
1 2 3 4
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True) ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
unmasker = pipeline("fill-mask") unmasker("This course will teach you all about <mask> models.", top_k=2)
1 2 3 4 5 6 7 8
>>> [{'sequence': 'This course will teach you all about mathematical models.', 'score': 0.19619831442832947, 'token': 30412, 'token_str': ' mathematical'}, {'sequence': 'This course will teach you all about computational models.', 'score': 0.04052725434303284, 'token': 38163, 'token_str': ' computational'}]
Question Answering
1 2 3 4 5 6 7
from transformers import pipeline
question_answerer = pipeline("question-answering") question_answerer( question="Where do I work?", context="My name is Sylvain and I work at Hugging Face in Brooklyn", )
summarizer = pipeline("summarization") summarizer( """ America has changed dramatically during recent years. Not only has the number of graduates in traditional engineering disciplines such as mechanical, civil, electrical, chemical, and aeronautical engineering declined, but in most of the premier American universities engineering curricula now concentrate on and encourage largely the study of engineering science. As a result, there are declining offerings in engineering subjects dealing with infrastructure, the environment, and related issues, and greater concentration on high technology subjects, largely supporting increasingly complex scientific developments. While the latter is important, it should not be at the expense of more traditional engineering. Rapidly developing economies such as China and India, as well as other industrial countries in Europe and Asia, continue to encourage and advance the teaching of engineering. Both China and India, respectively, graduate six and eight times as many traditional engineers as does the United States. Other industrial countries at minimum maintain their output, while America suffers an increasingly serious decline in the number of engineering graduates and a lack of well-educated engineers. """ )
1 2 3 4 5 6 7
>>> [{'summary_text': ' America has changed dramatically during recent years . The ' 'number of engineering graduates in the U.S. has declined in ' 'traditional engineering disciplines such as mechanical, civil ' ', electrical, chemical, and aeronautical engineering . Rapidly ' 'developing economies such as China and India, as well as other ' 'industrial countries in Europe and Asia, continue to encourage ' 'and advance engineering .'}]
Translation
1 2 3 4
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en") translator("Ce cours est produit par Hugging Face.")
1
>>> [{'translation_text': 'This course is produced by Hugging Face.'}]
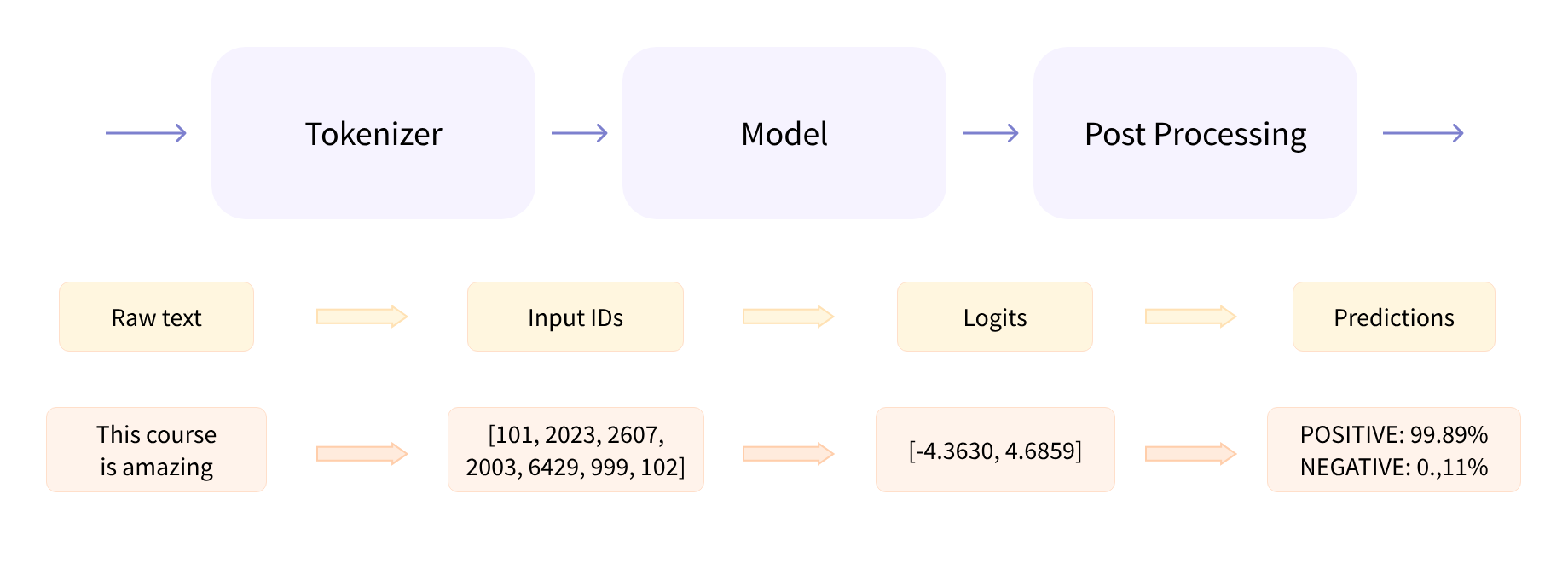
1.3 Transformers架构
We discussed how Transformer models work at a high level, and talked about the importance of transfer learning and fine-tuning.
A key aspect is that you can use the full architecture or only the encoder or only the decoder, depending on what kind of task you aim to solve. The following table summarizes this:
Model
Examples
Tasks
Encoder
ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa
Sentence classification, named entity recognition, extractive question answering